使用XPath爬取网页数据
我们以我的博客为例,来爬取我所有写过的博客的标题。
首先,打开我的博客页面,右键“检查”开始进行网页分析。我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点击Copy XPath,即可获得对应的XPath编码,我们可以先将它保存在一个文本文档中。
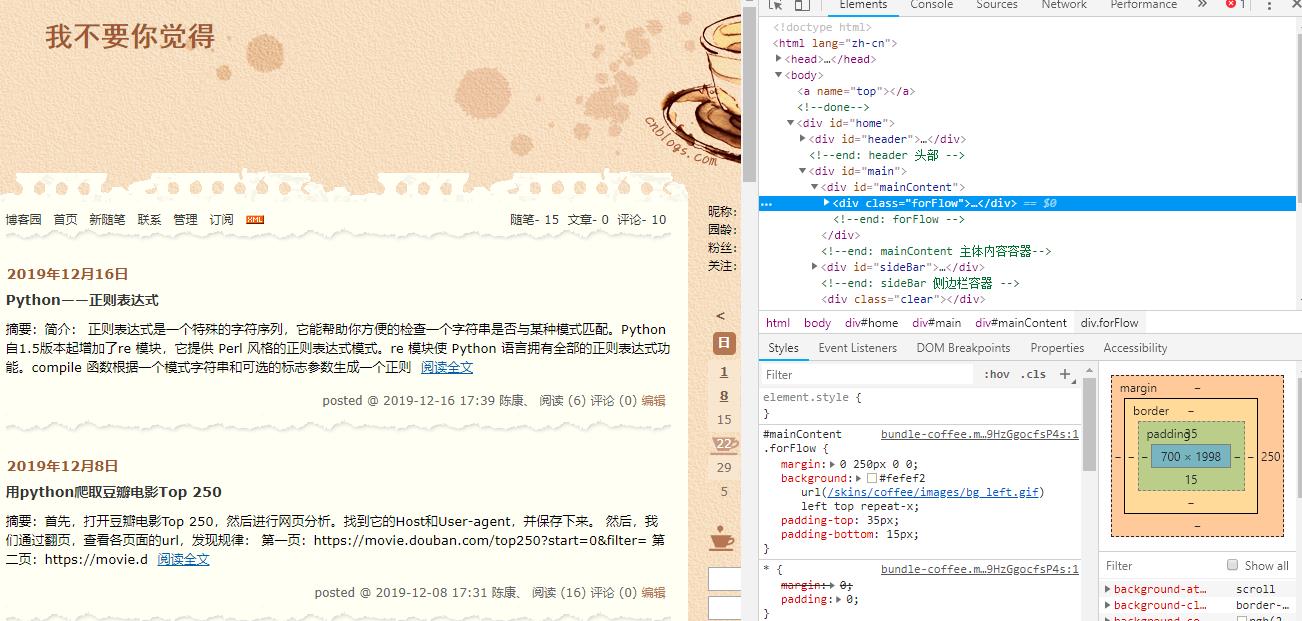
我们再多次对各个标题重复以上操作,即可得到关于标题的XPath编码的规律。我们不难看出,对于我的博客的标题的XPath编码格式为“//*[@id="mainContent"]/div/div[n]/div[2]/a”。
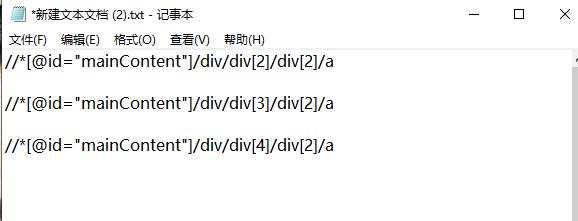
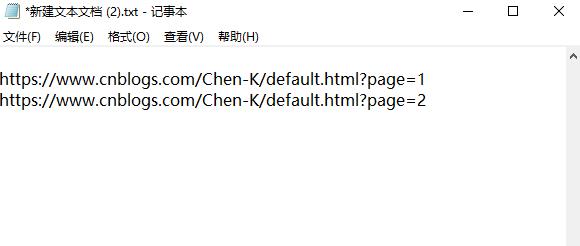
又因为我的博客共有2页,所以我们还需找到网页url的规律,经过分析,我们发现格式为'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)。
下面便可开始写代码:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
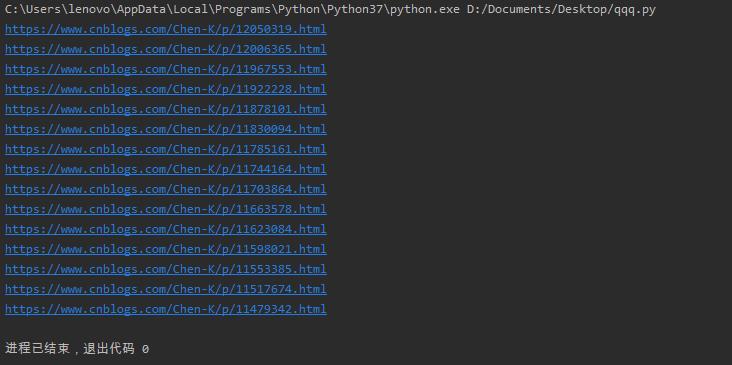
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/text()') # 加text()是为了将结果以txt格式输出
for j in a:
print(j)
运行结果:

若是要爬取其他的数据,我们只需复制下来相应的XPath编码即可。操作过程大同小异,我们便不再多加赘述,下面我们以爬取每个博客的url为例:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/@href')
for j in a:
print(j)
运行结果:
XPath与BeautifulSoup相比,操作更加简单,代码也更为简洁,如果需要爬取比较多的信息,使用XPath将会大大减少我们的工作量。当然,我们想要使用XPath,必须先安装lxml库,而我们有两个方法可以安装lxml库。
1、使用pip安装
我们只需打开命令行,输入指令“pip install lxml”,然后等待安装即可。
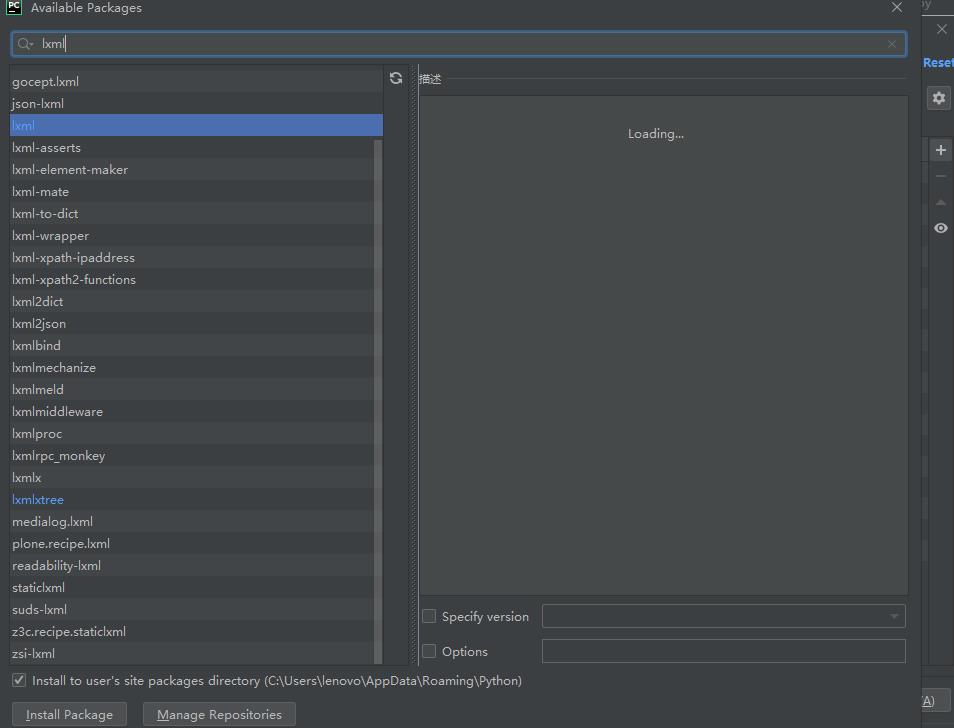
2、使用PyCharm安装
我们点击“文件”,找到设置,打开后点击右边的加号,然后在上面的搜索框中输入lxml,然后点击下方install,等待安装即可。
安装好lxml库之后,我们便可以使用其相关功能了。
使用XPath爬取网页数据的更多相关文章
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 【推荐】oc解析HTML数据的类库(爬取网页数据)
TFhpple是一个用于解析html数据的第三方库,本人感觉功能还算可以,只不过在使用前必须配置项目. 配置 1.导入libxml2.tbd 2.设置编译路径 使用 这里使用一个例子来说明 http: ...
- 使用puppeteer爬取网页数据实践小结
简单介绍Puppeteer Puppeteer是一个Node库,它通过DevTools协议提供高级API来控制Chrome或Chromium.Puppeteer默认以无头方式运行,但可以配置为有头方式 ...
随机推荐
- Heat map 绘图神奇
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149(博主视频教学主 ...
- Netty解码器相关文章
最通用TCP黏包解决方案:LengthFieldBasedFrameDecoder和LengthFieldPrepender https://blog.csdn.net/u010853261/arti ...
- Vue生命周期钩子函数加载顺序的理解
Vue实例有一个完整的生命周期,也就是从开始创建.初始化数据.编译模板.挂载Dom.渲染→更新→渲染.卸载等一系列过程,我们称这是Vue的生命周期.通俗说就是Vue实例从创建到销毁的过程,就是生命周期 ...
- 自己动手写Android插件化框架
自己动手写Android插件化框架 转 http://www.imooc.com/article/details/id/252238 最近在工作中接触到了Android插件内的开发,发现自己这种技 ...
- Qt编写自定义控件20-自定义饼图
前言 上次在写可视化数据大屏电子看板项目的时候,为了逐步移除对QChart的依赖(主要是因为QChart真的太垃圾了,是所有Qt的模块中源码最烂的一个,看过源码的人没有一个不吐槽,不仅不支持10W级别 ...
- LeetCode_9. Palindrome Number
9. Palindrome Number Easy Determine whether an integer is a palindrome. An integer is a palindrome w ...
- 使用xdebug调试程序后程序很慢的原因
有一个原因就是开启调试的会话没有正确的关闭,即PhpStorm这边关闭了而没有通知服务端xdebug关闭,导致服务器资源被耗尽,这时只有重启服务端的服务才可以. 所以必须保证每一个调试会话被正确关闭. ...
- modbus4j中使用modbus tcp/ip和modbus rtu over tcp/ip模式
通过借鉴高人博客,总结如下: 1. TcpMaster类,用于生成ModbusMaster主类 package sun.sunboat; public class TcpMaster { privat ...
- Linux 之 awk文本分析工具
AWK是一种处理文本文件的语言,是一个强大的文本分析工具.Linux环境中自带. awk调用方法 命令行 awk [-F field-separator] 'commands' input-file( ...
- 最新 映客java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.映客等10家互联网公司的校招Offer,因为某些自身原因最终选择了映客.6.7月主要是做系统复习.项目复盘.LeetCode ...