图的遍历---------开始开始-------o(∩_∩)o 哈哈
图的遍历
深度优先搜索(Depth First Search , DFS)
--深度优先搜索--我的理解就是分身术的另一种实现方法---用分身术将所有能看到的路都走一遍----这就是深度搜索---
下面给一个图 让大家理解一下

void DFS(Vertex V) //深度优先搜索的伪码描述
{
visited[V]=ture; //先点亮这个节点的灯
for(V的每个临节点 W) //站在V的位置 所有能看到的灯 W
if(!Visited[W])//如果没有亮
DFS(W);//走到这个灯的位置递归的点亮(递归确实很难理解,但是在前面我已经给了两个训练递归思想的代码,你还记得么?)
} //不得不说 虽然递归十分耗费内存但是递归确实 很好用.
越看感觉越想 树的先序遍历,有木有? 递归的思想是一样的(你在树那里的遍历方法有几种这里可以用不?)
----------前面咱们说了两种----图的储存方式----
下面来说一下不同的储存方式 , 用于搜索带来的不同效果.
若有N个节点,E条边 , 时间复杂度是
· 用邻接矩阵储存图,有O(N+E) // 如果用邻接矩阵的话 在这个算法当中相当于 每个节点 每条边都走了一次.
· 用邻接矩阵储存图 , 有O(N^2) //这个怎么说呢 自己想想
void DFS(Vertex V) //深度优先搜索的伪码描述
{
visited[V]=ture; //先点亮这个节点的灯
for(V的每个临节点 W) //站在V的位置 所有能看到的灯 W
if(!Visited[W])//如果没有亮
DFS(W);//走到这个灯的位置递归的点亮(递归确实很难理解,但是在前面我已经给了两个训练递归思想的代码,你还记得么?)
} //不得不说 虽然递归十分耗费内存但是递归确实 很好用.
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------今天听鹏哥说了一上午 也算复习 也算预习 也有收获 ------------
深度优先搜索,就是找一条线 向下面 一直搜 ,,,而广度优先搜索是 从一个点开始 向外面慢慢的扩散------
下面附上广搜的相关.
广度优先搜索(Breadth First Search ,,BFS)
从根节点出发,从上到下 ,从左到右-------具体的实现是借助一个队列---这个前面咱们将堆的时候好像说过.
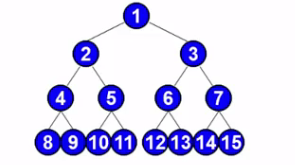 走过的顺序就是这个
走过的顺序就是这个
void BFS(Vertex V) //树的根节点
{
visited[V]=ture; //访问 上面传下来的根节点 并且标记为已访问
Enqueue(V,Q); //将 V 压进队列里面
while(IsEmpty[Q]) //判断队列是否为空
{
V=Dequeue(Q); //出队列 并且赋值给V
for(V的每个临节点W) //V访问 V的每个临节点
{
if(!visited[W]) //如果已经访问 就算了 否则进去,
{
visited[w]=ture;
Enqueue(W,Q); //将刚才被删除的元素的 儿子压进去.
}
}
}
}
邻接矩阵 时间复杂度为 N^2 然而邻接表的时间复杂度是 N+E 思考一下 why?
-----------------------下面开始说 --两种不同的遍历 分别适用的方向.----下面附上一个 大侠走迷宫.-----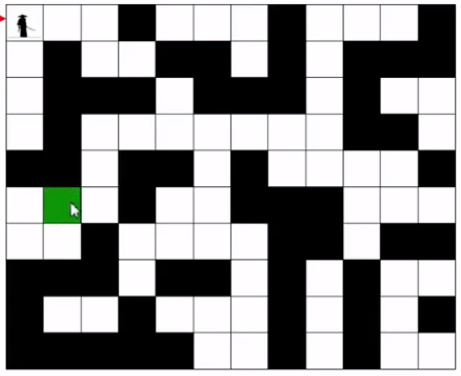
给大侠一点规定------大侠喜欢 从十二点方向开始,按照顺时针的方法走路口---------
这时候大侠走出迷宫的 所需要经过的 格子就很多了
如果大侠 按照广搜的方法 仍然 十二点顺时针 是什么情况?
-------------------------不挨着的节点怎么----图不连通?----那还遍历个什么呀?----------------------
连同: 如果从V到W存在一条(无向)路径,则称V和W是连通的.
路径:V到W的路径是一系列顶点{V,v1,v2,v3,...,vn,W}的集合其中任一一对相邻的顶点间都有图中的边.路径的长度是路径中的变数(如果带权的话,则是各边的权重之和) . 如果从V到W之间的所有顶点都不同则成为简单路径.
回路:起点等于终点的路径, (V ,v1,v2,v3,V 这就是一个回路).
连通图:图中任意两顶点均连通.
图不连通怎么办?
连通分量:无向图的极大连同子图 (好好理解慢慢看).
极大顶点数:再加一个顶点就不联通了.
极大边数:包含子图中所有顶点相连的所有边.
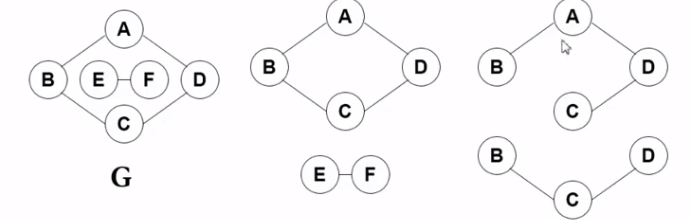
G是原图 后面的四个就是无向图G的极大连同子图 从上到下 从左到右的顺序开始说.
第一个 符合上述两点 第二个也符合
第三个 不符合第二点 第四个 不符合第一点
------------------------------------------------------------------------------------------------
下面说说 有向图 有向图分为强连同和弱连同
强连同:有向图中顶点V,W之间存在双向路径,则称V,和W是强连同的.(意思就是说 我也已从V 到W 也可以从W到V 其中不需要必须走同一条路)
强连通图:有向图中任意两顶点均强连同.
强连通分量:有向图的极大强连同子图.
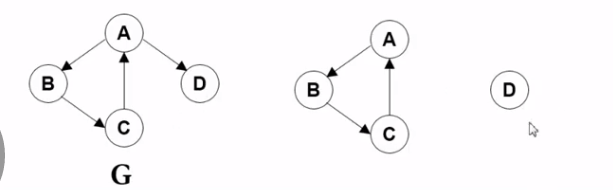
图G的极大强连同子图有两个 第一个 任意两点都可以连同 并且 再多一个 就不行了 第二个 也是
void DFS(Vertex V) //最终将所有连通的都 遍历了.
{
visited[V]=ture;
for(V的每个节点W)
if(!visited[w])
DFS(W);
}
/*不连通的怎么遍历呢?*/
void ListComponents(Graph G)
{
for(each V in G) //向下输送所有的 不连通分量
if(!visited[v])
{
DFS(v); // or BFS[v];
}
}
拯救007......007被 困在了一个孤岛上面 湖里面都是鳄鱼 英勇的零零七 决定一 鳄鱼头当成 跳板跳到河岸上面下面附图
这一道题 深度优先 和广度优先 都可以 但是 根据实际问题来看 深度优先 可能更好一点.
我们在上面第一个程序上做一个 修改.
void Save007(Graph G)
{
for(each V in G) //孤岛上面的 所有相邻的 岛一个一个试 知道 跳出去.
{
if(!visited[V]&&FirstJumpe[V]) //没有跳过 并且 第一跳可以跳出.
{
answer=DFS[v];
}
}
if(answer==YEs)
output("Yes");
else
output("NO");
}
图的遍历---------开始开始-------o(∩_∩)o 哈哈的更多相关文章
- 图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次.(连通图与非连通图) 深度优先遍历(DFS): 1.访问指定的起始顶点: 2.若当前访问的顶点的邻接顶点有未被访问的,则 ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- Kruskal和prime算法的类实现,图的遍历BFS算法。
一.图的遍历 #include<iostream> #include<queue> #include<vector> using namespace std; in ...
- 图的遍历——DFS(矩形空间)
首先,这里的图不是指的我们一般所说的图结构,而是大小为M*N的矩形区域(也可以看成是一个矩阵).而关于矩形区域的遍历问题经常出现,如“寻找矩阵中的路径”.“找到矩形区域的某个特殊点”等等之类的题目,在 ...
- 图的遍历——DFS和BFS模板(一般的图)
关于图的遍历,通常有深度优先搜索(DFS)和广度优先搜索(BFS),本文结合一般的图结构(邻接矩阵和邻接表),给出两种遍历算法的模板 1.深度优先搜索(DFS) #include<iostrea ...
- 图的遍历算法:DFS、BFS
在图的基本算法中,最初需要接触的就是图的遍历算法,根据访问节点的顺序,可分为深度优先搜索(DFS)和广度优先搜索(BFS). DFS(深度优先搜索)算法 Depth-First-Search 深度优先 ...
- 15 图-图的遍历-基于邻接矩阵实现的BFS与DFS算法
算法分析和具体步骤解说直接写在代码注释上了 TvT 没时间了等下还要去洗衣服 就先不赘述了 有不明白的欢迎留言交流!(估计是没人看的了) 直接上代码: #include<stdio.h> ...
- python 回溯法 子集树模板 系列 —— 8、图的遍历
问题 一个图: A --> B A --> C B --> C B --> D B --> E C --> A C --> D D --> C E -- ...
- [图的遍历&多标准] 1087. All Roads Lead to Rome (30)
1087. All Roads Lead to Rome (30) Indeed there are many different tourist routes from our city to Ro ...
随机推荐
- vmware下centos6.7网络配置
使用NAT方式: 查看/etc/sysconfig/network-script/ 下面没有ifcfg-eth0 新建ifcfg-eth0,内容如下 DEVICE=eth0 BOOTPROTO=dhc ...
- Java中的重写
以下内容引用自http://wiki.jikexueyuan.com/project/java/overriding.html: 如果一个类从它的父类继承了一个方法,如果这个方法没有被标记为final ...
- mysql查看存储过程show procedure status;
1.mysql查看存储过程(函数) 2.MySQL查看触发器 查看触发器 语法:SHOW TRIGGERS [FROM db_name] [LIKE expr] 实例:SHOW TRIGGERS\G ...
- weblogic线程阻塞性能调优(图解)
转自:http://blog.csdn.net/z69183787/article/details/12647539 声明:出现这个问题有程序方面.网络方面.weblogic设置方面等等原因,此文章主 ...
- [Rust] Setup Rust for WebAssembly
In order to setup a project we need to install the nightly build of Rust and add the WebAssembly tar ...
- ZOJ 3316 Game 一般图最大匹配带花树
一般图最大匹配带花树: 建图后,计算最大匹配数. 假设有一个联通块不是完美匹配,先手就能够走那个没被匹配到的点.后手不论怎么走,都必定走到一个被匹配的点上.先手就能够顺着这个交错路走下去,最后一定是后 ...
- 李洪强iOS开发之录音和播放实现
李洪强iOS开发之录音和播放实现 //首先导入框架后,导入头文件.以下内容为托控件,在storyboard中拖出两个按钮为录音和播放按钮 //创建一个UIViewController在.h文件中写 # ...
- 城域网IPv6过渡技术—NAT64+DNS64 Test for IPv6 DNS64/NAT64 Compatibility Regularly
城域网IPv6过渡技术—NAT64+DNS64 - 51CTO.COM http://network.51cto.com/art/201311/419623.htm Supporting IPv6 D ...
- Statement 与 PreparedStatement 区别
Statement由方法createStatement()创建,该对象用于发送简单的SQL语句 PreparedStatement由方法prepareStatement()创建,该对象用于发送带有一个 ...
- mongo13----application set与分片结合
replation set配合分片 打开3台服务器,B服务器()放configserv, C,D服务器(203.204)放置复制集 .203和192.168.1.204分别运行之前的sh start. ...