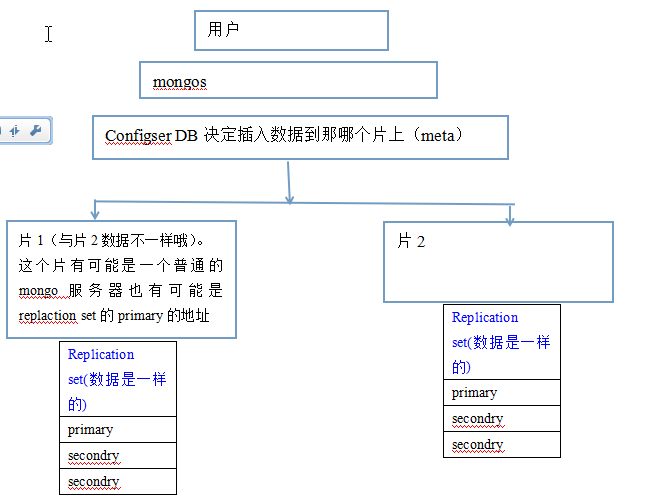
mongo13----application set与分片结合
replation set配合分片 打开3台服务器,B服务器(202)放configserv, C,D服务器(203.204)放置复制集 192.168.1.203和192.168.1.204分别运行之前的sh start.sh(要把ip和rs的名字改了),那么就在这2个ip上搭建了一个replation set.
192.168.1.203>192.168.1.204> sh start.sh reset
192.168.1.203>192.168.1.204> sh start.sh install //复制集创建完毕(2个片创建完毕)
192.168.1.203>192.168.1.204> sh start.sh repl //接下来202 ip创建mongos和configsrv,
192.168.1.202> sh start.sh reset //清理初始化
192.168.1.202> mkdir -p /home/m20 /home/mlog //初始化configsrv(一般也是分在不同的服务器上,防止down掉)
192.168.1.202> /usr/local/mongodb/bin/mongod --dbpath /home/m20/ --logpath /home/mlog/m20.log --port 27020 --fork --configsvr //27020端口
//初始化mongos
192.168.1.202> /usr/local/mongodb/bin/mongos --logpath /data/mlog/r30.log --port 30000 --configdb 192.168.202:27020 --fork //端口是30000,configser是192.168.202:27020,mongos和configsvr连在了一起 ps aux | grep momgo //连接30000(最好用ip连接,不要只输入端口)
192.168.1.202> ./bin/mongo 192.168.1.202:30000 //添加repl set为片,现在3者都连接到一起了,
192.168.1.202> sh.addShard('rs3/192.168.1.203:27017') //17端口的复制集加进去
192.168.1.202> sh.addShard('rs4/192.168.1.204:27018') //18端口的复制集加进去 192.168.1.202> sh.status(); //看到建立好了 192.168.1.202> sh.enableSharding('shop'); //shop库是要分片的
192.168.1.202> sh.shardCollection('shop.user',{id:1}); //shop库的user表,用id来做片键,分到哪个片上, //手动分片,id遇到1000的整数倍就拆一下
192.168.1.202> sh.splitAt('shop.user',{id:1000}) //1000拆一下
192.168.1.202> sh.splitAt('shop.user',{id:2000}) //2000拆一下
192.168.1.202> sh.splitAt('shop.user',{id:3000}) //3000拆一下,多的话可以写一个for循环。 192.168.1.202> sh.status() 192.168.1.202> use shop
192.168.1.202> for(var i=1;i<=4000;i++) {//一共4000条
db.user.insert({userid:i,name:"kitty"})
} //现在03,04是片,并且还在复制集有2个拷贝。1---2000在203,2000----4000在204上 192.168.1.203> ./bin/mongo
192.168.1.203> use shop
192.168.1.203> show tables //自动创建了库和表
192.168.1.203> db.user.find().count() //2001条
192.168.1.203> db.user.find().skip(1980) 192.168.1.203> ./bin/mongo --port 27018 //片上的secondary次节点
192.168.1.203> use shop
192.168.1.203> rs.slaveok() //不然不能看
192.168.1.203> db.user.find().count() //2001条
192.168.1.203> db.user.find().skip(1980) //完全一样了 192.168.1.204> ./bin/mongo
192.168.1.204> use shop
192.168.1.204> show tables //自动创建了库和表
192.168.1.204> db.user.find().count() //1999条
192.168.1.204> db.user.find().skip(1980) 192.168.1.204> ./bin/mongo --port 27018 //片上的secondary次节点
192.168.1.204> use shop
192.168.1.204> rs.slaveok() //不然不能看
192.168.1.204> db.user.find().count() //2001条
192.168.1.204> db.user.find().skip(1980) //完全一样了 start.sh文件:
#!/bin/bash
IP='192.168.1.202'
NA='rsb' if [ "$1" = "reset" ]
then
pkill -9 mongo
rm -rf /home/m*
exit
fi if [ "$1" = "install" ]
then mkdir -p /home/m0 /home/m1 /home/m2 /home/mlog /usr/local/mongodb/bin/mongod --dbpath /home/m0 --logpath /home/mlog/m17.log --logappend --port 27017 --fork
--replSet ${NA}
/usr/local/mongodb/bin/mongod --dbpath /home/m1 --logpath /home/mlog/m18.log --logappend --port 27018 --fork
--replSet ${NA}
/usr/local/mongodb/bin/mongod --dbpath /home/m2 --logpath /home/mlog/m19.log --logappend --port 27019 --fork
--replSet ${NA} exit
fi if [ "$1" = "repl" ]
then
/usr/local/mongodb/bin/mongo <<EOF use admin
rsconf = {
_id:'${NA}',
members:[
{_id:0,host:'${IP}:27017'},
{_id:1,host:'${IP}:27018'},
{_id:2,host:'${IP}:27019'},
]
}
rs.initiate(rsconf)
EOF
fi

mongo13----application set与分片结合的更多相关文章
- websocket protocal
same-orgins:浏览器同源策略的安全模型 持久化协议 双向双工 多路复用, 同时发信息 区别HTTP连接特点: http只能由客户端发起,一个request对应一个respon ...
- Flink架构(一)- 系统架构
1. 系统架构 Flink是一个分布式系统,用于有状态的并行数据流处理.也就是说,Flink会分布式地运行在多个机器上.在分布式系统中,常见的挑战有:如何对集群中的资源进行分配与管理.协调进程.数据存 ...
- MongoDB 分片管理
在MongoDB(版本 3.2.9)中,分片集群(sharded cluster)是一种水平扩展数据库系统性能的方法,能够将数据集分布式存储在不同的分片(shard)上,每个分片只保存数据集的一部分, ...
- MongoDB 搭建分片集群
在MongoDB(版本 3.2.9)中,分片是指将collection分散存储到不同的Server中,每个Server只存储collection的一部分,服务分片的所有服务器组成分片集群.分片集群(S ...
- MyCat 安装部署,实现数据库分片存储
一.安装MySQL或MariaDB(本文以MariaDB为例) MySQL手动安装方法:点击查看 MariaDB安装: 1.下载MariaDB的repo $ vi /etc/yum.repos.d/M ...
- spring boot application.properties 属性详解
2019年3月21日17:09:59 英文原版: https://docs.spring.io/spring-boot/docs/current/reference/html/common-appli ...
- Hadoop InputFormat 输入文件分片
1. Mapper 与 Reducer 数量 对于一个默认的MapReduce Job 来说,map任务的数量等于输入文件被划分成的分块数,这个取决于输入文件的大小以及文件块的大小(如果此文件在 HD ...
- webuploader分片上传
屁话不多说直接上主题; webuploader,sj(WebUploader 0.1.6)网上有下 powerUpload.js 自己写的基与楼上的插件 asp.net mvc/Api 实现效果: H ...
- Akka-Cluster(6)- Cluster-Sharding:集群分片,分布式交互程序核心方式
在前面几篇讨论里我们介绍了在集群环境里的一些编程模式.分布式数据结构及具体实现方式.到目前为止,我们已经实现了把程序任务分配给处于很多服务器上的actor,能够最大程度的利用整体系统的硬件资源.这是因 ...
- LwIP Application Developers Manual1---介绍
1.前言 本文主要是对LwIP Application Developers Manual的翻译 2.读者(应用开发手册的读者) 谁适合读这份手册 网络应用的开发者 想了解lwIP的网络应用开发者 阅 ...
随机推荐
- [MVC]Ajax辅助方法
在开始使用Ajax辅助方法前,必须在页面中载入jQuery以及jquery.unobtrusive-ajax.js文件才能正常执行. 为了让网站载入适当的JS函数库,必须先让Layout页面载入适当的 ...
- 创建ArrayList集合对象并添加元素
ArrayListDemo.java import java.util.ArrayList; /* * 为什么出现集合类: * 我们学习的是面向对象编程语言,而面向对象编程语言对事物的描述都是通过对象 ...
- Oracle数据库学习之存储过程--提高程序执行的效率
存储过程是Oracle开发者在数据转换或查询报表时经常使用的方式之一.它就是想编程语言一样一旦运行成功,就可以被用户随时调用,这种方式极大的节省了用户的时间,也提高了程序的执行效率.存储过程在数据库开 ...
- python3--shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式 import shelve d = shelve.open('shelve_t ...
- HDU 4821 字符串hash
题目大意: 希望找到连续的长为m*l的子串,使得m个l长的子串每一个都不一样,问能找到多少个这样的子串 简单的字符串hash,提前预处理出每一个长度为l的字符串的hash值 #include < ...
- idea web项目启动失败的情况---webapp文件夹路径不对,应如图位置
- msp430入门编程21
msp430中C语言的扩展--#pragma编译命令
- JavaScript 将行结构数据转化为树结构数据源(高效转化方案)
js接收到后台的数据如下 /// 部门信息 var departRows = [{ parentDepartId: 'root', departId: 'DC', departName: '集团' } ...
- Linux中查看文件或者文件夹大小
df -l 查看磁盘空间大小命令 df -hl 查看磁盘剩余空间 df -h 查看每个根路径的分区大小 du -sh 当前文件夹下所有文件大小(包括子文件大小 du -sm [文件夹] 返回该 ...
- vue Iframe
1.Iframe.vue <!-- Iframe --> <template> <div> <!-- 标题栏 --> <mt-header tit ...