Spark Core核心----RDD常用算子编程
1、RDD常用操作2、Transformations算子3、Actions算子4、SparkRDD案例实战
1、Transformations算子(lazy)
含义:create a new dataset from an existing on 从已经存在的创建一个新的数据集
RDDA---------transformation----------->RDDB
map:map(func)
将func函数作用到数据集的每一个元素上,生成一个新的分布式的
数据集返回
例子:1
data = [1, 2, 3, 4, 5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x:x*2)
print(rdd2.collect())
例子2:
a = sc.parallelize(["dog","tiger","lion","cat","panther","eagle"]).map(lambda x:(x,1))
print(a.collect())结果:

filter(过滤)filter(func)
选出所有func返回值为true的元素,生成一个新的分布式数据集返回
例子:
RDDA = sc.parallelize([1, 2, 3, 4, 5]).map(lambda x:x*2).filter(lambda x:x>5)
print(RDDA.collect())结果:

flatMap() flatMap(func)
输入的item能够被map到0或者多个items输出,返回值是一个Sequence (拆分)
data = ["hello spark","hello word","hello word"]
RDD = sc.parallelize(data)
print(RDD.flatMap(lambda line:line.split(" ")).collect())结果
groupByKey()(把相同的key的数据分发到一起)
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line:line.split(" ")).map(lambda x:(x,1))
RDD3 = RDD2.groupByKey()
print(RDD3.map(lambda x:{x[0]:list(x[1])}).collect())结果
reduceByKey(把相同的key的数据分发到一起,并进行相应的计算)
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1))
RDD3 = RDD2.reduceByKey(lambda a,b:a+b)
print(RDD3.collect())结果
sortByKey()默认按照key值升序排列
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1))
RDD3 = RDD2.reduceByKey(lambda a, b: a + b)
sortRDD = RDD3.sortByKey()
sortRDD.collect()结果
加False参数降序排列

实现按照数字排序
使用map交换一下顺序

union连接(把RDD连接起来)
a = sc.parallelize([1, 2, 3])
b = sc.parallelize([4, 5, 6])
a.union(b).collect()结果
distinct(去除重复)
a = sc.parallelize([1, 2, 3])
b = sc.parallelize([4, 3, 3])
a.union(b).distinct().collect()结果
join(内连接,左外连接,右外连接)
a = sc.parallelize([("A","a1"),("C","c1"),("D","d1"),("F","f1"),("F","f2")])
b = sc.parallelize([("A","a2"),("C","c2"),("C","c3"),("E","e1")])
a.join(b).collect() # 内连接
a.rightOuterJoin(b).collect() # 右外连接
a.leftOuterJoin(b).collect() # 左外连接
a.fullOuterJoin(b).collect() # 全连接内连接:
得到两者key值相同的值的集合
右外连接:以右表key为基准进行连接

左外连接:以左表以右表key为基准进行连接

全连接:左右连接的并集所有的都出来

2、Actions算子
含义:return a value to the driver program after running acomputation on the dataset
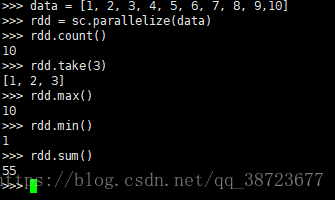
data = [1, 2, 3, 4, 5, 6, 7, 8, 9,10]
rdd = sc.parallelize(data)
rdd.count() # 数量
rdd.take(3) # 前几个
rdd.max() # 最大值
rdd.min() # 最小值
rdd.sum() # 求和
rdd.reduce(lambda x,y:x+y) # 求和
rdd.foreach(lambda x:print(x)) #foreach遍历
rdd.saveAsTextFile #写入文件系统结果:


Spark Core核心----RDD常用算子编程的更多相关文章
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- 4.RDD常用算子之transformations
RDD Opertions transformations:create a new dataset from an existing one RDDA --> RDDB ...
- 理解Spark的核心RDD
http://www.infoq.com/cn/articles/spark-core-rdd/
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
随机推荐
- Python图表库Matplotlib 组成部分介绍
图表有很多个组成部分,例如标题.x/y轴名称.大刻度小刻度.线条.数据点.注释说明等等. 我们来看官方给的图,图中标出了各个部分的英文名称 Matplotlib提供了很多api,开发者可根据需求定制图 ...
- pytest框架运用
import pytest ''' 运行方式 1. pytest -s test01.py 把print信息打印出来运行用例 2. 通过main运行 前置后置方法 1. 函数级 setup teard ...
- jenkens安装教程
war包安装方式(linux和windows下) 具体参见:https://www.cnblogs.com/UncleYong/p/10742867.html
- javascript中“==”,“===”和“Object.is(a,b)”的区别
作为两个量比较的三种方式"==","==="和"Object.is(a,b)"有一定区别,如下(具体见MDN): (1)Object.is( ...
- Python基础之实现界面和代码分离
第一步:用QT Designer画一个TreeWidget,存为treeview4.ui,这个处理前面TreeWidget那一节讲过,这里不细讲 treeview4.py # -*- coding: ...
- Charles抓包工具永久破解+https抓包需要安装安全证书+防止请求乱码
1.charles4.5.6版本安装+永久破解 链接:https://pan.baidu.com/s/1Z49AE6TG2IXUY-7qoyGU4g 提取码:3i97 安装好charles之后,把下载 ...
- c++ 父类 子类 虚表占用内存空间情况
#include <iostream> using namespace std; class C {}; class A:public C { private: long a; long ...
- Springboot 配置文件、隐私数据脱敏的最佳实践(原理+源码)
大家好!我是小富- 这几天公司在排查内部数据账号泄漏,原因是发现某些实习生小可爱居然连带着账号.密码将源码私传到GitHub上,导致核心数据外漏,孩子还是没挨过社会毒打,这种事的后果可大可小. 说起这 ...
- 关于vue3简单状态管理约定引发的思考
官方文档的代码是这样的 export const store = { debug: true, state: reactive({ message: 'Hello!' }), setMessageAc ...
- firewalld防火墙基础
目录 一.firewalld 概述 二.firewalld与iptables 的区别 三.firewalld 区域概念 四.Firewalld数据处理流程 五.Firewalld检查数据包的源地址的规 ...