Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 二
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
创建一个words.txt 文件并上传
vi words.txt Hello World
Hello Tom
Hello Jack
Hello Hadoop
Bye hadoop
将words.txt上传到hdfs的根目录
/home/xupanpan/hadoop/hadoop/bin/hadoop fs -put /home/xupanpan/hadoop/word.txt /

1、配置etc/hadoop/mapred-site.xml:
mv /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
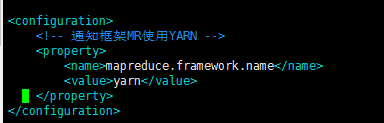
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、配置etc/hadoop/yarn-site.xml:
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/yarn-site.xml

3、YARN的启动
/home/xupanpan/hadoop/hadoop/sbin/start-yarn.sh

http://192.168.20.225:8088/cluster
3、YARN的停止
sbin/stop-yarn.sh
现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
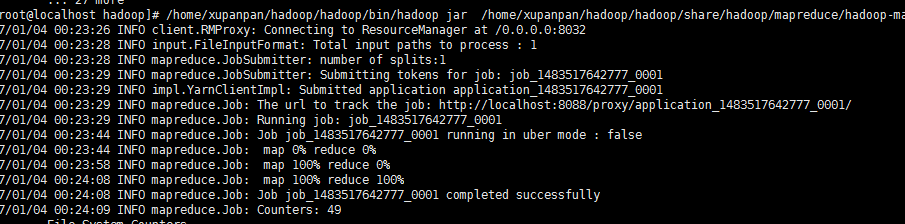
用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:
/home/xupanpan/hadoop/hadoop/bin/hadoop jar /home/xupanpan/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount hdfs://127.0.0.1:9000/word.txt hdfs://127.0.0.1:9000/out


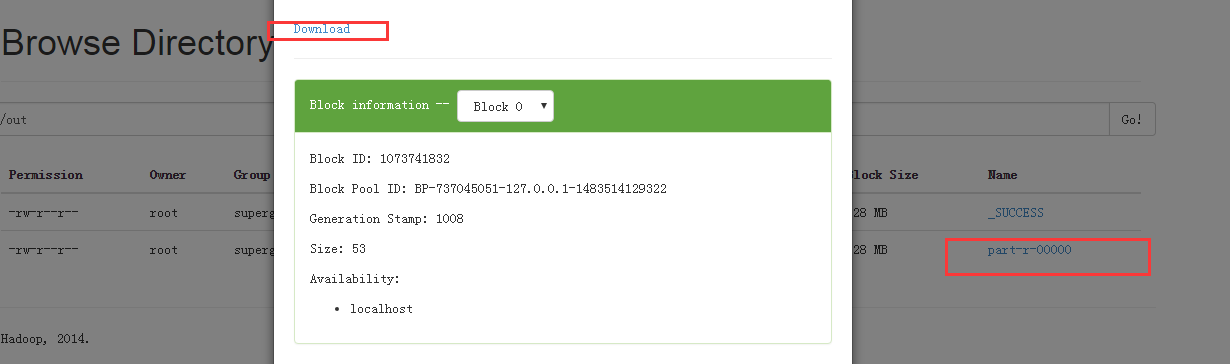

说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。
参考 http://blog.csdn.net/uq_jin/article/details/51451995
Linux Hadoop2.7.3 安装(单机模式) 二的更多相关文章
- Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 java环境安装 http://www.cnblogs.com/zeze/p/590 ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- Ubuntu 14.04下安装Hadoop2.4.0 (单机模式)
转自 http://www.linuxidc.com/Linux/2015-01/112370.htm 一.在Ubuntu下创建Hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增 ...
- 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Hadoop2.6.0安装—单机/伪分布
目录 环境准备 创建hadoop用户 更新apt 配置SSH免密登陆 安装配置Java环境 安装Hadoop Hadoop单机/伪分布配置 单机Hadoop 伪分布Hadoop 启动Hadoop 停止 ...
- linux centos7最小化安装桥接模式网络设置、xshell、xftf
一.网络连接设置1.桥接模式 使用电脑真实网卡,可以和自己的电脑连接,也可以和外部网络连接2.NAT模式 使用wmware network adapter vmnet8虚拟网卡,可以和自己的电脑连接, ...
- hadoop2.6.4 搭建单机模式
注(要先安装jdk,最好jdk版本>=1.7) 安装jdk http://www.cnblogs.com/zhangXingSheng/p/6228432.html 给普通用户添加su ...
- Linux中Postfix邮件安装配置(二)
本套邮件系统的搭建,从如何发邮件到收邮件到认证到虚拟用户虚拟域以及反病毒和反垃圾邮件等都有详细的介绍.在搭建过程中必须的参数解释以及原理都有告诉,这样才能更好地理解邮件系统. 卸载自带postfix ...
随机推荐
- windowsservice
1.创建 windows服务 项目 文件 -> 新建项目 -> 已安装的模板 -> Visual C# -> windows ,在右侧窗口选择"windows 服务 ...
- 【转】oracle中rowid的用法 (全面)
ROWID是数据的详细地址,通过rowid,oracle可以快速的定位某行具体的数据的位置. ROWID可以分为物理rowid和逻辑rowid两种.普通的堆表中的rowid是物理rowid,索引组织表 ...
- Mac锁屏
http://www.dbform.com/html/2006/192.html 应用程序-实用工具-钥匙锁-菜单栏中的钥匙串访问-偏好设置-选中“在菜单栏中显示钥匙串”
- IT
http://www.cnblogs.com/TomXu/archive/2011/12/19/2291448.html " 经常从Recruiter那里得到抱怨:“汤姆,为什么面试者每次回 ...
- Python for Infomatics 第13章 网页服务二(译)
注:文章原文为Dr. Charles Severance 的 <Python for Informatics>.文中代码用3.4版改写,并在本机测试通过. 13.4 JavaScript ...
- Python列表和元组
Python是没有数组的概念,但是和数组比较相近的概念是列表和元素. 下面两个例子展示列表和元组. # coding=utf-8 # 元组 students = ('小明', '小黄', '小李', ...
- js闭包-在你身边却不知
今天组里小伙很纳闷的问了我js绑事件带出的一个小问题,随便聊聊闭包那点事,背景如下: 当点击Button的时候给li绑定事件,事件的大概内容是获取li位置的index再做点事,据他描述代码看上去也没错 ...
- wex5中的星星评分
新建一个空白的.w文件,然后在页面上放5个img星星图片 重要的是图片路径不能是绝对路径,要用相对路径,不然js操作的时候会出bug 添加两个label标签(标签随你挑,在这我就用label) 你到时 ...
- 解决Android界面布局添加EditText组件后界面无法预览
错误报告: Exception raised during rendering: java.lang.System.arraycopy([CI[CII)V Exception details are ...
- day 2 Linux基础
6.用户.群组和权限 1) 新建用户natasha,uid为1000,gid为555,备注信息为"master" useradd natasha usermod -u1000 na ...