[转] twemproxy ketama一致性hash分析
评注:提到HAProxy业务层proxy, twemproxy存储的proxy.
其中还提到了ketama算法的实现源码
转自:http://www.cnblogs.com/basecn/p/4288456.html
测试Twemproxy集群,双主双活
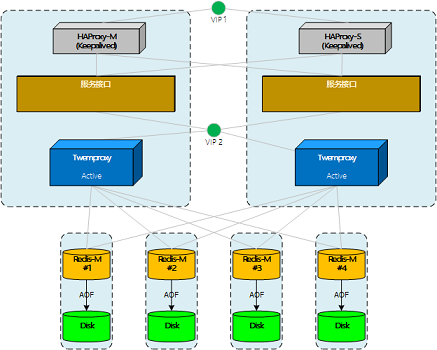
向twemproxy集群做写操作时,发现key的分布不太理想。在测试节点故障时,也发现一些和预想不太一样的地方。
1、Key的一致性Hash
当尝试以a001,a002这样有规律且的key值写入的时候,在4节点的集群环境中,key主要分布在其中的2台节点,另外两台分配极少。对于一些应用来说,key值可能根据一定规则生成,所以有被定向分配的可能。
解决办法在key中使用hash_key:{},hask_key使用8位随机数,测试结果分布的比较满意。
测试4节点中key的分布:
2: 10761
3: 8596
4: 14382
由于ketama的算法仍是使用了md5签名(具体后面说),又特意观察了比如有序数字生成的md5序列,结果并没有出现明显的有序或连序值。所以只能建议不使用连续的数据结尾key做一致性hash key。
2、ketama算法
twemproxy源码下载:https://github.com/twitter/twemproxy,命令:git clone https://github.com/twitter/twemproxy
关于ketama算法的代码在nc_ketama.c文件中,主要是四个方法:
- ketama_hash 计算某个主机,某个point的hash值
- ketama_item_cmp 比较两个连续区的值,用于在ketama_update 方法中排序
- ketama_update 更新server-pool的分配策略
- ketama_dispatch 找出给定hash值所在的连续区
2.1 连续区
说一下连续区(continuum),参考下图。想象所有md5的值构成下面完整的“环”(没有起点),那么所有md5结果值在环上都有一个固定的位置。
按ketama的算法,在这个环上创建服务器数*160个点,这些点把环分成了同等数量的段。
那么,被插入数据的md5值也一定会落到环的某个区间,以此来判断数据应被写入哪台服务器。
 参考:理想化的Redis集群
参考:理想化的Redis集群
2.2 如何生成ketama_hash
再来看服务器+点的hash值是如何生成的:
alignment的值固定是4,ketama_hash是对由server名+索引组成的md5签名,从第16位开始取值,再重组一个32位值。

static uint32_t
ketama_hash(const char *key, size_t key_length, uint32_t alignment)
{
unsigned char results[16]; md5_signature((unsigned char*)key, key_length, results); return ((uint32_t) (results[3 + alignment * 4] & 0xFF) << 24)
| ((uint32_t) (results[2 + alignment * 4] & 0xFF) << 16)
| ((uint32_t) (results[1 + alignment * 4] & 0xFF) << 8)
| (results[0 + alignment * 4] & 0xFF);
}
下面是调用ketama_hash的代码:
for (x = 0; x < pointer_per_hash; x++) {
value = ketama_hash(host, hostlen, x);
pool->continuum[continuum_index].index = server_index;
pool->continuum[continuum_index++].value = value;
}
每个服务器被分成160个point点,由服务器名+索引组成host值,x值等于160/索引。
这样计算出的服务器各点的值并不是有序的,所以进行排序。
qsort(pool->continuum, pool->ncontinuum, sizeof(*pool->continuum), ketama_item_cmp);
排序后的点值是连续的,但同一服务器的点并不一定连续。这时,所有的值构成了用于一致性hash的环。
2.3、分配Key
由ketama_dispatch实现key值的分配。
可见方法中使用二分法找到一个值在环中的对应区域。
uint32_t
ketama_dispatch(struct continuum *continuum, uint32_t ncontinuum, uint32_t hash)
{
struct continuum *begin, *end, *left, *right, *middle; ASSERT(continuum != NULL);
ASSERT(ncontinuum != 0); begin = left = continuum;
end = right = continuum + ncontinuum; while (left < right) {
middle = left + (right - left) / 2;
if (middle->value < hash) {
left = middle + 1;
} else {
right = middle;
}
}
if (right == end) {
right = begin;
}
return right->index;
}
3、服务器的故障处理
从集群中摘除节点时,ketama的算法不会重新计算"环"。当需要写入故障节点时,会抛出异常。
仔细想一下是合理的,因为摘除的节点持有一部分数据,一般来说是需要恢复的,这是一个前提。
我们假设twemproxy可以感知节点故障,并重新计算分配策略。那么,故障后又有新的数据写入。这时,一部分原本要写入故障节点的数据会被分配到其它节点上。
随后,故障节点恢复,twemproxy又重新调整了分配策略。那么,后写入的那部分数据就不会再被找到(这个有点像内存泄露)。
[转] twemproxy ketama一致性hash分析的更多相关文章
- 【原】 twemproxy ketama一致性hash分析
转贴请注明原帖位置:http://www.cnblogs.com/basecn/p/4288456.html 测试Twemproxy集群,双主双活 向twemproxy集群做写操作时,发现key的分布 ...
- 一致性Hash 分析和实现
一致性Hash 分析和实现 ---title: 1.一致性Hashdate: 2018-02-05 12:03:22categories:- 一致性Hash--- 一下分析来源于网络总结:算法参照自己 ...
- 一致性Hash算法(KetamaHash)的c#实现
Consistent Hashing最大限度地抑制了hash键的重新分布.另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上.因为使用一般的 ...
- SOFA 源码分析 — 负载均衡和一致性 Hash
前言 SOFA 内置负载均衡,支持 5 种负载均衡算法,随机(默认算法),本地优先,轮询算法,一致性 hash,按权重负载轮询(不推荐,已被标注废弃). 一起看看他们的实现(重点还是一致性 hash) ...
- OpenStack_Swift源代码分析——Ring基本原理及一致性Hash算法
1.Ring的基本概念 Ring是swfit中最重要的组件.用于记录存储对象与物理位置之间的映射关系,当用户须要对Account.Container.Object操作时,就须要查询相应的Ring文件( ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 转: memcached Java客户端spymemcached的一致性Hash算法
转自:http://colobu.com/2015/04/13/consistent-hash-algorithm-in-java-memcached-client/ memcached Java客户 ...
- 一致性hash算法在memcached中的使用
一.概述 1.我们的memcacheclient(这里我看的spymemcache的源代码).使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同.仅仅是对我们要存 ...
- 一致性 Hash 在负载均衡中的应用
介 一致性Hash是一种特殊的Hash算法,由于其均衡性.持久性的映射特点,被广泛的应用于负载均衡领域,如nginx和memcached都采用了一致性Hash来作为集群负载均衡的方案.本文将介绍一致性 ...
随机推荐
- yum安装php7.2
文章来源:https://www.cnblogs.com/hello-tl/p/9404655.html 分享一个算是比较完美的php7.2yum安装 0.更换yum原 # yum install e ...
- 与LCD_BPP相关的函数
board/freescale/mx6q_sabresd/mx6q_sabresd.c: panel_info.vl_bpix = LCD_BPP; common/lcd.c: off = ...
- scheduleWithFixedDelay和scheduleAtFixedRate源码分析
先放张图,有兴趣的话我再加细节说明. scheduleWithFixedDelay和scheduleAtFixedRate的执行流程都是一样的,如下 ScheduledThreadPoolExecut ...
- PAT Basic 1039
1039 到底买不买 小红想买些珠子做一串自己喜欢的珠串.卖珠子的摊主有很多串五颜六色的珠串,但是不肯把任何一串拆散了卖.于是小红要你帮忙判断一下,某串珠子里是否包含了全部自己想要的珠子?如果是,那么 ...
- lucene segment的产生,flush, commit与es的refresh,flush
1 segment的产生 当索引一个文档时,如果存在空闲的segment(未被其他线程锁定),则取出空闲segment list中的最后一个segment(LIFO),并锁定,将文档索引至该segme ...
- vuex相关知识点
vuex简单理解转载博客 vuex从入门到入门------state:从 store 实例中读取状态最简单的方法就是在计算属性中返回某个状态------Getters:可以很容易地在任何组件中使用它- ...
- PYDay2-linux基础\常用命令
一.linux 理念 一切皆文件 二.常用命令(150) 2.1.rsync rsync是类unix系统下的数据镜像备份工具, 它的特性如下: 可以镜像保存整个目录树和文件系统. 可以很容易做到保持原 ...
- PHP过滤器 filter_has_var() 函数
定义和用法 filter_has_var() 函数检查是否存在指定输入类型的变量. 如果成功则返回 TRUE,如果失败则返回 FALSE. 语法 filter_has_var(type, variab ...
- 【JavaScript 13—应用总结】:锁屏遮罩
导读:上次说了,当弹出登录框时,由于背景色和弹出框时一样的,这样子,其实比较难聚焦到底该操作哪一块.所以,如果,有了颜色的区分,那么通过屏幕遮罩的效果,就可以将我们希望要被处理的东西突出显示.也就达到 ...
- ajax dome案例
一.首先HTML页面 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...