Mysql慢查询explain
转自:https://www.toutiao.com/i6776461352522220036/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1597162174&app=news_article&utm_source=weixin&utm_medium=toutiao_ios&use_new_style=1&req_id=20200812000933010018086069053B6937&group_id=6776461352522220036
refer:https://www.cnblogs.com/yycc/p/7338894.html
explain的用途
1. 表的读取顺序如何
2. 数据读取操作有哪些操作类型
3. 哪些索引可以使用
4. 哪些索引被实际使用
5. 表之间是如何引用
6. 每张表有多少行被优化器查询
......explain的执行效果
mysql> explain select * from subject where id = 1 \G
******************************************************
id: 1
select_type: SIMPLE
table: subject
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 1
filtered: 100.00
Extra: NULL
******************************************************explain包含的字段
1. id //select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
2. select_type //查询类型
3. table //正在访问哪个表
4. partitions //匹配的分区
5. type //访问的类型
6. possible_keys //显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到
7. key //实际使用到的索引,如果为NULL,则没有使用索引
8. key_len //表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
9. ref //显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值
10. rows //根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数11. filtered //查询的表行占表的百分比12. Extra //包含不适合在其它列中显示但十分重要的额外信息图片版
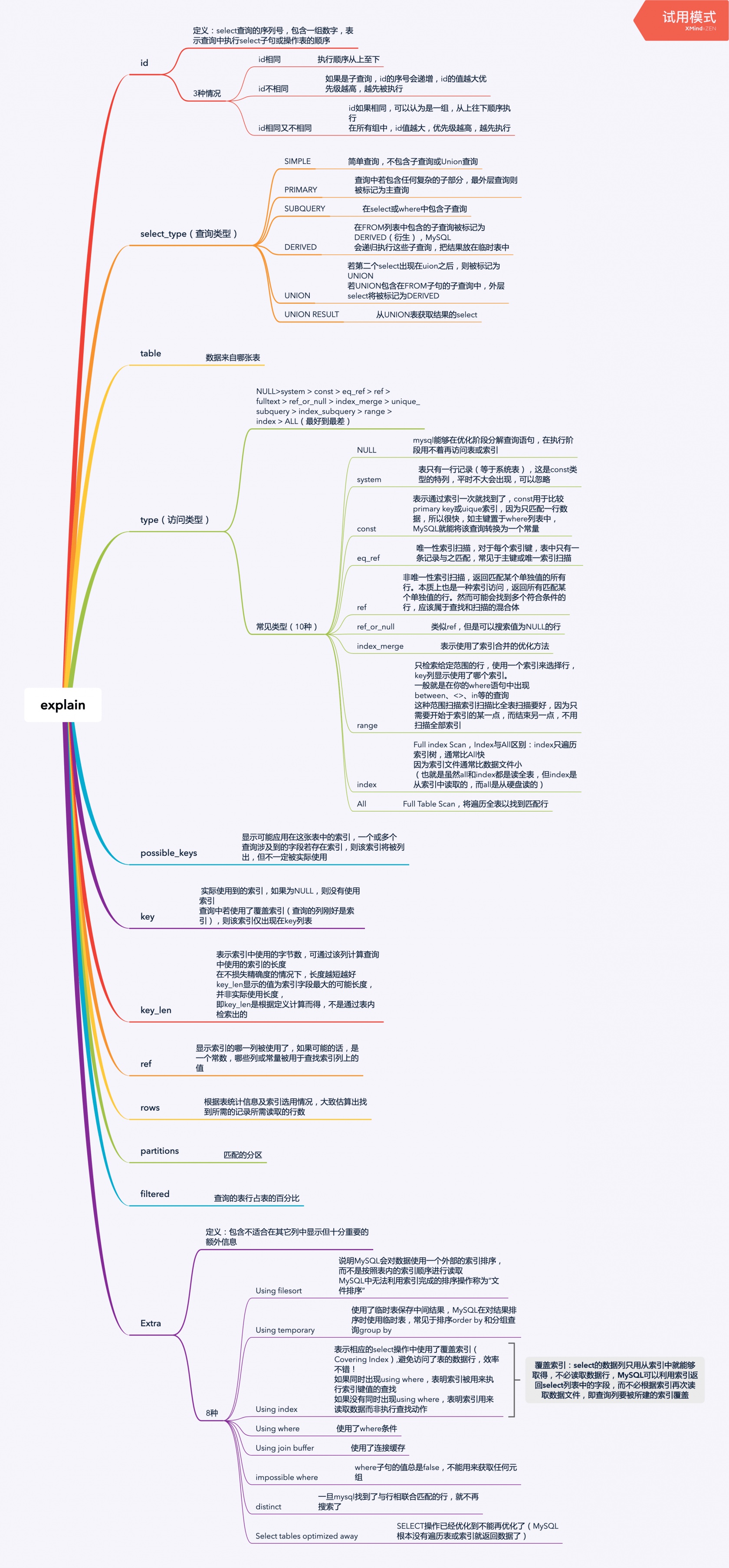
文字版
id字段
1. id相同
执行顺序从上至下
例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;
读取顺序:subject > teacher > student_score2. id不同
如果是子查询,id的序号会递增,id的值越大优先级越高,越先被执行
例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));读取顺序:teacher > subject > student_score3. id相同又不同
id如果相同,可以认为是一组,从上往下顺序执行在所有组中,id值越大,优先级越高,越先执行
例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id; 读取顺序:2.teacher > 2.subject > 1.subject > 1.teacherselect_type字段
1. SIMPLE
简单查询,不包含子查询或Union查询
例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;2. PRIMARY
查询中若包含任何复杂的子部分,最外层查询则被标记为主查询
例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));3. SUBQUERY
在select或where中包含子查询
例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));4. DERIVED
在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表中
备注:MySQL5.7+ 进行优化了,增加了derived_merge(派生合并),默认开启,可加快查询效率5. UNION
若第二个select出现在uion之后,则被标记为UNION
例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;6. UNION RESULT
从UNION表获取结果的select
例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;type字段
NULL>system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL //最好到最差
备注:掌握以下10种常见的即可
NULL>system>const>eq_ref>ref>ref_or_null>index_merge>range>index>ALL1. NULL
MySQL能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引
例子:explain select min(id) from subject;2. system
表只有一行记录(等于系统表),这是const类型的特列,平时不大会出现,可以忽略3. const
表示通过索引一次就找到了,const用于比较primary key或uique索引,
因为只匹配一行数据,所以很快,如主键置于where列表中,MySQL就能将该查询转换为一个常量
例子:explain select * from teacher where teacher_no = 'T2010001';4. eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描
例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id;5. ref
非唯一性索引扫描,返回匹配某个单独值的所有行本质上也是一种索引访问,
返回所有匹配某个单独值的行然而可能会找到多个符合条件的行,应该属于查找和扫描的混合体
例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;6. refornull
类似ref,但是可以搜索值为NULL的行
例子:explain select * from teacher where name = 'wangsi' or name is null;7. index_merge
表示使用了索引合并的优化方法
例子:explain select * from teacher where id = 1 or teacher_no = 'T2010001' .8. range
只检索给定范围的行,使用一个索引来选择行,
key列显示使用了哪个索引一般就是在你的where语句中出现between、<>、in等的查询
例子:explain select * from subject where id between 1 and 3;9. index
Full index Scan,Index与All区别:index只遍历索引树,
通常比All快因为索引文件通常比数据文件小,也就是虽然all和index都是读全表,
但index是从索引中读取的,而all是从硬盘读的。
例子:explain select id from subject;10. ALL
Full Table Scan,将遍历全表以找到匹配行
例子:explain select * from subject;table字段
数据来自哪张表possible_keys字段
显示可能应用在这张表中的索引,一个或多个查询涉及到的字段若存在索引,
则该索引将被列出,但不一定被实际使用key字段
实际使用到的索引,如果为NULL,则没有使用索引查询中若使用了覆盖索引(查询的列刚好是索引),
则该索引仅出现在key列表key_len字段
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度在不损失精确度的情况下,
长度越短越好key_len显示的值为索引字段最大的可能长度,
并非实际使用长度即key_len是根据定义计算而得,不是通过表内检索出的ref字段
显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值rows字段
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数partitions字段
匹配的分区filtered字段
查询的表行占表的百分比Extra字段
包含不适合在其它列中显示但十分重要的额外信息1. Using filesort
说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取MySQL中无法利用索引完成的排序操作称为“文件排序”
例子:explain select * from subject order by name;2. Using temporary
使用了临时表保存中间结果,MySQL在对结果排序时使用临时表,常见于排序order by 和分组查询group by
例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;3. Using index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找
如果没有同时出现using where,表明索引用来读取数据而非执行查找动作
例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;备注:覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,即查询列要被所建的索引覆盖4. Using where
使用了where条件
例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;5. Using join buffer
使用了连接缓存
例子:explain select student.*,teacher.*,subject.* from student,teacher,subject;6. impossible where
where子句的值总是false,不能用来获取任何元组
例子:explain select * from teacher where name = 'wangsi' and name = 'lisi';7. distinct
一旦mysql找到了与行相联合匹配的行,就不再搜索了
例子:explain select distinct teacher.name from teacher left join subject on teacher.id = subject.teacher_id;8. Select tables optimized away
SELECT操作已经优化到不能再优化了(MySQL根本没有遍历表或索引就返回数据了)
例子:explain select min(id) from subject;使用的数据表
create table subject( -> id int(10) auto_increment, -> name varchar(20), -> teacher_id int(10), -> primary key (id), -> index idx_teacher_id (teacher_id));//学科表
create table teacher( -> id int(10) auto_increment, -> name varchar(20), -> teacher_no varchar(20), -> primary key (id), -> unique index unx_teacher_no (teacher_no(20)));//教师表
create table student( -> id int(10) auto_increment, -> name varchar(20), -> student_no varchar(20), -> primary key (id), -> unique index unx_student_no (student_no(20)));//学生表
create table student_score( -> id int(10) auto_increment, -> student_id int(10), -> subject_id int(10), -> score int(10), -> primary key (id), -> index idx_student_id (student_id), -> index idx_subject_id (subject_id));//学生成绩表
alter table teacher add index idx_name(name(20));//教师表增加名字普通索引
数据填充:
insert into student(name,student_no) values ('zhangsan','20200001'),('lisi','20200002'),('yan','20200003'),('dede','20200004');
insert into teacher(name,teacher_no) values('wangsi','T2010001'),('sunsi','T2010002'),('jiangsi','T2010003'),('zhousi','T2010004');
insert into subject(name,teacher_id) values('math',1),('Chinese',2),('English',3),('history',4);
insert into student_score(student_id,subject_id,score) values(1,1,90),(1,2,60),(1,3,80),(1,4,100),(2,4,60),(2,3,50),(2,2,80),(2,1,90),(3,1,90),(3,4,100),(4,1,40),(4,2,80),(4,3,80),(4,5,100);Mysql慢查询explain的更多相关文章
- MySQL慢查询Explain Plan分析
Explain Plan 执行计划,包含了一个SELECT(后续版本支持UPDATE等语句)的执行 主要字段 id 编号,从1开始,执行的时候从大到小,相同编号从上到下依次执行. Select_typ ...
- mysql的查询使用explain的讲解
摘自:http://www.jb51.net/article/33736.htm 在 explain的帮助下,您就知道什么时候该给表添加索引,以使用索引来查找记录从而让select 运行更快.如果由于 ...
- 在MySQL中使用explain查询SQL的执行计划
1.什么是MySQL执行计划 要对执行计划有个比较好的理解,需要先对MySQL的基础结构及查询基本原理有简单的了解. MySQL本身的功能架构分为三个部分,分别是 应用层.逻辑层.物理层,不只是MyS ...
- 如何在MySQL中使用explain查询SQL的执行计划?
1.什么是MySQL执行计划 要对执行计划有个比较好的理解,需要先对MySQL的基础结构及查询基本原理有简单的了解. MySQL本身的功能架构分为三个部分,分别是 应用层.逻辑层.物理层,不只是MyS ...
- MySQL的查询计划中ken_len的值计算
本文首先介绍了MySQL的查询计划中ken_len的含义:然后介绍了key_len的计算方法:最后通过一个伪造的例子,来说明如何通过key_len来查看联合索引有多少列被使用. key_len的含义 ...
- MySQL查询优化之explain的深入解析
在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要执行的行数.expla ...
- [慢查优化]慎用MySQL子查询,尤其是看到DEPENDENT SUBQUERY标记时
案例梳理时间:2013-9-25 写在前面的话: 在慢查优化1和2里都反复强调过 explain 的重要性,但有时候肉眼看不出 explain 结果如何指导优化,这时候还需要有一些其他基础知识的佐助, ...
- 如何查找MySQL中查询慢的SQL语句
如何查找MySQL中查询慢的SQL语句 更多 如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow ...
- Mysql 慢查询设置
Mysql慢查询设置 分析MySQL语句查询性能的方法除了使用 EXPLAIN 输出执行计划,还可以让MySQL记录下查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”. === ...
随机推荐
- Linux用户提权管理方案
提权管理方案背景: 如果一个公司有10余个运维或网络安全人员,同时管理服务器,切换到管理员用户时(su - root),必须要有root管理员密码,如果其中一人修改过root密码,其他用户则登录不了, ...
- P6982 [NEERC2015]Jump
P6982 [NEERC2015]Jump 题意 给你一个未知的 01 串,每次可以输出询问一个 01 串,如果该串中正确的个数刚好等于 \(n\) 或者 \(n/2\) ,将会返回相应的答案,否则会 ...
- 【用例】编写App测试用例的关注点
编写App测试用例的关注点 如何做到测试用例的百分百覆盖一直是测试用例编写过程中的难点,首先在测试时我们经常会遇见一些常见的bug,那么我们可以在编写测试用例时考虑到这些点. 一:关于业务逻辑 ...
- Python - 对象赋值、浅拷贝、深拷贝的区别
前言 Python 中不存在值传递,一切传递的都是对象的引用,也可以认为是传址 这里会讲三个概念:对象赋值.浅拷贝.深拷贝 名词解释 变量:存储对象的引用 对象:会被分配一块内存,存储实际的数据,比如 ...
- vulnhub-DC:6靶机渗透记录
准备工作 在vulnhub官网下载DC:6靶机DC: 6 ~ VulnHub 导入到vmware,设置成NAT模式 打开kali准备进行渗透(ip:192.168.200.6) 信息收集 利用nmap ...
- 【进阶之路】Java的类型擦除式泛型
Java选择的泛型类型叫做类型擦除式泛型.什么是类型擦除式泛型呢?就是Java语言中的泛型只存在于程序源码之中,在编译后的字节码文件里,则全部泛型都会被替换为原来的原始类型(Raw Type),并且会 ...
- vue菜单切换
HTML: <div id="box"> <ul> <li v-for= "(item,index) in arry"> & ...
- PCE | 华中农大郭亮团队蛋白质组学揭示油菜内源氧化还原修饰介导盐胁迫响应
蛋白质翻译后修饰(PTM)在控制植物生长发育以及逆境适应方面发挥着重要的作用.发生在半胱氨酸巯基的亚磺酰化修饰(R-SOH)是一种可逆的氧化修饰类型,可以通过与其他修饰形态形成二硫键的形式来保护蛋白不 ...
- git只提交部分修改的文件(提交指定文件)
在我们的项目中,经常会在本地编译一些代码,还未写完,测试那边来告诉你要改改某个文件的bug,非常着急,此时改完了,提交的时候,自己还在编译的代码并不想提交,此时,你可以利用git这些指令帮助你! 1/ ...
- spring学习08(声明式事务)
11.声明式事务 11.1 回顾事务 事务在项目开发过程非常重要,涉及到数据的一致性的问题,不容马虎! 事务管理是企业级应用程序开发中必备技术,用来确保数据的完整性和一致性. 事务就是把一系列的动作当 ...