3. scala-spark wordCount 案例
1. 创建maven 工程
2. 相关依赖和插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>wordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<mainClass>wordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3. wordCount 案例
package com.atgu.bigdata.spark
import org.apache.spark._
import org.apache.spark.rdd.RDD
object wordCount extends App {
// local模式
// 1.创建sparkConf 对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount")
// 2. 创建spark 上下文对象
val sc:SparkContext=new SparkContext(config = conf)
// 3. 读取文件
val lines: RDD[String] = sc.textFile("file:///opt/data/1.txt")
// 4. 切割单词
val words: RDD[String] = lines.flatMap(_.split(" "))
// words.collect().foreach(println)
// map
private val keycounts: RDD[(String, Int)] = words.map((_, 1))
//
private val results: RDD[(String, Int)] = keycounts.reduceByKey(_ + _)
private val res: Array[(String, Int)] = results.collect
res.foreach(println) }
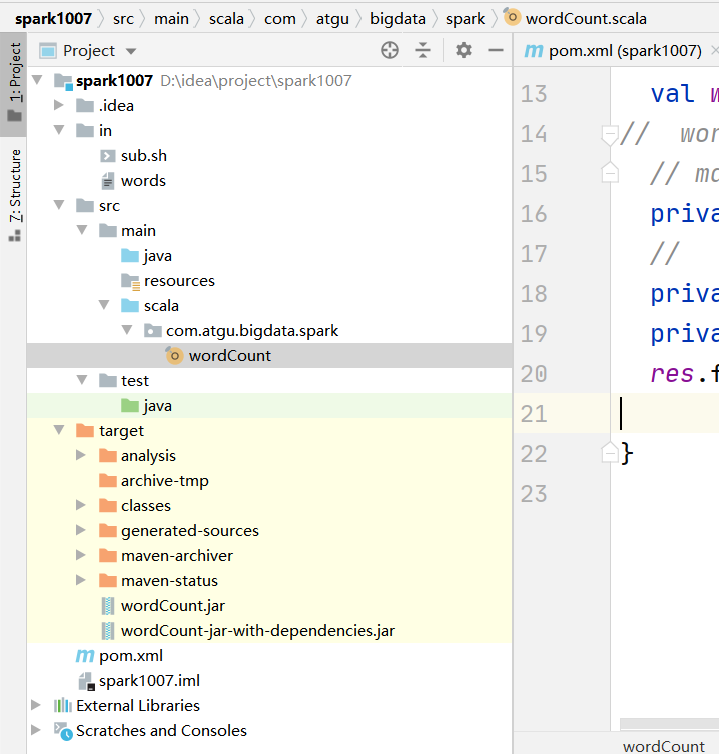
4. 项目目录结构
3. scala-spark wordCount 案例的更多相关文章
- Scala Spark WordCount
Scala所需依赖 <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-l ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- brdd 惰性执行 mapreduce 提取指定类型值 WebUi 作业信息 全局临时视图 pyspark scala spark 安装
[rdd 惰性执行] 为了提高计算效率 spark 采用了哪些机制 1-rdd 基于分布式内存数据集进行运算 2-lazy evaluation :惰性执行,即rdd的变换操作并不是在运行该代码时立 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark Wordcount
1.Wordcount.scala(本地模式) package com.Mars.spark import org.apache.spark.{SparkConf, SparkContext} /** ...
- Spark WordCount的两种方式
Spark WordCount的两种方式. 语言:Java 工具:Idea 项目:Java Maven pom.xml如下: <properties> <spark.version& ...
- 3、spark Wordcount
一.用Java开发wordcount程序 1.开发环境JDK1.6 1.1 配置maven环境 1.2 如何进行本地测试 1.3 如何使用spark-submit提交到spark集群进行执行(spar ...
- indows Eclipse Scala编写WordCount程序
Windows Eclipse Scala编写WordCount程序: 1)无需启动hadoop,因为我们用的是本地文件.先像原来一样,做一个普通的scala项目和Scala Object. 但这里一 ...
- spark wordcount程序
spark wordcount程序 IllegalAccessError错误 这个错误是权限错误,错误的引用方法,比如方法中调用private,protect方法. 当然大家知道wordcount业务 ...
随机推荐
- 教学日志:javaSE-java中的数据类型和运算符
一.java中的标识符 /* 标识符的命名规范: 硬性要求: 1.必须以字母._下划线.美元符$开头 2.其它部分可以是字母.下划线"_".美元符"$"和数字的 ...
- EXCEL技能 | EXCEL中实现地图快照,截大图、加水印、保存PNG、TIF、HTML文件
1 应用场景 本文分享笔者使用EXCEL制作地图的体验. 之前网上有人介绍使用小O地图EXCEL插件版能够在EXCEL中标注地图.绘制地图.可视化数据等操作.如下截图.笔者通过实验,其软件保存方式只能 ...
- Hive SQL优化思路
Hive的优化主要分为:配置优化.SQL语句优化.任务优化等方案.其中在开发过程中主要涉及到的可能是SQL优化这块. 优化的核心思想是: 减少数据量(例如分区.列剪裁) 避免数据倾斜(例如加参数.Ke ...
- Java EE数据持久化框架mybatis练习——获取id值为1的角色信息。
实现要求: 获取id值为1的角色信息. 实现思路: 创建角色表sys_role所对应的实体类sysRole. package entity; public class SysRole { privat ...
- Log4j2日志框架集成Slf4j日志门面
1.说明 本文介绍使用日志门面Slf4j打印日志, 底层日志实现使用Log4j2框架, 方便以后切换底层日志实现, Log4j2可以替换成Logback等. 2.依赖管理 在pom.xml依赖管理中导 ...
- Star Way To Heaven
题目描述 小 x伤心的走上了 Star way to heaven. 到天堂的道路是一个笛卡尔坐标系上一个 n*m的长方形通道 顶点在0,0 和 . 小 n,m 从最左边任意一点进入,从右边任意一点走 ...
- nginx + tomcat 单个域名及多个域名的配置
//nginx + tomcat 单个域名及多个域名的配置//修改nginx的配置文件,linux默认路径 /usr/local/nginx/conf/nginx.conf //prot为8082的w ...
- centos7 安装zabbix3.0 安装zabbix4.0 yum安装zabbix 国内源安装zabbix 阿里云服务器安装zabbix
首先,此篇文章是有原因的. 刚开始也和大家一样来学习安装zabbix 奈何网上的教程和现实出现不一样的情况 在安装zabbix过程中,因为zabbix下载源是在国外,下载途中会出现终止下载的情况 tr ...
- Echart可视化学习(六)
文档的源代码地址,需要的下载就可以了(访问密码:7567) https://url56.ctfile.com/f/34653256-527823386-04154f 柱状图定制 官网找到类似实例, 适 ...
- 小程序canvas绘制纯色圆角区域 setdata数组某一项
小程序canvas绘制纯色圆角区域: //方法: roundRectPath:function(ctx, x, y, w, h, r) { ctx.beginPath(); ctx.moveTo(x ...