使用XPath爬取网页数据
我们以我的博客为例,来爬取我所有写过的博客的标题。
首先,打开我的博客页面,右键“检查”开始进行网页分析。我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点击Copy XPath,即可获得对应的XPath编码,我们可以先将它保存在一个文本文档中。
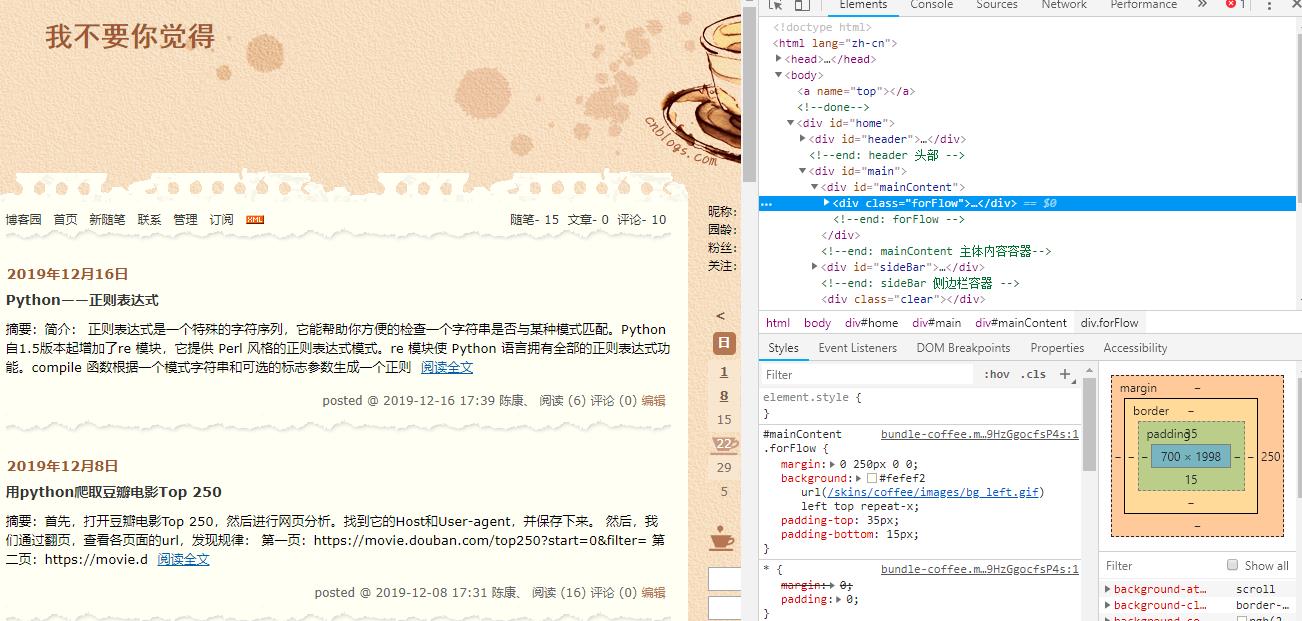
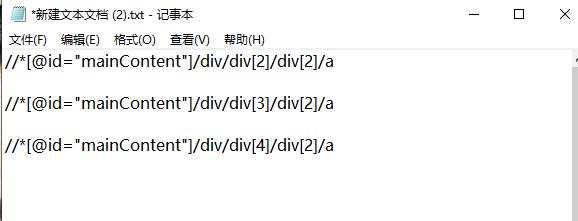
我们再多次对各个标题重复以上操作,即可得到关于标题的XPath编码的规律。我们不难看出,对于我的博客的标题的XPath编码格式为“//*[@id="mainContent"]/div/div[n]/div[2]/a”。
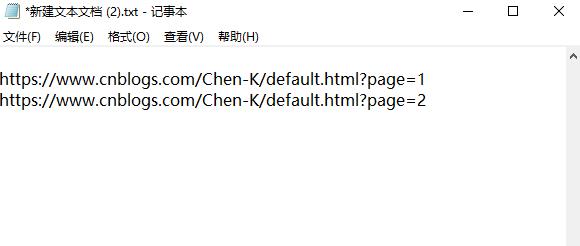
又因为我的博客共有2页,所以我们还需找到网页url的规律,经过分析,我们发现格式为'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)。
下面便可开始写代码:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
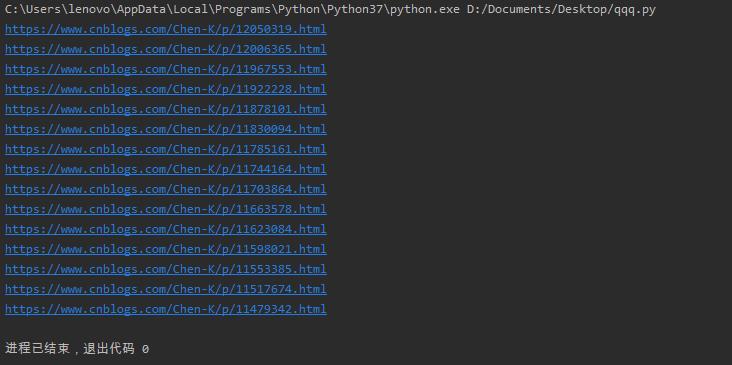
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/text()') # 加text()是为了将结果以txt格式输出
for j in a:
print(j)
运行结果:

若是要爬取其他的数据,我们只需复制下来相应的XPath编码即可。操作过程大同小异,我们便不再多加赘述,下面我们以爬取每个博客的url为例:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/@href')
for j in a:
print(j)
运行结果:
XPath与BeautifulSoup相比,操作更加简单,代码也更为简洁,如果需要爬取比较多的信息,使用XPath将会大大减少我们的工作量。当然,我们想要使用XPath,必须先安装lxml库,而我们有两个方法可以安装lxml库。
1、使用pip安装
我们只需打开命令行,输入指令“pip install lxml”,然后等待安装即可。
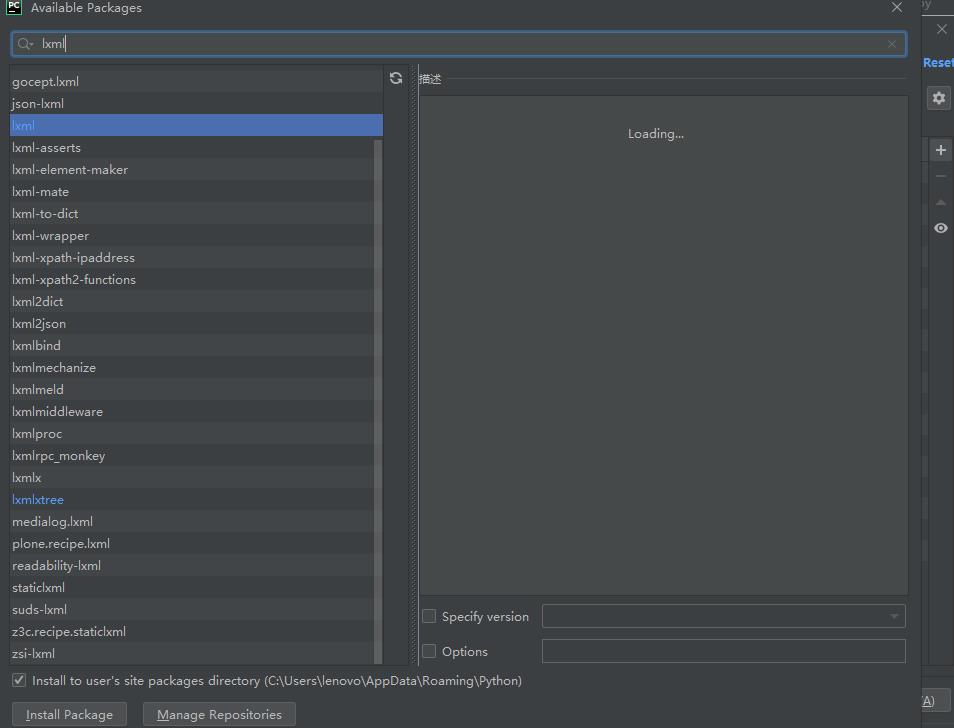
2、使用PyCharm安装
我们点击“文件”,找到设置,打开后点击右边的加号,然后在上面的搜索框中输入lxml,然后点击下方install,等待安装即可。
安装好lxml库之后,我们便可以使用其相关功能了。
使用XPath爬取网页数据的更多相关文章
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 【推荐】oc解析HTML数据的类库(爬取网页数据)
TFhpple是一个用于解析html数据的第三方库,本人感觉功能还算可以,只不过在使用前必须配置项目. 配置 1.导入libxml2.tbd 2.设置编译路径 使用 这里使用一个例子来说明 http: ...
- 使用puppeteer爬取网页数据实践小结
简单介绍Puppeteer Puppeteer是一个Node库,它通过DevTools协议提供高级API来控制Chrome或Chromium.Puppeteer默认以无头方式运行,但可以配置为有头方式 ...
随机推荐
- 如何丧心病狂的使用python爬虫读小说
写在前边 其实一直想入门python很久了,慕课网啊,菜鸟教程啊python的基础的知识被我翻了很多遍了,但是一直没有什么实践.刚好,这两天被别人一直安利一本小说<我可能修的是假仙>,还在 ...
- 关于OpenCL中三重循环的执行次序
源自OpenGPU社区的一个帖子的讨论: 一个有意思的openCL问题
- jack语言编译器的实现过程
目录: 1, 背景介绍
- Vue 2.x指令综合小练习
实现效果如下: 代码实现如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- CockroachDB学习笔记——[译]CockroachDB中的SQL:映射表中数据到键值存储
CockroachDB学习笔记--[译]CockroachDB中的SQL:映射表中数据到键值存储 原文标题:SQL in CockroachDB: Mapping Table Data to Key- ...
- Data - 大数据生态圈
本文内容来自网络,对原文内容和格式做了细微调整,并配图以便阅读理解. 如想查看初始信息,请点击原文. 00 引言 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单 ...
- springmvc项目 logback.xml配置 logstash日志收集
配置logback,需要一个转接的Appender,可以通过Maven依赖加到项目中: <dependency> <groupId>com.cwbase</groupId ...
- 【AMAD】django-taggit -- 一个简单的,通用的django tagging模块
简介 个人评分 简介 django-taggit1是一个通用的,易用的标签系统. from django.db import models from taggit.managers import Ta ...
- power bi可视化--乘用车案例
- Elasticsearch 环境配置
1.下载启动Elasticsearch Elasticsearch下载地址: https://www.elastic.co/cn/downloads/elasticsearch (2) Run ...