hudi clustering 数据聚集(二)
小文件合并解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
// 生成随机数据100条
val updates = convertToStringList(dataGen.generateInserts(100))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "4").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table").show()
以上示例中,指定了进行 clustering 的触发频率:每4次提交就触发一次,并指定了文件相关大小:生成新文件的最大大小、小文件最小大小。
执行步骤:
1、生成数据,插入数据。
查看当前磁盘上的文件:

查看表内数据个数:
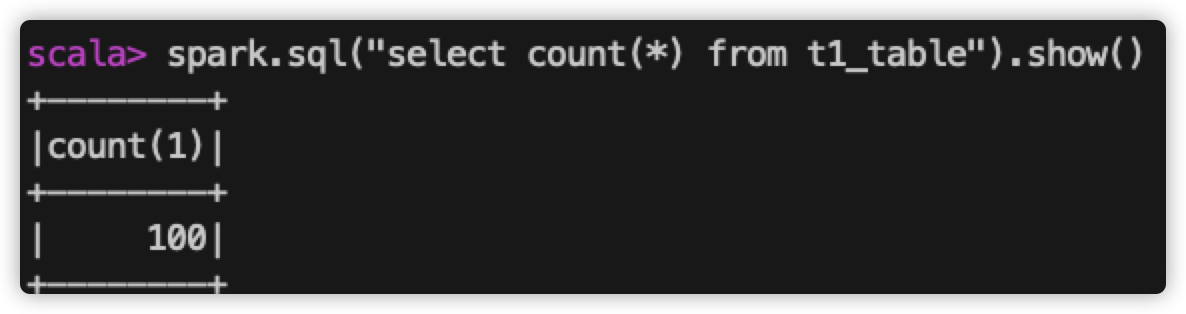
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,当前表中共100条数据,磁盘上生成一个数据文件,在查询该表数据时,只读取了一个文件。
2、重复上面操作两次。
查看当前磁盘上的文件:

查看表内数据个数:
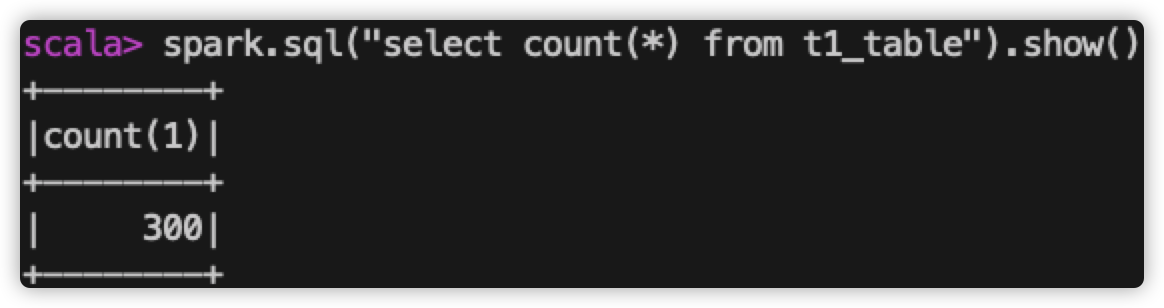
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,目前为止,我们提交了3次写操作,每次生成1个数据文件,共生成了3个数据文件,当查询所有的数据时,需要从3个文件中读取数据。
3、再进行一次数据插入:
查看当前磁盘上的文件:

查看表内数据个数:

查看 spark-web 上 该 sql 执行读取的文件个数:

结论:
1、配置了hoodie.parquet.small.file.limit之后,每次提交新数据,都会生成一个数据文件。
2、在 clustering 之前,每次读取表所有数据的时候,都需要读取所有文件。
3、提交第4次数据之后,触发了 clustering ,生成了一个更大的文件,此时再读取所有数据的时候,就只需要读取合并后的大文件即可。在.hoodie文件夹下,也可以看到 replacecommit 的提交:

小文件合并+sort columns解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
var a = 0;
for (a <- 1 to 8) {
val updates = convertToStringList(dataGen.generateInserts(10000))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "8").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1400000").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "1400000").
// 指定排序的列
option("hoodie.clustering.plan.strategy.sort.columns", "fare").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table where fare > 50").show()
}
执行代码分析
该代码比之前代码修改了几个地方:
1、增加了for循环:
因为我们已经知道了在8次提交之后,小文件会合并大文件,所以一个for循环,做8次提交,我们直接看结果就行。
2、增加了 hoodie.clustering.plan.strategy.sort.columns 配置:
这是本次主要的测试点。该配置可以对指定的列进行排序。
即,当做 clustering 的时候,hudi 会重新读取所有文件,并根据指定的列做排序,这样可以把相关的数据聚集在一起,可以做更好的查询过滤(后面会演示说明),而我们要做的对比,就是以 fare 为条件查询数据,观察在 clustering 前后,hudi 会读取的文件个数。
我们想要的结果是,在 clustering 之前,由于没有根据 fare 对数据任何处理,符合过滤条件的数据会分布在各个文件,所以会读取的文件个数很多,过滤效果差。而在 clustering 之后,会根据 fare 列对数据做重新分布,符合过滤条件的数据较为集中,那么读取的数据就会比较少,过滤效果较好。
3、修改了 hoodie.clustering.plan.strategy.target.file.max.bytes 和 hoodie.clustering.plan.strategy.small.file.limit
我们想测的是,clustering 前后过滤的效果,所以文件个数不能够被改变(否则4个文件合并成1个文件后,读取数据时也只会读取1个文件,就看不出来sort是否有效果),所以这里把该值设置成两个较为近似的值,使其既能够触发 clustering,又能够在 clustering 前后文件个数相同。
执行结果:
查看当前磁盘文件:
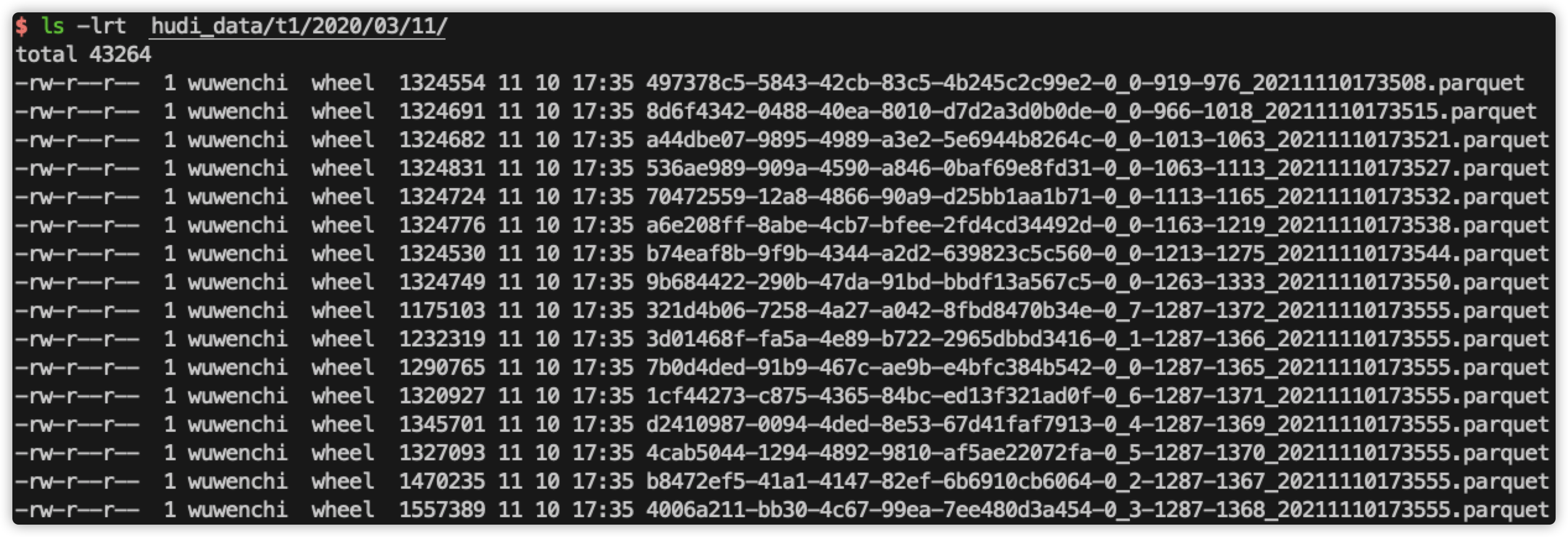
查看第5次的sql过滤结果:
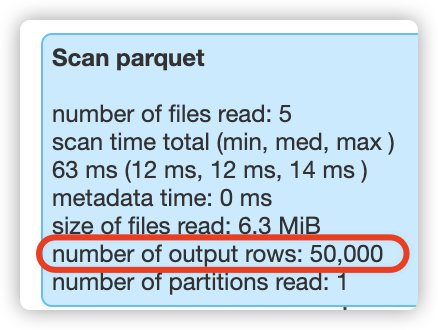
查看第6次的sql过滤结果:
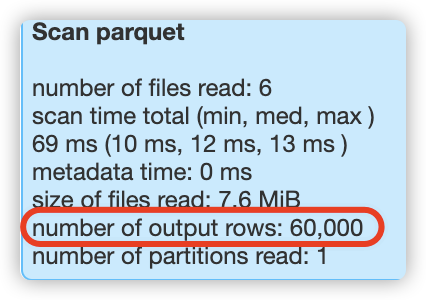
查看第7次的sql过滤结果:
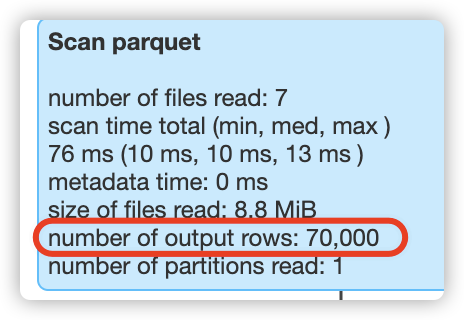
查看最后一次的sql过滤结果:
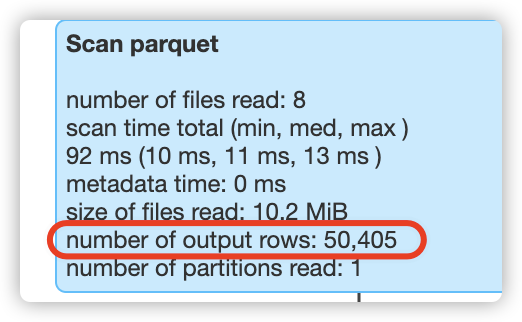
结论:
1、在 clustering 之前,过滤 fare 列时,会读取所有的数据。
比如,在执行第5次过滤时,此时表总共有50000行数据,hudi就会扫描50000行数据;在执行第6次过滤时,此时表总共有60000行数据,hudi就会扫描60000行数据;在执行第7次过滤时,此时表总共有70000行数据,hudi就会扫描70000行数据,
2、在 clustering 之后,数据文件个数不变的情况下(前后都是8个数据文件),在第8次过滤时,能够有效应用sort columns的重排列数据,将本应扫描80000行数据降低到只扫描了50405行数据,过滤效果明显提升很多!!
hudi clustering 数据聚集(二)的更多相关文章
- hudi clustering 数据聚集(一)
概要 数据湖的业务场景主要包括对数据库.日志.文件的分析,而管理数据湖有两点比较重要:写入的吞吐量和查询性能,这里主要说明以下问题: 1.为了获得更好的写入吞吐量,通常把数据直接写入文件中,这种情况下 ...
- hudi clustering 数据聚集(三 zorder使用)
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28),所以可以自己编译 master 分支,提前体验下 zorder 效果. 环境 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 从txt文件中读取数据放在二维数组中
1.我D盘中的test.txt文件内的内容是这样的,也是随机产生的二维数组 /test.txt/ 5.440000 3.4500006.610000 6.0400008.900000 3.030000 ...
- 决战大数据之二:CentOS 7 最新JDK 8安装
决战大数据之二:CentOS 7 最新JDK 8安装 [TOC] 修改hostname # hostnamectl set-hostname node1 --static # reboot now 重 ...
- [数据清洗]- Pandas 清洗“脏”数据(二)
概要 了解数据 分析数据问题 清洗数据 整合代码 了解数据 在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的.我们尝试去理解数据的列/行.记录.数据格式.语义错误.缺失的条目以及错误的 ...
- 机器学习入门-数值特征-进行二值化变化 1.Binarizer(进行数据的二值化操作)
函数说明: 1. Binarizer(threshold=0.9) 将数据进行二值化,threshold表示大于0.9的数据为1,小于0.9的数据为0 对于一些数值型的特征:存在0还有其他的一些数 二 ...
- SQL 2005批量插入数据的二种方法
SQL 2005批量插入数据的二种方法 Posted on 2010-07-22 18:13 moss_tan_jun 阅读(2635) 评论(2) 编辑 收藏 在SQL Server 中插入一条数据 ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- python列表底层实现原理
Python 列表的数据结构是怎么样的? 书上说的是:列表实现可以是数组和链表.顺序表是怎么回事?顺序表一般是数组. 列表是一个线性的集合,它允许用户在任何位置插入.删除.访问和替换元素.列表实现是基 ...
- 启用 Spring-Cloud-OpenFeign 配置可刷新,项目无法启动,我 TM 人傻了(上)
本篇文章涉及底层设计以及原理,以及问题定位,比较深入,篇幅较长,所以拆分成上下两篇: 上:问题简单描述以及 Spring Cloud RefreshScope 的原理 下:当前 spring-clou ...
- 10.3 Nginx
Nginx介绍 engine X,2002年开发,分为社区版和商业版(nginx plus) 2019年 f5 Networks 6.7亿美元收购nginx Nginx 免费 开源 高性能 http ...
- requirejs的加载原理 - 场景1. 定义一个require依赖a模块
我们学习一个新的技术,熟练的使用之后,就应该去探索它的原理.这篇文章我们来探索下requirejs的原理. 从4个场景来探索requirejs的原理 场景1. 定义一个require依赖b模块 场景2 ...
- Bayou复制分布式存储系统
本文主要参考文献[1]完成. 第1章导读 Bayou是一个复制的.弱一致性的存储系统,用于移动计算环境.为了最大化可用性,Bayou为用户提供了可以任意读写访问的副本.Bayou的设计侧重于为应用程序 ...
- 洛谷3809 SA模板 后缀数组学习笔记(复习)
其实SA这个东西很久之前就听过qwq 但是基本已经忘的差不多了 嘤嘤嘤 QWQ感觉自己不是很理解啊 所以写不出来那种博客 QWQ只能安利一些别人的博客了 小老板 真的是讲的非常好 不要在意名字 orz ...
- spoj2 prime1 (区间筛)
给定t组询问,每组询问包括一个l和r,要求\([l,r]\)的素数有哪些 其中\(t \le 10,1 \le l \le r \le 1000000000 , r-l \le 100000\) Qw ...
- Vulnhub实战-Dockhole_2靶机👻
Vulnhub实战-Dockhole_2靶机 靶机地址:https://www.vulnhub.com/entry/darkhole-2,740/ 1.描述 hint:让我们不要浪费时间在蛮力上面! ...
- OpenSSL version mismatch. Built against 1010104f, you have 101000cf
现象:公司一台Ubuntu16.04.2的ssh后台无法连接,telnet端口也不通,只能接显示器操作了. 先进行初步排查 查看服务是否启动(公司测试机ssh都是默认启动的) netstat -anp ...
- 安装早期老版本 Visual Studio
安装早期老版本 Visual Studio https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/