HDFS【Namenode、SecondaryNamenode、Datanode】
一. NameNode和SecondaryNameNode
1.NN和2NN 工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage.
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
NameNode工作机制
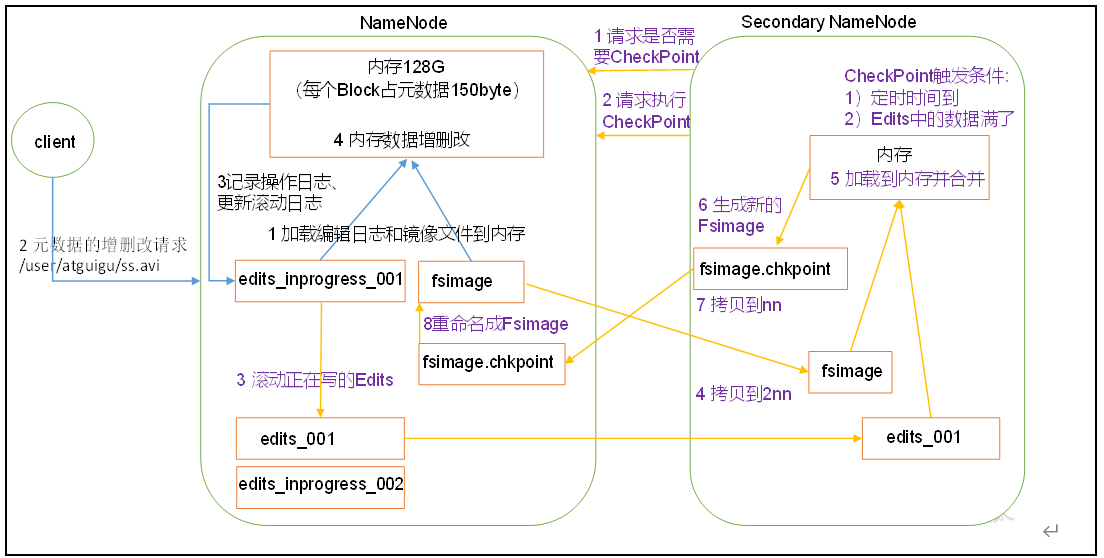
- 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
- 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
2. NN和2NN中的fsimage、edits分析
fsimage、edits概念

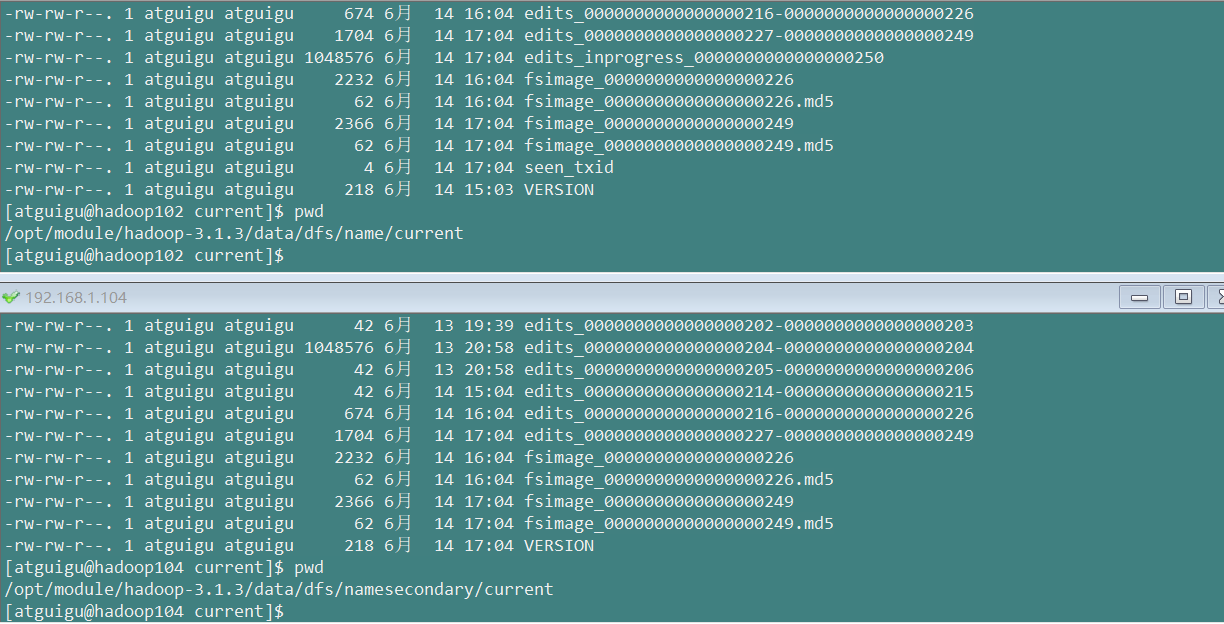
查看fsimage,edits
namenode和datanode上的对比
文件对比
oiv查看Fsimage文件
hdfs oiv -p 文件类型 -i fsimage文件 -o 转换后文件输出路径
[hadoop@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/tmp/dfs/name/current
[hadoop@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[hadoop@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml
下载xml文件到本地,sublime工具打开
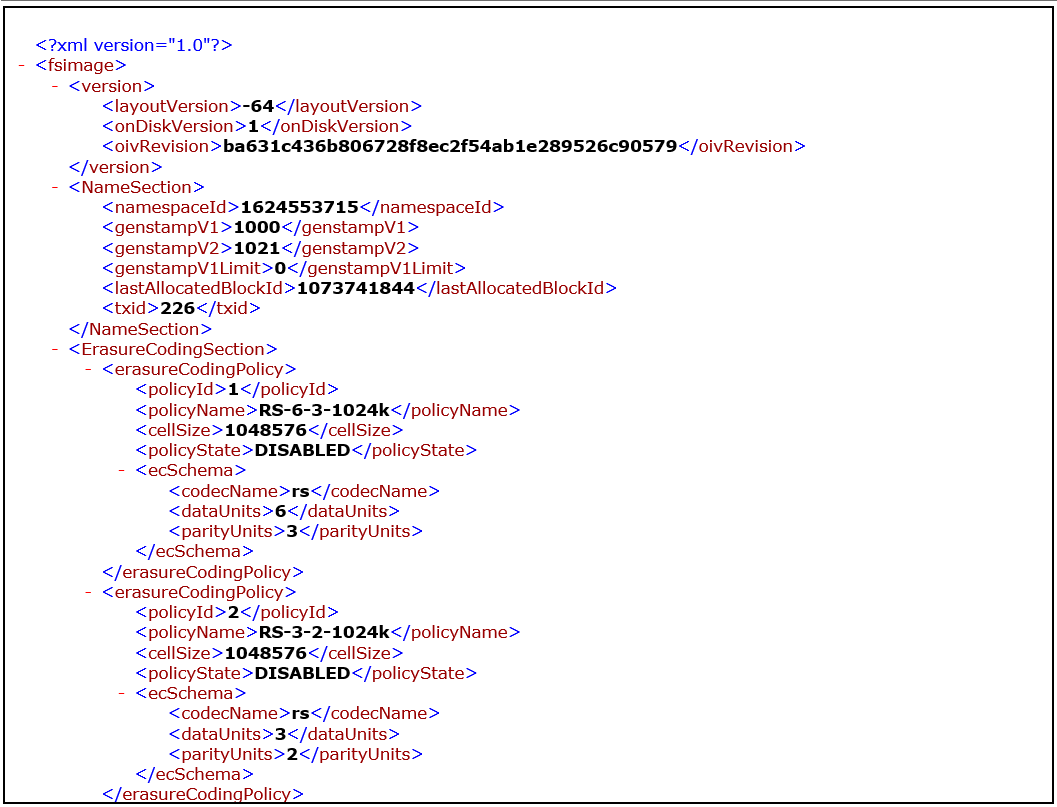
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报;namenote中fsimage没有block的备份信息,每次启动datanode会主动上报block信息,然后加载进namebote内存,所以fsimage中没有block的备份信息
oev查看Edits文件
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
[atguigu@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml
下载xml文件到本地,sublime工具打开
3.checkpoint设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
【hdfs-default.xml】
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,3当操作次数达到1百万时,SecondaryNameNode执行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
4.namenode故障恢复(基本不用)
会丢失edits-progerss.log,一般采用HA
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
5.集群安全模式
只能查看,不能put,get等操作

二. Datanode
1.工作机制
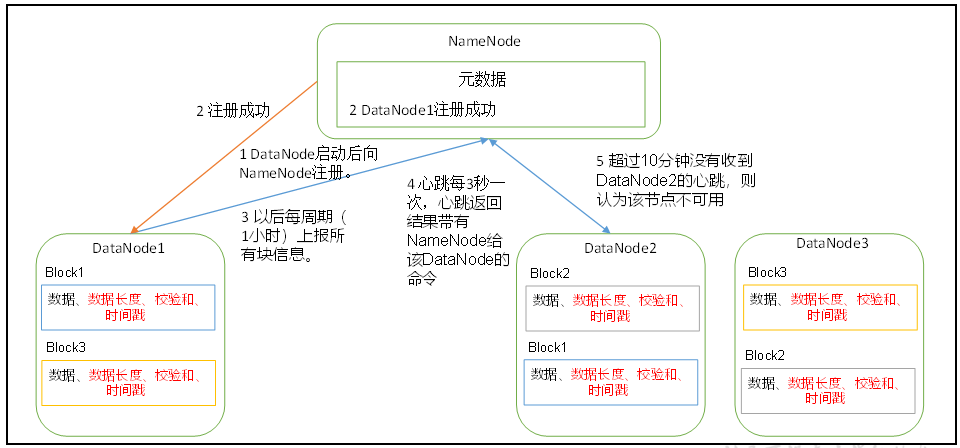
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
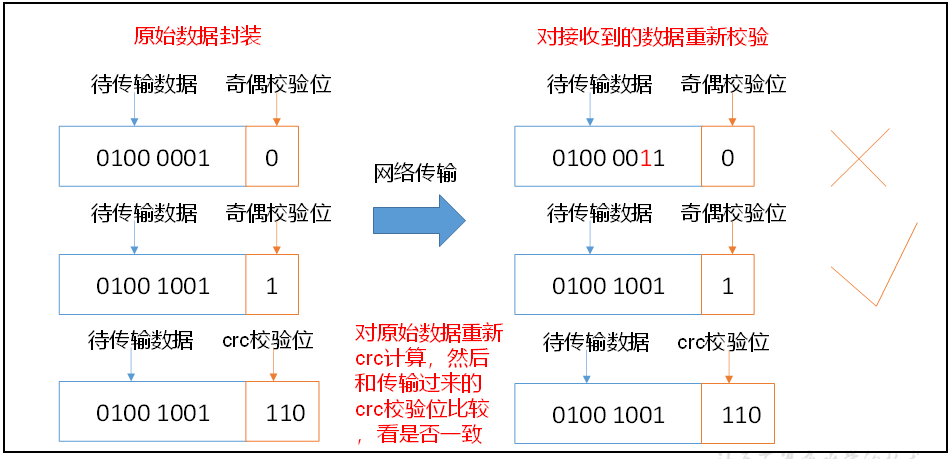
2.数据校验
DataNode节点保证数据完整性
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)DataNode在其文件创建后周期验证CheckSum。
3.掉线参数配置
机制
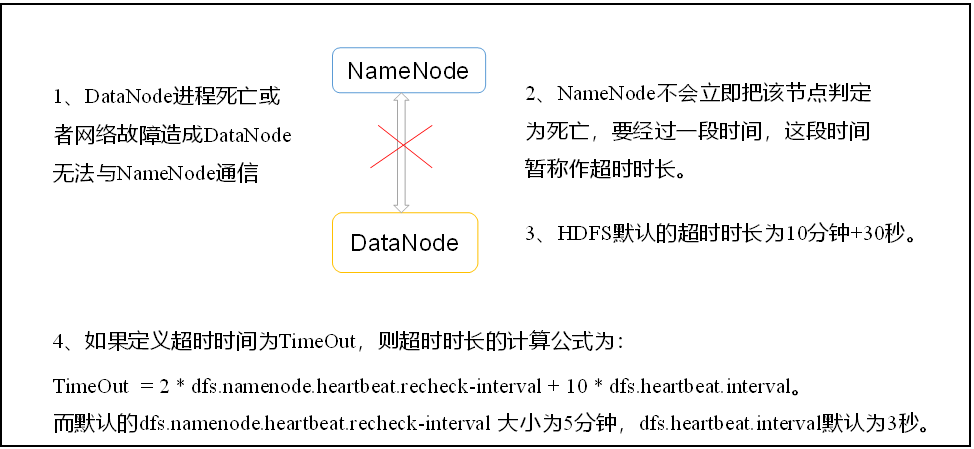
配置
修改hdfs-site.xml ,配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
4.增加Datanode节点
将新节点配置好java、hadoop环境,后直接启动datanode,该节点会主动向namenode进行注册
注意:hadoop中的workers文件中的配置节点能够通过集群命令start-dfs.sh群起, 新增节点需单独启动
1. 新节点配置
(1)在hadoop104主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称(重启)
(3)删除hadoop105上HDFS文件系统留存的文件(/opt/module/hadoop-3.1.3/data和log)
(4)source一下配置文件
[hadoop@hadoop105 hadoop-3.1.3]$ source /etc/profile
2. 启动hadoop105的DataNode和NodeManager
直接启动DataNode,即可关联到集群
[hadoop@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[hadoop@hadoop105 hadoop-3.1.3]$ sbin/yarn-daemon.sh start nodemanager

(3)在新节点上传文件
[hadoop@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /
2020-06-15 18:11:55,559 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false

(4)如果数据不平衡,可以实现节点集群数据再平衡
[hadoop@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
5.删除datanode节点
添加白名单
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出
(1)在NameNode的/opt/module/hadoop-3.1.3/etc/hadoop目录下创建dfs.hosts文件,添加主机名
[hadoop@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop
[hadoop@hadoop102 hadoop]$ touch dfs.hosts
[hadoop@hadoop102 hadoop]$ vi dfs.hosts
[hadoop@hadoop102 hadoop]$vim dfs.hosts
hadoop102
hadoop103
hadoop104
(2)在NameNode节点的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/dfs.hosts</value>
</property>
(3)配置文件分发
[hadoop@hadoop102 hadoop]$ xsync hdfs-site.xml
(4)刷新NameNode节点、ResourceManager节点
[hadoop@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[hadoop@hadoop102 hadoop-3.1.3]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(5)查看web页面
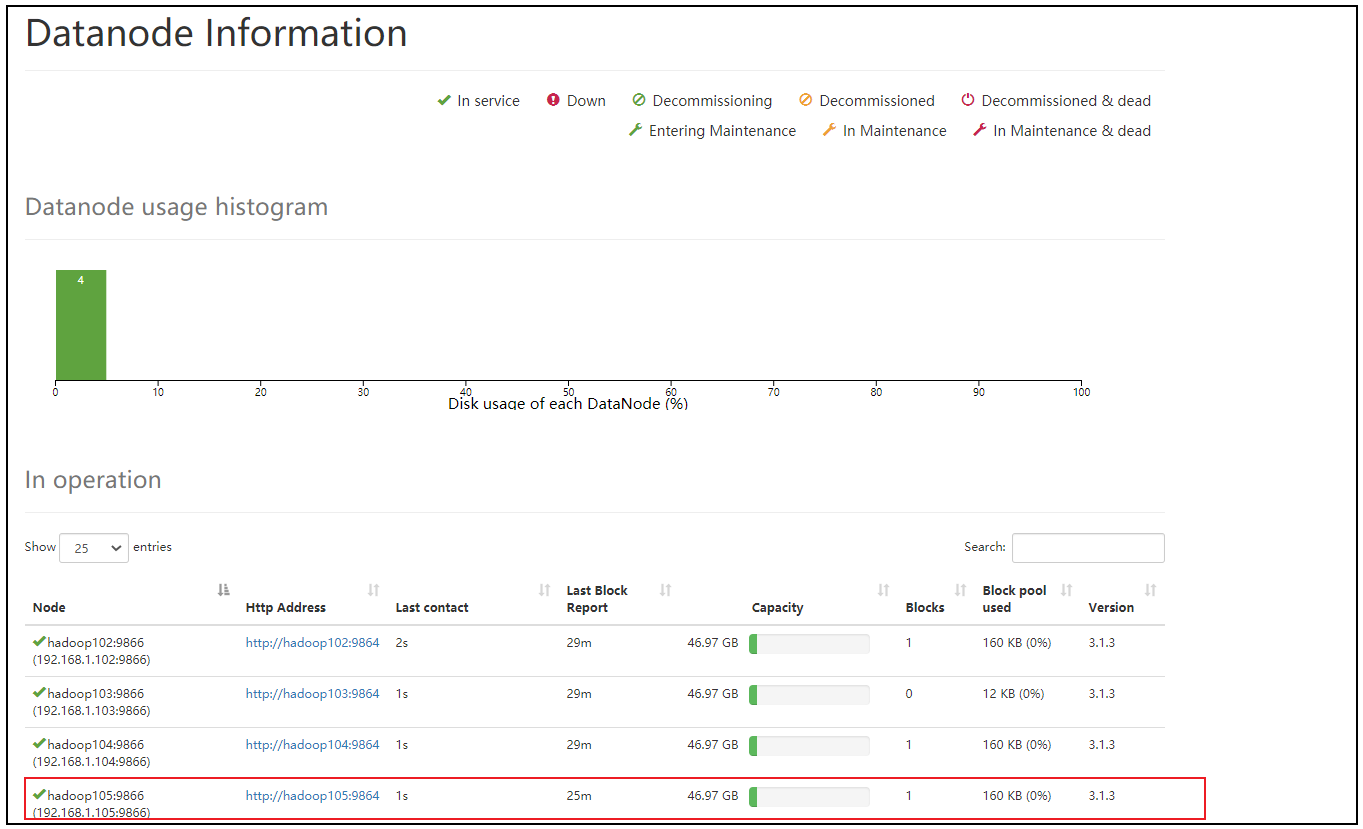
(6)如果数据不均衡,可以用命令实现集群的再平衡
[hadoop@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
黑名单退役
在黑名单上面的主机都会被强制退出
(1)在NameNode节点/opt/module/hadoop-3.1.3/etc/hadoop下创建dfs.hosts.exclude文件,添加主机名
[hadoop@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop
[hadoop@hadoop102 hadoop]$ touch dfs.hosts.exclude
[hadoop@hadoop102 hadoop]$ vi dfs.hosts.exclude
hadoop105
(2)在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/dfs.hosts.exclude</value>
</property>
(3)刷新NameNode节点、ResourceManager节点
[hadoop@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[hadoop@hadoop102 hadoop-3.1.3]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(4)检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点
(5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。
[hadoop@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode
[hadoop@hadoop105 hadoop-3.1.3]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
(6)如果数据不均衡,可以用命令实现集群的再平衡
[hadoop@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
注意:
a)如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
b)不允许白名单和黑名单中同时出现同一个主机名称
6.多目录配置
- DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
- 具体配置如下,在hdfs-site.xml增加以下内容
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
HDFS【Namenode、SecondaryNamenode、Datanode】的更多相关文章
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- 格式化hdfs后,hadoop集群启动hdfs,namenode启动成功,datanode未启动
集群格式化hdfs后,在主节点运行启动hdfs后,发现namenode启动了,而datanode没有启动,在其他节点上jps后没有datanode进程!原因: 当我们使用hdfs namenode - ...
- HDFS的NameNode与SecondaryNameNode的工作原理
原文:https://blog.51cto.com/xpleaf/2147375 看完之后确实对nameNode的工作更加清晰一些 在Hadoop中,有一些命名不好的模块,Secondary Name ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- hdfs、tfs、fastdfs、Tachyon
hdfs 架构设计 HDFS按照Master和Slave的结构.分NameNode.SecondaryNameNode.DataNode这几个角色. NameNode:是Master节点,是管理者.. ...
- NameNode内存溢出和DataNode请求超时异常处理
问题背景 春节假期间,接连收到监控程序发出的数据异常问题,赶忙连接上跳板机检查各服务间的状态,发现Datanode在第二台.第三台从节点都掉线了,通过查看Datanode和Namenode运行日志,发 ...
- 教你成为全栈工程师(Full Stack Developer) 四十五-一文读懂hadoop、hbase、hive、spark分布式系统架构
转载自http://www.shareditor.com/blogshow?blogId=96 机器学习.数据挖掘等各种大数据处理都离不开各种开源分布式系统,hadoop用于分布式存储和map-red ...
- Linux下的ssh、scala、spark配置
注:笔记旨在记录,配置方式每个人多少有点不同,但大同小异,以下是个人爱好的配置方式. 目录 一.配置jdk 二.配置ssh 三.配置hadoop 四.配置scala 五.配置spark 平台:win1 ...
- 【大数据系列】HDFS文件权限和安全模式、安装
HDFS文件权限 1.与linux文件权限类型 r:read w:write x:execute权限x对于文件忽略,对于文件夹表示是否允许访问其内容 2.如果linux系统用户sanglp使用hado ...
随机推荐
- pycharm基本使用python的注释语法
pychram基本使用 1.主题选择 file settings Editor color Scheme 2.pycharm切换解释器 file settings Project Python Int ...
- (一)lamp 环境搭建之编译安装apache
apache的编译安装: 安装步骤大概参考:http://www.cnblogs.com/iyoule/archive/2013/10/24/3385540.html 简单的将分为三步: (1)安装a ...
- SQL告警,执行时间长?教你写一手好 SQL !
博主(编码砖家)负责的项目主要采用阿里云数据库MySQL,最近频繁出现慢SQL告警,执行时间最长的竟然高达5分钟.导出日志后分析,主要原因竟然是没有命中索引和没有分页处理 . 其实这是非常低级的错误, ...
- [linux]centos7.4安装nginx
下载nginx wget http://nginx.org/download/nginx-1.5.6.tar.gz 解压包安装在/opt/nginx. 目录下, 1.安装gcc(centos 7之后一 ...
- 关于JDBC中查询方法的抽取
萌新的JAVA学习笔记[1] 先来张伊蕾娜镇场~~ 简单描述 起初我们的查询方法时分为单个查询和全部查询,过于局限与繁琐,如此一来我们能不能想一个办法将所有类型的查询抽取出来并整合成为一个单独的工具方 ...
- java更开源-安全可靠国产系统背景下的应有.NET Core的一席之地
"安可"背景下的中国软件开发 在中美当前背景下的安全可靠国产系统(简称安可),安可产业要实现技术自主可控,需要在四个层面逐步实现:基础硬件设施,如芯片.服务器.存储.交换机.路由器 ...
- Windows应用开发中程序窗口中的各种图标尺寸规划
为了让你的图标在各个视图模式下都能有合适的尺寸,需要制作4种尺寸16x16.32x32.48x48.256x256 在Windows系统中,几乎所有窗口都是ListView,其中的图标都按照指定的尺寸 ...
- Python基础(序列化)
#pickling import pickle,json # d = dict(name='傻狗1',age=300,score=100) # d1 = pickle.dumps(d)#pickle. ...
- python递归三战:Sierpinski Triangle、Tower of Hanoi、Maze Exploring
本文已做成视频教程投稿b站(视频版相对文本版有一些改进),点击观看视频教程 本文主要通过三个实例来帮助大家理解递归(其展示动画已上传B站): 谢尔宾斯基三角形(Sierpinski Triangle) ...
- centos7.6自动化安装mysql5.5
一.目的 简化安装mysql的安装过程,局限很大,仅支持centos7.6上安装mysql5.5.60,如果想在其他版本的操作系统安装mysql,请自行修改有关变量. 如果想了解mysql安装的具体过 ...