爬虫遇到IP访问频率限制的解决方案
背景:
大多数情况下,我们遇到的是访问频率限制。如果你访问太快了,网站就会认为你不是一个人。这种情况下需要设定好频率的阈值,否则有可能误伤。如果大家考过托福,或者在12306上面买过火车票,你应该会有这样的体会,有时候即便你是真的用手在操作页面,但是因为你鼠标点得太快了,它都会提示你: “操作频率太快...”。
遇到这种网页,最直接的办法是限制访问时间。例如每隔5秒钟访问一次页面。但是如果遇到聪明一点的网站,它检测到你的访问时间,这个人访问了几十个页面,但是每次访问都刚好5秒钟,人怎么可能做到这么准确的时间间隔?肯定是爬虫,被封也是理所当然的!所以访问时间间隔你可以设定为一个随机值,例如0到10之间的随机秒数。
当然,如果遇到限制访问频率的网站,我们使用Selenium来访问就显得比较有优势了,因为Selenium这个东西打开一个页面本身就需要一定的时间,所以我们因祸得福,它的效率低下反而让我们绕过了频率检查的反爬虫机制。而且Selenium还可以帮我们渲染网页的JavaScript,省去了人工分析JavaScript源代码的麻烦,可谓一举两得。
下面是我经常使用的修改访问频率的几种场景,供大家参考:
1、Request 单机版爬虫:
上面的代码可以放在request请求之后

2、scrapy 单机版爬虫或者scrapy_redis分布式爬虫

在这里设置请求间隔时间,其他参数的讲解,我会更新到新的博文中,敬请大家期待
另外,不明确 scapy 和 scrapy_redis 区别的朋友们,可以移步到这里
https://www.cnblogs.com/beiyi888/p/11283823.html
3、有一种情况可以忽略
有些网站,比如在我之前遇到过的这种网站(hwt),服务器会限制你的访问频率,但是并不会封IP,页面将持续显示403(服务器拒绝访问),偶尔显示200(请求成功),那么就证明(前提是我们设置过请求头等信息),这样的反爬机制,只是限制了请求的频率,但是并不会影响到正常的采集,当然这样的情况也不多见,所以我们要学会针对性地写爬虫。
4、某些服务器由于性能原因,响应较慢(会导致响应超时,从而终止请求)
这种场景一般出现在小网站较多,如(DYW),在我们将请求的参数都安排好之后,却发现,由于服务器的性能原因,采集程序持续报网页404,出现这种情况我们只能延长响应超时的时长,如下图所示:

5、代理IP或者分布式爬虫:
如果对页的爬虫的效率有要求,那就不能通过设定访问时间间隔的方法来绕过频率检查了。
代理IP访问可以解决这个问题。如果用100个代理IP访问100个页面,可以给网站造成一种有100个人,每个人访问了1页的错觉。这样自然而然就不会限制你的访问了。
代理IP经常会出现不稳定的情况。你随便搜一个“免费代理”,会出现很多网站,每个网站也会给你很多的代理IP,但实际上,真正可用的代理IP并不多。你需要维护一个可用的代理IP池,但是一个免费的代理IP,也许在你测试的时候是可以使用的,但是几分钟以后就失效了。使用免费代理IP是已经费时费力,而且很考验你运气的事情。
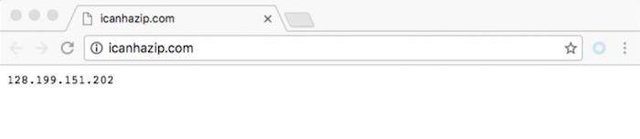
大家可以使用http://icanhazip.com/ 这个网站来检测你的代理IP是否设定成功。当你直接使用浏览器访问这个网站的时候,它会返回你的IP地址。如下图所示:
通过requests,我们可以设置代理访问网站,在requests的get方法中,有一个proxies参数,它接收的数据是一个字典,在这个字典中我们可以设置代理。
大家可以在requests的官方中文文档中看到关于设置代理的更多信息:http://docs.python-requests.org/zh_CN/latest/user/advanced.html#proxies
我选择第一个HTTP类型的代理来给大家做测试,运行效果如下图所示:
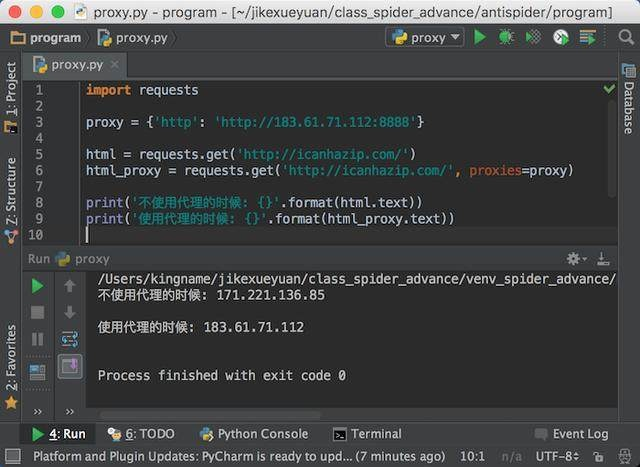
从上图可以看出,我们成功通过了代理IP来访问网站。
我们还可以使用分布式爬虫。分布式爬虫会部署在多台服务器上,每个服务器上的爬虫统一从一个地方拿网址。这样平均下来每个服务器访问网站的频率也就降低了。由于服务器是掌握在我们手上的,因此实现的爬虫会更加的稳定和高效。这也是我们这个课程最后要实现的目标。
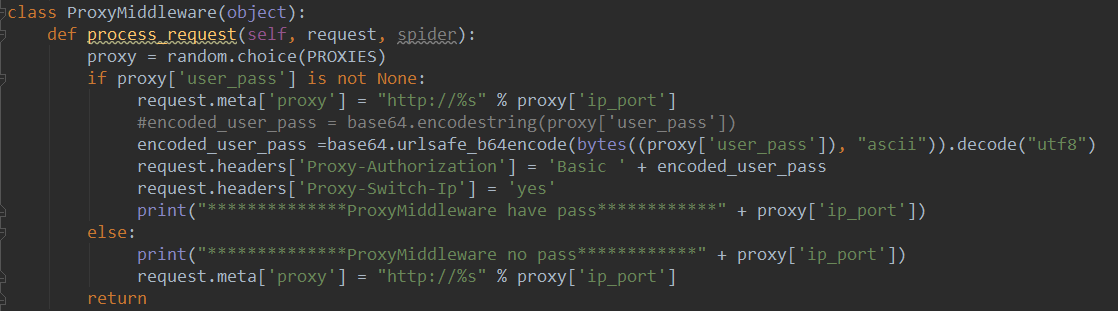
那么分布式的爬虫,动态代理IP是在settings.py中设置的,如下图:

然后在这里调用

最终是在middlewares.py中生效
有一些网站,他们每个相同类型的页面的源代码格式都不一样,我们必需要针对每一个页面写XPath或者正则表达式,这种情况就比较棘手了。如果我们需要的内容只是文本,那还好说,直接把所有HTML标签去掉就可以了。可是如果我们还需要里面的链接等等内容,那就只有做苦力一页一页的去看了。
爬虫遇到IP访问频率限制的解决方案的更多相关文章
- C# 站点IP访问频率限制 针对单个站点
0x00 前言 写网站的时候,或多或少会遇到,登录,注册等操作,有时候,为了防止别人批量进行操作,不得不做出一些限制IP的操作(当前也可以用于限制某个账号的密码校验等). 这样的简单限制,我们又不想对 ...
- IP访问频率限制不能用数组循环插入多个限制条件原因分析及解决方案
14.IP频率限制不能用数组循环插入多个限制条件原因分析及解决方案: define("RATE_LIMITING_ARR", array('3' => 3, '6' => ...
- nginx单个ip访问频率限制
一.限制所有单个ip的访问频率 1.http中的配置 http { #$limit_conn_zone:限制并发连接数 limit_conn_zone $binary_remote_addr zone ...
- nginx 限制ip访问频率和限速 (摘录)
限制某个IP同一时间段的访问次数 如何设置能限制某个IP某一时间段的访问次数是一个让人头疼的问题,特别面对恶意的ddos攻击的时候.其中CC攻击(Challenge Collapsar)是DDOS(分 ...
- java爬虫进阶 —— ip池使用,iframe嵌套,异步访问破解
写之前稍微说一下我对爬与反爬关系的理解 一.什么是爬虫 爬虫英文是splider,也就是蜘蛛的意思,web网络爬虫系统的功能是下载网页数据,进行所需数据的采集.主体也就是根据开始的超链接,下 ...
- IIS限制ip访问
1.禁止IP访问 http://jingyan.baidu.com/article/22fe7ced0462633002617f39.html 2.限制IP访问频率 http://q.cnblogs. ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- ARM 虚拟机使用同一个公共 IP 访问公网的解决方案
ARM 虚拟机使用同一个公共 IP 访问公网的解决方案 2017-2-21 作者 Azure 目前有两种部署模型:资源管理器 ARM 和经典部署模型 ASM.ASM 的虚拟机默认公用云服务的 VIP ...
- 可能是一份没什么用的爬虫代理IP指南
写在前面 做爬虫的小伙伴一般都绕不过代理IP这个问题. PS:如果还没遇到被封IP的场景,要不就是你量太小人家懒得理你,要不就是人家压根不在乎... 爬虫用户自己是没有能力维护一系列的代理服务器和代理 ...
随机推荐
- Android通过adb shell am broadcast发送广播 参数说明
通过命令行执行adb shell am broadcast发送广播通知. adb shell am broadcast 后面的参数有: <INTENT> specifications in ...
- C++内容记录
仅个人记录 https://ke.qq.com/course/336509 M了个J - 博客园 https://www.cnblogs.com/mjios/
- 无法下载golang.org-x-net解决方法
由于go的很多包都依赖了google官方的包,而google官方的包都在google服务器上,因为某些原因无法直接访问,在搜索了很多解决方案后,找到了最简单的一个方法: 1. 找到对应包在github ...
- kotlin中类型检查和类型转换
is 和!is操作符,可以在运行时检查一个对象与一个给定的类型是否一致,或者使用与它相反的!is操作符 fun main(arg: Array<String>) { var a :Any= ...
- 自定义msi安装包的执行过程
有时候我们需要在程序中执行另一个程序的安装,这就需要我们去自定义msi安装包的执行过程. 比如我要做一个安装管理程序,可以根据用户的选择安装不同的子产品.当用户选择了三个产品时,如果分别显示这三个产品 ...
- smart_pointer example
#pragma oncetemplate<typename T>class smart_pointer{private: T* m_pRawPointer;public: smart_po ...
- 【UI】数据表格设计
https://www.smashingmagazine.com/2019/02/complex-web-tables/ https://www.smashingmagazine.com/2019/0 ...
- 编译bitcoin比特币客户端
我遇到了两个不太容易解决的问题. 问题一: checking for Berkeley DB C++ headers... default configure: error: Found Berkel ...
- nginx反向代理本地 单台wed -使用域名代理
环境: 本地外网ip:123.58.251.166 .配置index.html网页 [root@host---- conf.d]# cat /web/sing/index.html <h1> ...
- openssl交叉编译
目录 openssl交叉编译 title: openssl交叉编译 date: 2019/12/18 21:09:33 toc: true --- openssl交叉编译 tar xvf openss ...