Hadoop的高可用搭建
在已经安装完hadoop单机和zookeeper前提下
1.免密钥
ssh-keygen -t rsa
分发秘钥
ssh-copy-id -i master
ssh-copy-id -i node1
ssh-copy-id -i node2
2.修改hadoop配置文件(我在master中修改)
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
我是直接导入文件覆盖
3.同步到其他节点
scp * node1:/usr/local/soft/hadoop-2.7.6/etc/hadoop/
scp * node1:/usr/local/soft/hadoop-2.7.6/etc/hadoop/
4.删除hadoop数据存储目录下的文件 每个节点都需要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
5.启动zookeeper 三台都需要启动
zkServer.sh start
zkServer.sh status
此时一台一个zk的节点
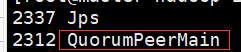
6.启动JN 存储hdfs元数据
三台JN上执行 启动命令: hadoop-daemon.sh start journalnode
此时一台一个zk节点,一个jn日志节点
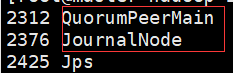
7.格式化 在一台NN上执行
hdfs namenode -format
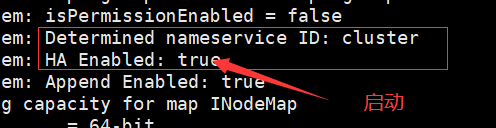
启动当前的NN
hadoop-daemon.sh start namenode
此时master上多了个namenode节点
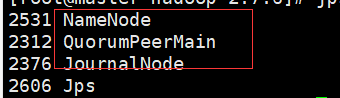
8.执行同步 没有格式化的NN上执行 在另外一个namenode上面执行
hdfs namenode -bootstrapStandby
这是node1上还没有namenode节点很正常,还没有启动hdfs
9.格式化ZK
在已经启动的namenode上面执行 !!一定要先 把zk集群正常 启动起来 hdfs zkfc -formatZK
10.启动hdfs集群,在启动了namenode的节点上执行
start-dfs.sh
master上:

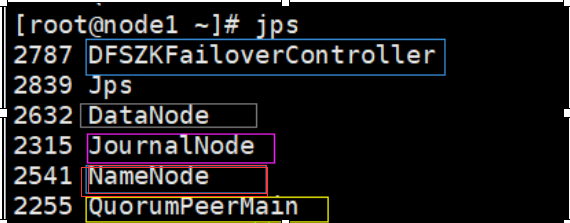
node1上:
node2上:
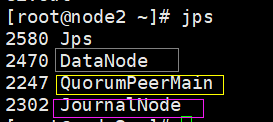
黄色:QuorumPeerMain:zk的节点,三台都有 3个
粉色:JournalNode:jn日志节点,三台都头 3个
红色:Namenode:管理节点:出现在master和node1上 2个
蓝色:DFSZKFailoverController:ZKFC:用来观察master和node1,防止宕机时可以替代 2个
灰色:DataNode:工作节点,用于存储hdfs数据,出现在node1和node2上 2个
一共12个节点此时
11.启动yarn 在master启动
start-yarn.sh
master:多了一个ResourceManager节点,用于处理整个集群资源的总节点
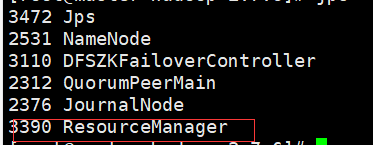
node1和node2上:多个NodeManger节点,用于跟踪监视资源
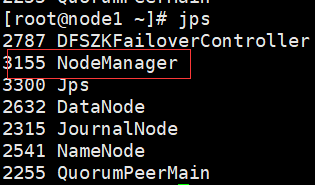
此时多了一个ResourceManager节点和2个NodeManager节点
12.在另外一台主节点上启动RM
yarn-daemon.sh start resourcemanager
此时node1上:多个一个nNodeManager节点,用于备份
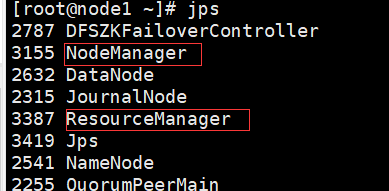
此时node1多了个 ResourceManager节点
Hadoop的高可用搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- Hadoop HA(高可用) 详细安装步骤
什么是HA? HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用.(简言之,有两台机器 ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
- Hadoop完全高可用集群安装
架构图(HA模型没有SNN节点) 用vm规划了8台机器,用到了7台,SNN节点没用 NN DN SN ZKFC ZK JNN RM NM node1 * * node2 * ...
随机推荐
- 活久见!TCP两次挥手,你见过吗?那四次握手呢?
活久见!TCP两次挥手,你见过吗?那四次握手呢? 文章持续更新,可以微信搜一搜「小白debug」第一时间阅读,回复[教程]获golang免费视频教程.本文已经收录在GitHub https://git ...
- Pikachu-暴力破解模块
一.概述 "暴力破解"是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取. 其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果. 为 ...
- one_gadget的一些姿势
概要 one_gadget是libc中存在的一些执行execve("/bin/sh", NULL, NULL)的片段,当可以泄露libc地址,并且可以知道libc版本的时候,可以使 ...
- 保护亿万数据安全,Spring有“声明式事务”绝招
摘要:点外卖时,你只需考虑如何拼单:选择出行时,你只用想好目的地:手机支付时,你只需要保证余额充足.但你不知道这些智能的背后,是数以亿计的强大数据的支持,这就是数据库的力量.那么庞大数据的背后一定会牵 ...
- C语言 使用char字符实现汉字处理
系统:windows 64 编译器:gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 文本编辑器:notepa ...
- C# 二维码生成 ( QRCoder )
二维码1.前言seaconch 最近在搞二维码方面的一些东西,所以接触了一些二维码相关,那么既然用过了就要有用过了的样子 其实关于二维码的文章真的多的数不胜数,有很多写的很认真,很好,但这就像是学习一 ...
- tomcat Debug 启动
eclipse有web工程,将打包为war包(export -> War file) 将打包好的war 包放在tomcat 的webapps下面: 配置debug: 参考来自 http://bl ...
- 微信小程序学习笔记二 列表渲染 + 条件渲染
1. 列表渲染 1.1 wx:for 在组件上使用wx:for控制属性绑定一个数组, 即可使用数组中各项的数据重复渲染该组件 默认数组的当前项的下标变量名默认为 index, 数组当前项的变量名默认为 ...
- Linux centos 安装 jenkins & 本地构建jar & 远程构建jar
一.部署 jenkins 需要的前奏 1.安装 JDK:https://www.cnblogs.com/chuyi-/p/10644440.html 2.安装tomcat:https://www.cn ...
- Go初始化二维数组
初始化二维数组 var a = make([][]int, n) for i := 0; i < n; i++ { a[i] = make([]int, n) }