机器学习 - 算法 - PCA 主成分分析
PCA 主成分分析
原理概述
用途 - 降维中最常用的手段
目标 - 提取最有价值的信息( 基于方差 )
问题 - 降维后的数据的意义 ?
所需数学基础概念
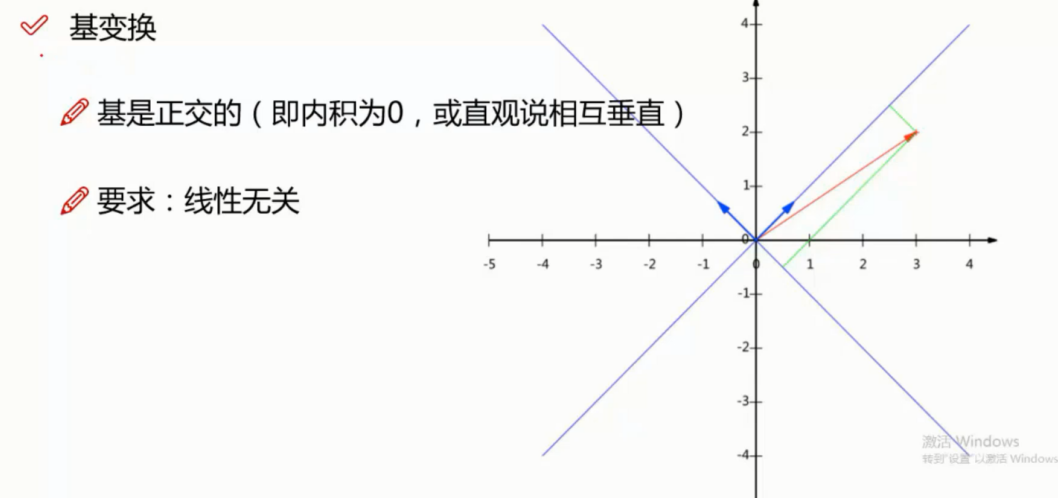
向量的表示


基变换

协方差矩阵

协方差

优化目标


降维实例

代码实现
"""
这里假设原始数据集为矩阵 dataMat,其中每一行代表一个样本,每一列代表同一个特征(与上面的介绍稍有不同,上 面是每一列代表一个样本,每一行代表同一个特征)。
""" import numpy as np ################################
# (1)零均值化
################################
def zeroMean(dataMat):
meanVal=np.mean(dataMat,axis=0) #按列求均值(axis=0),即求各个特征的均值
newData=dataMat-meanVal
return newData,meanVal # newData是零均值化后的数据,meanVal是每个特征的均值 ################################
# (2)求协方差矩阵
# 若rowvar=0,说明传入的数据一行代表一个样本;
# 若非0,说明传入的数据一列代表一个样本。
################################
newData,meanVal=zeroMean(dataMat)
covMat=np.cov(newData,rowvar=0) ################################
# (3)求特征值和特征矩阵
# eigVals存放特征值,行向量
# eigVects存放特征向量,每一列带别一个特征向量
# 特征值和特征向量是一一对应的
################################
eigVals,eigVects=np.linalg.eig(np.mat(covMat)) ################################
# (4)保留比较大的前n个特征向量
# 第三步得到了特征值向量eigVals,假设里面有m个特征值,我们可以对其排序,排在前面的n个特征值所对应的特征 # 向量就是我们要保留的,它们组成了新的特征空间的一组基n_eigVect
################################
eigValIndice=np.argsort(eigVals) #对特征值从小到大排序
n_eigValIndice=eigValIndice[-1:-(n+1):-1] #最大的n个特征值的下标,首先argsort对特征值是从小到大排序的,那么最大的n个特征值就排在后面,所以eigValIndice[-1:-(n+1):-1]就取出这个n个特征值对应的下标(python里面,list[a:b:c]代表从下标a开始到b,步长为c)
n_eigVect=eigVects[:,n_eigValIndice] #最大的n个特征值对应的特征向量 ################################
# (5)获取降维后的数据
# 将零均值化后的数据乘以n_eigVect就可以得到降维后的数据
################################
lowDDataMat=newData*n_eigVect #低维特征空间的数据
reconMat=(lowDDataMat*n_eigVect.T)+meanVal #重构数据
相关模块方法
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)
参数
- n_components: int, float, None 或 string,PCA算法中所要保留的主成分个数,保留下来的特征数
- 如果 n_components = 1,将把原始数据降到一维;
- 如果赋值为string,如n_components='mle',将自动选取特征个数,使得满足所要求的方差百分比;
- 如果没有赋值,默认为None,特征个数不会改变(特征数据本身会改变)。
- copy:True 或False
- 默认为True,即是否需要将原始训练数据复制。
- whiten:True 或False
- 默认为False,即是否白化,使得每个特征具有相同的方差
对象属性
- explained_variance_ratio_:返回所保留各个特征的方差百分比,
- 如果n_components没有赋值,则所有特征都会返回一个数值且解释方差之和等于1。
- n_components_:返回所保留的特征个数
常用方法
- fit(X): 用数据X来训练PCA模型。
- fit_transform(X):用X来训练PCA模型,同时返回降维后的数据。
- inverse_transform(newData) :将降维后的数据转换成原始数据,但可能不会完全一样,会有些许差别。
- transform(X):将数据X转换成降维后的数据,当模型训练好后,对于新输入的数据,也可以用transform方法来降维
使用示例
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=2)
newX = pca.fit_transform(X)
print(X)
[[-1 -1]
[-2 -1]
[-3 -2]
[ 1 1]
[ 2 1]
[ 3 2]]
print(newX)
array([[ 1.38340578, 0.2935787 ],
[ 2.22189802, -0.25133484],
[ 3.6053038 , 0.04224385],
[-1.38340578, -0.2935787 ],
[-2.22189802, 0.25133484],
[-3.6053038 , -0.04224385]])
print(pca.explained_variance_ratio_)
[ 0.99244289 0.00755711]
可以看出 第一个特征的占比达到了 99% 因此优化特征为1 即可
pca = PCA(n_components=1)
newX = pca.fit_transform(X)
print(pca.explained_variance_ratio_)
[ 0.99244289]
PCA 总结
优点
1) 仅仅依靠方差衡量信息量,不受数据集以外的因素影响
2)各主成分之间相互正交,可消除原始数据成分间的相互影响的因素
3)计算方法简单,主要运用特征值分解
缺点
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
2)方差小的主成分也有可能含有对样本差异的重要信息,由于降维丢弃可能会对后续数据处理有影响
机器学习 - 算法 - PCA 主成分分析的更多相关文章
- 机器学习算法-PCA降维技术
机器学习算法-PCA降维 一.引言 在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特 ...
- 机器学习之PCA主成分分析
前言 以下内容是个人学习之后的感悟,转载请注明出处~ 简介 在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性.人们自然希望变量个数较少而得到的 信息较多.在很 ...
- 降维算法-PCA主成分分析
1.PCA算法介绍主成分分析(Principal Components Analysis),简称PCA,是一种数据降维技术,用于数据预处理.一般我们获取的原始数据维度都很高,比如1000个特征,在这1 ...
- 数学之路(3)-机器学习(3)-机器学习算法-PCA
PCA 主成分分析(Principal components analysis,PCA),维基百科给出一个较容易理解的定义:“PCA是一个正交化线性变换,把数据变换到一个新的坐标系统中,使得这一数据的 ...
- 【模式识别与机器学习】——PCA主成分分析
基本思想 其基本思想就是设法提取数据的主成分(或者说是主要信息),然后摒弃冗余信息(或次要信息),从而达到压缩的目的.本文将从更深的层次上讨论PCA的原理,以及Kernel化的PCA. 引子 首先我们 ...
- 机器学习算法总结(九)——降维(SVD, PCA)
降维是机器学习中很重要的一种思想.在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”.另 ...
- PCA主成分分析算法的数学原理推导
PCA(Principal Component Analysis)主成分分析法的数学原理推导1.主成分分析法PCA的特点与作用如下:(1)是一种非监督学习的机器学习算法(2)主要用于数据的降维(3)通 ...
- Coursera在线学习---第八节.K-means聚类算法与主成分分析(PCA)
一.K-means聚类中心初始化问题. 1)随机初始化各个簇类的中心,进行迭代,直到收敛,并计算代价函数J. 如果k=2~10,可以进行上述步骤100次,并分别计算代价函数J,选取J值最小的一种聚类情 ...
- PCA主成分分析+白化
参考链接:http://deeplearning.stanford.edu/wiki/index.php/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90 h ...
随机推荐
- 关于MySQL中的锁机制详解
锁概述 MySQL的锁机制,就是数据库为了保证数据的一致性而设计的面对并发场景的一种规则. 最显著的特点是不同的存储引擎支持不同的锁机制,InnoDB支持行锁和表锁,MyISAM支持表锁. 表锁就是把 ...
- Linux学习之五-Linux系统终端常用的快捷键
Linux系统终端常用的快捷键 (使用快捷键能大大提高效率,部分用在远程登录的工具如Xshell下) 剪切板操作(终端不支持,因为终端是纯命令行) Ctrl+insert 复制 Shift+i ...
- Oracle前期工具【1】
目录: 1.oracle下载安装[Oracle11g] 2.Oracle客户端工具下载安装 [sqldeveloper.exe] 3.cmd进入Oracle命令界面操作 4.客户端图形化命令操作 or ...
- zookeeper入门(1)---基本概念
转载 : https://blog.csdn.net/java_66666/article/details/81015302 一. zookeeper概念 它是一个分布式服务框架,是Apache Ha ...
- python_面向对象——类方法和静态方法
1.类方法不能访问实例变量,只能访问类变量. class Dog(object): name = 'wdc' def __init__(self,name): self.name = name def ...
- 中文日历Calendar
一.层次结构 Object<-----Calendar<-----EastAsianLunisolarCalendar<-----ChineseLunisolarCalendar(农 ...
- concat以及group_concat的用法
concat()函数 1.功能:将多个字符串连接成一个字符串. 2.语法:concat(str1, str2,...) 返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null ...
- GO 文件读取常用的方法
方式1: 一行一行的方式读取 其中常用的方法就有:ReadString,ReadLine,ReadBytes ReadLine 返回单个行,不包括行尾字节,就是说,返回的内容不包括\n或者\r\n,返 ...
- KM 最大权匹配 UVA 1411/POJ 3565
#include <bits/stdc++.h> using namespace std; inline void read(int &num) { char ch; num = ...
- [go] 循环与函数
练习:循环与函数 为了练习函数与循环,我们来实现一个平方根函数:用牛顿法实现平方根函数. 计算机通常使用循环来计算 x 的平方根.从某个猜测的值 z 开始,我们可以根据 z² 与 x 的近似度来调整 ...