python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 9:58
# @Author : 秋泊酱
# @File : 获取豆瓣电影第一页
# @Project : 爬虫案例 # get请求
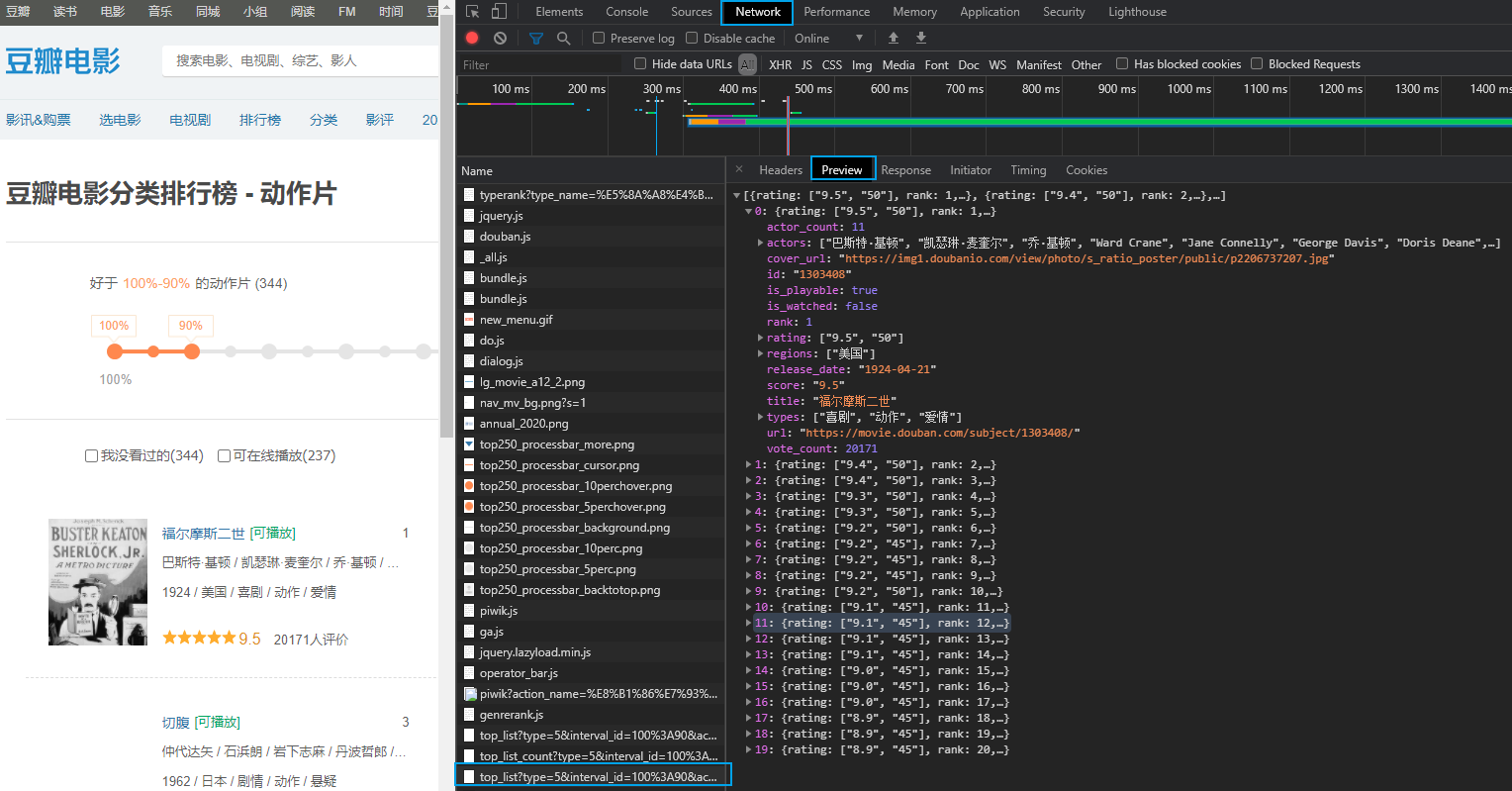
# 获取豆瓣电影的第一页的数据,并且保存到本地 import urllib.request
# 请求路径
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20' # 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
} # (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers) # (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8') # (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content) with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
文件对象.readline() 方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符
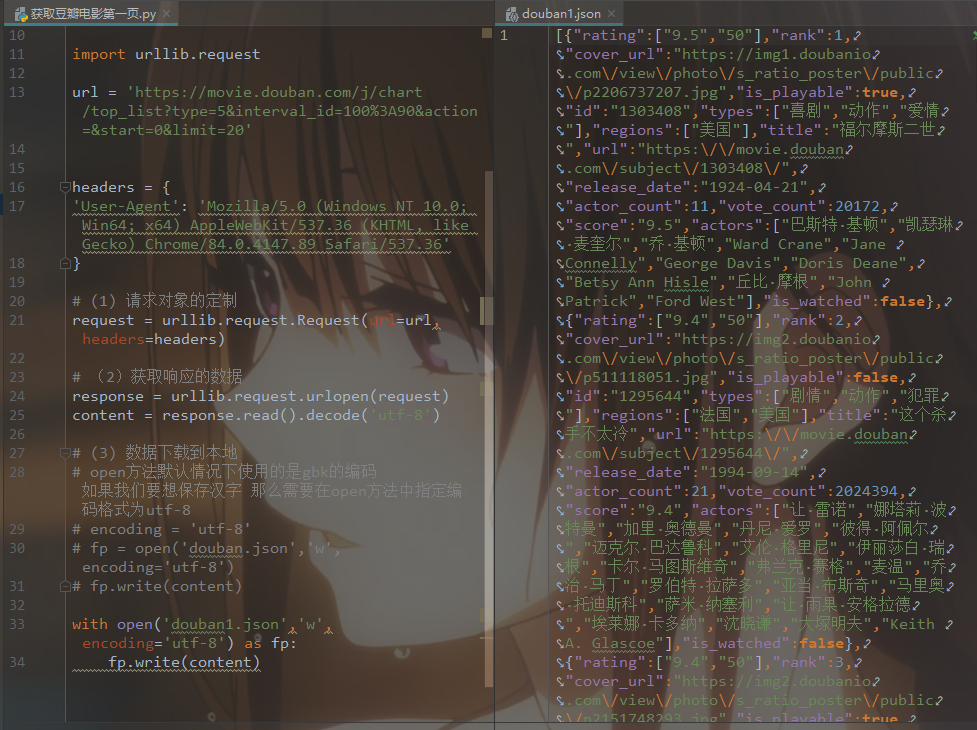
文件读写时有可能产生IOError,一旦出错,后面的file.close()就不会调用。
file = open("test.txt", "r", encoding='UTF-8')
for line in file.readlines():
print (line)
file.close()
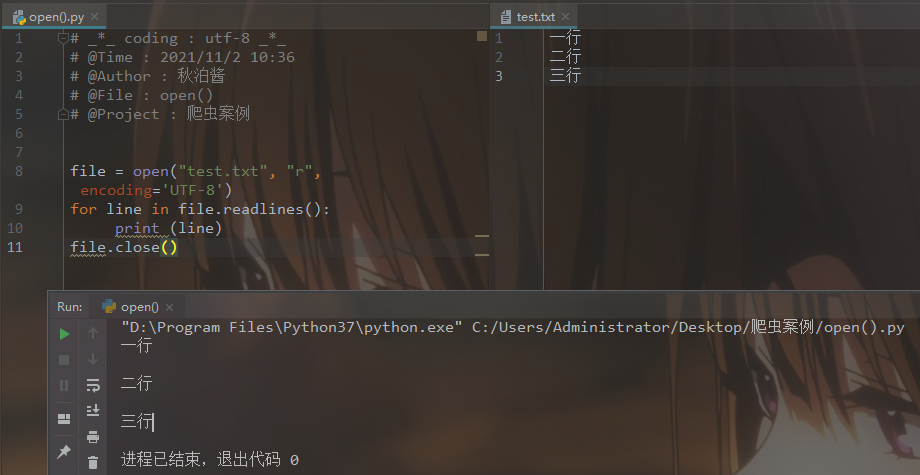
所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try: ...except: ... finally: ... 捕捉异常、处理异常来实现。
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 10:58
# @Author : 秋泊酱
# @File : 无法关闭
# @Project : 爬虫案例 file= open("../test.txt","r")
try:
for line in file.readlines():
print(line)
except:
print("error") # finally 语句无论是否发生异常都将执行最后的代码
finally:
file.close()
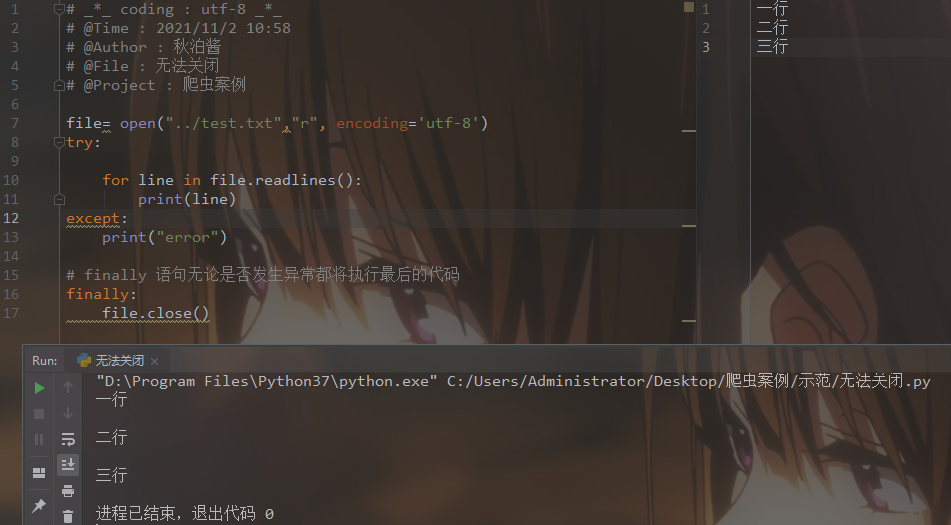
每次都这么写,太繁琐。
with open()as 会在语句结束自动关闭文件,即便出现异常
语法:
with open(文件名, 模式) as 文件对象:
文件对象.方法()
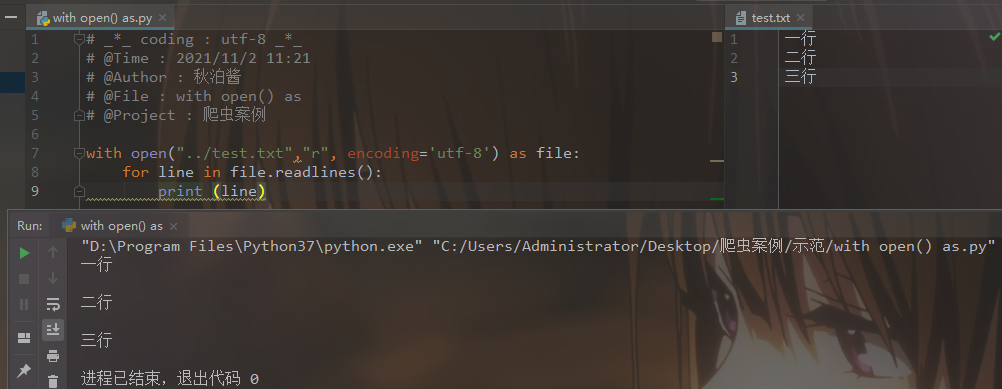
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 11:21
# @Author : 秋泊酱
# @File : with open() as
# @Project : 爬虫案例 with open("../test.txt","r", encoding='utf-8') as file:
for line in file.readlines():
print (line)
python爬取豆瓣电影第一页数据and使用with open() as读写文件的更多相关文章
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
随机推荐
- Javascript设计模式之原型模式、发布订阅模式
原型模式 原型模式用于在创建对象时,通过共享某个对象原型的属性和方法,从而达到提高性能.降低内存占用.代码复用的效果. 示例一 function Person(name) { this.name = ...
- 关于docker复现vulhub环境的搭建
原本想用docker复现一下vul的漏洞. 装docker过程中遇到了很多问题, 昨天熬夜到凌晨三点都没弄完. 中午又找了找原因,终于全部解决了, 小结一下. 0x01 镜像 去官方下载了centos ...
- Azure Devops实践(5)- 构建springboot项目打包docker镜像及容器化部署
使用Azure Devops构建java springboot项目,创建镜像并容器化部署 1.创建一个springboot项目,我用现有的项目 目录结构如下,使用provider项目 在根目录下添加D ...
- PublishFolderCleaner 让你的 dotnet 应用发布文件夹更加整洁
大家都知道,在 dotnet 发布时,将会在输出的 publish 文件夹包含所需的依赖.在 .NET Core 开始,引入了 AppHost 的概念,即使是单个程序集,也需要独立的 Exe 可执行文 ...
- 更好的 java 重试框架 sisyphus 背后的故事
sisyphus 综合了 spring-retry 和 gauva-retrying 的优势,使用起来也非常灵活. 今天,让我们一起看一下西西弗斯背后的故事. 情景导入 简单的需求 产品经理:实现一个 ...
- struts2漏洞复现分析合集
struts2漏洞复现合集 环境准备 tomcat安装 漏洞代码取自vulhub,使用idea进行远程调试 struts2远程调试 catalina.bat jpda start 开启debug模式, ...
- HCNP Routing&Switching之BGP防环机制和路由聚合
前文我们了解了BGP路由宣告相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15440860.html:今天我们来聊一聊BGP防环机制和路由聚合相关话题 ...
- [Beta]the Agiles Scrum Meeting 8
会议时间:2020.5.22 21:00 1.每个人的工作 今天已完成的工作 成员 已完成的工作 issue yjy 帮助解决博客评分功能遇到的问题 tq 暂无 wjx 完成批量创建团队项目功能 班级 ...
- OO课第三单元总结
一.梳理JML语言的理论基础 (1)理论基础 JMl的出现很大程度上一为了行为接口的规范化,用这种语言来指定特定模块的特定功能.JML的核心部分分为三个部分:前置条件(requires).后置条件(e ...
- 关于评论区empty。。。
空荡荡的毫无人烟,博主希望路过的小哥哥/小姐姐(几率较小)留下些什么--