3. scala-spark wordCount 案例
1. 创建maven 工程
2. 相关依赖和插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>wordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<mainClass>wordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3. wordCount 案例
package com.atgu.bigdata.spark
import org.apache.spark._
import org.apache.spark.rdd.RDD
object wordCount extends App {
// local模式
// 1.创建sparkConf 对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount")
// 2. 创建spark 上下文对象
val sc:SparkContext=new SparkContext(config = conf)
// 3. 读取文件
val lines: RDD[String] = sc.textFile("file:///opt/data/1.txt")
// 4. 切割单词
val words: RDD[String] = lines.flatMap(_.split(" "))
// words.collect().foreach(println)
// map
private val keycounts: RDD[(String, Int)] = words.map((_, 1))
//
private val results: RDD[(String, Int)] = keycounts.reduceByKey(_ + _)
private val res: Array[(String, Int)] = results.collect
res.foreach(println) }
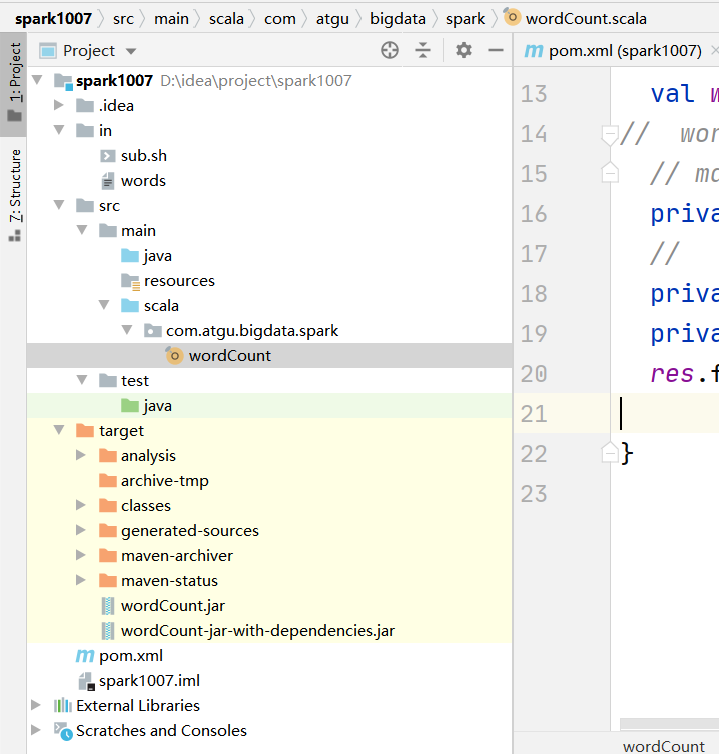
4. 项目目录结构
3. scala-spark wordCount 案例的更多相关文章
- Scala Spark WordCount
Scala所需依赖 <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-l ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- brdd 惰性执行 mapreduce 提取指定类型值 WebUi 作业信息 全局临时视图 pyspark scala spark 安装
[rdd 惰性执行] 为了提高计算效率 spark 采用了哪些机制 1-rdd 基于分布式内存数据集进行运算 2-lazy evaluation :惰性执行,即rdd的变换操作并不是在运行该代码时立 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark Wordcount
1.Wordcount.scala(本地模式) package com.Mars.spark import org.apache.spark.{SparkConf, SparkContext} /** ...
- Spark WordCount的两种方式
Spark WordCount的两种方式. 语言:Java 工具:Idea 项目:Java Maven pom.xml如下: <properties> <spark.version& ...
- 3、spark Wordcount
一.用Java开发wordcount程序 1.开发环境JDK1.6 1.1 配置maven环境 1.2 如何进行本地测试 1.3 如何使用spark-submit提交到spark集群进行执行(spar ...
- indows Eclipse Scala编写WordCount程序
Windows Eclipse Scala编写WordCount程序: 1)无需启动hadoop,因为我们用的是本地文件.先像原来一样,做一个普通的scala项目和Scala Object. 但这里一 ...
- spark wordcount程序
spark wordcount程序 IllegalAccessError错误 这个错误是权限错误,错误的引用方法,比如方法中调用private,protect方法. 当然大家知道wordcount业务 ...
随机推荐
- 【LeetCode】238. Product of Array Except Self 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 解题方法 两次遍历 日期 题目地址:https://leetcode.c ...
- 1686 第K大区间
1686 第K大区间 时间限制:1 秒 空间限制:131072 KB 定义一个区间的值为其众数出现的次数.现给出n个数,求将所有区间的值排序后,第K大的值为多少. 众数(统计学/数学名词)_百度百 ...
- 小程序中使用、H5、uniapp下使用阿里巴巴iconfront图标或者新增图标
第一步:登录iconfont的账号,创建项目. 第二步:选择自己需要的图标,并添加入库(就是那个购物车的图标). 第三步:将选好的图片添加到项目.(点击上图中右上角的购物车图标). 第四步:下载资源到 ...
- CS5218|DP转HDMI4K30HZ方案|CS5218应用方案
Capstone CS5218是一款单端口HDMI/DVI电平移位器/中继器,具有重新定时功能.它支持交流和直流耦合信号高达3.0-Gbps的操作与可编程均衡和抖动清洗.它包括2路双模DP电缆适配器寄 ...
- Linux的基本目录结构
- Android开发 ListView(垂直滚动列表项视图)的简单使用
效果图: 使用方法: 1.在布局文件中加入ListView控件: <?xml version="1.0" encoding="utf-8"?> &l ...
- Jsonschema2pojo从JSON生成Java类(命令行)
1.说明 jsonschema2pojo工具可以从JSON Schema(或示例JSON文件)生成Java类型, 在文章Jsonschema2pojo从JSON生成Java类(Maven) 已经介绍过 ...
- 微信公众号开发--.net core接入
.net进行微信公众号开发的例子好像比较少,这里做个笔记 首先,我们需要让微信能访问到我们的项目,所以要么需要有一个可以部署项目的连接到公网下的服务器,要么可以通过端口转发将请求转发到我们的项目,总之 ...
- Flask_Flask-Mail邮件扩展(十三)
在开发过程中,很多应用程序都需要通过邮件提醒用户,Flask的扩展包Flask-Mail通过包装了Python内置的smtplib包,可以用在Flask程序中发送邮件. Flask-Mail连接到简单 ...
- vue2.0点击其他任何地方隐藏dom
methods: { handleBodyClick(){ if (绿色区域出来了,要判断点击其他地方就要关闭,这样可以避免绿色区域已经关闭还在操作) { let _con = $(目标区域) if ...