markdown文本编辑器--核心功能(解析和渲染)
开源项目地址
欢迎提交 PR、Issue、Star ️!
1. 简述
YtyMark-java项目分为两大模块:
UI界面(ytyedit-mark)
markdown文本解析和渲染(ytymark)
本文主要内容为核心模块--markdown文本解析和渲染。
关于markdown文本解析器怎么设计,渲染器怎么实现,怎么解耦解析和渲染。在这整个流程中,如果通过设计模式实现高内聚低耦合,可重用,易于阅读,易于扩展,易于维护等。
该模块的主要目录结构:
YtyMark-java
├── ytymark/
│ ├── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ ├── annotation/ # 自定义注解
│ │ │ │ ├── enums/ # 枚举值
│ │ │ │ ├── node/ # 树节点(块级和行级节点)
│ │ │ │ ├── parser/ # 解析器(块级和行级元素)
│ │ │ │ ├── renderer/ # 渲染器(块级和行级元素)
│ │ │ └── resources/
│ ├── README.md
│ └──pom.xml
2.解析器
目标:将 Markdown 文本解析为节点树。
使用到的设计模式:
构建者模式:创建复杂解析器和渲染器。
状态模式:对markdown文本不同语法做一些前置处理,裁剪成块级元素。
责任链模式:按优先级匹配不同,处理复杂的块级元素解析及嵌套解析。
策略模式:动态选择解析器完成行内元素的解析。
组合模式:表示 Markdown 语法结构(如段落、标题、列表)之间的树形结构。
迭代器模式:通过迭代器结合递归来遍历节点树,遍历块级元素进行行内元素解析。
根据使用顺序逐一讲述。
2.1. 构建者模式
通过构建者模式来创建复杂的解析器和渲染器,包括自定义解析器的加入。
最简单的解析器(默认支持的语法解析器)和HTML渲染器
// 构建解析器
Parser parser = ParserBuilder.builder().build();
// 构建渲染器
Renderer renderer = RendererBuilder.builder().build(HtmlRenderer.class);
加入自定义块级元素解析器或者行级元素的解析器:
Parser parser = ParserBuilder.builder()
.addDelimiter("_")
.addBlockParser(new ParagraphParserHandler())
.addInlineParser("_", new ItalicParser())
.build();
除此之外,程序会在启动时,扫描org.ytymark.parser包中带有注解BlockParserHandlerType的类,所以还可以通过注解加入新的块级元素解析器。
比如表格解析器:只需要在块解析器类上面加入这个注解和对应的枚举类即可
// 枚举类
public enum BlockParserHandlerEnum {
TABLE("TABLE",6),
// 通过注解加入块级元素解析器
@BlockParserHandlerType(type = BlockParserHandlerEnum.TABLE)
public class TableParserHandler extends AbstractBlockParser implements ParserHandler {
2.2. 状态模式
对markdown文本不同语法做一些前置处理,裁剪成块级元素。
在正式进行块级元素解析前,对原始markdown文本进行分割,分割成一块一块的。
由于markdown语法很多,不进行一些设计,那将是一坨难以阅读理解、难以维护和扩展的代码。
通过状态模式实现类似状态机的机制,当状态(语法)匹配时,自动流转到专门处理这个语法的程序,处理完之后分割成一个“块”(这个块就是一个块元素),再回到默认状态,然后继续处理后续的文本。具体代码位于:org.ytymark.parser.block.state包。
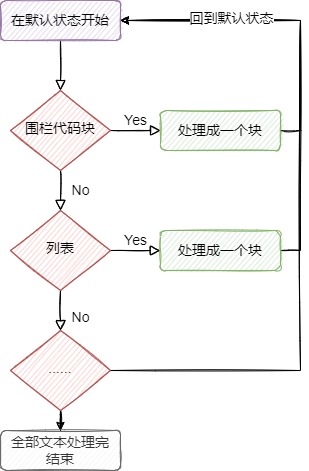
2.3. 责任链模式
按优先级匹配不同,处理复杂的块级元素解析及嵌套解析。
在正式进行块级元素解析前,状态模式将元素文本处理成块数据集合,这就像流水线上简单的打了包,但并不区分包裹里面是什么内容。接着将这些包裹丢上流水线(责任链)上,责任链根据程序初始化时定好的顺序,逐一检测包裹里的内容是什么,匹配得上的就直接丢给机器处理(解析),最终给包裹打上标签(包装成节点对象)。对应包裹里还有包裹的,便继续丢回流水线上进行打标签。
整个处理流程,如图:
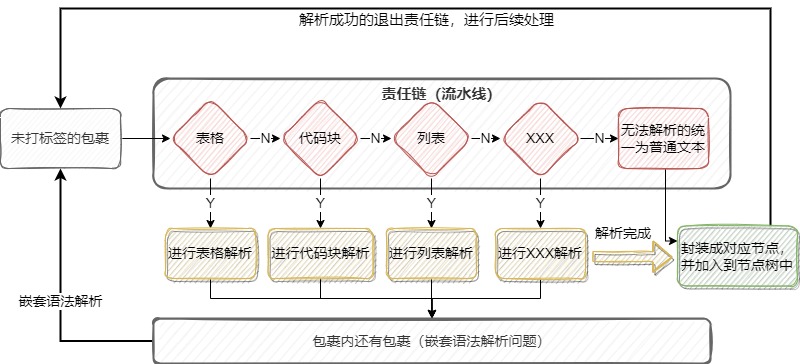
块解析的代码
public void parser(String text, Node node) {
List<String> blocks = this.splitBlock(text);
// 逐块处理文本
for (String block : blocks) {
blockParserChain.parser(block, node);
}
}
2.4. 策略模式
动态选择解析器完成行级元素的解析。
块级元素解析完成后,会形成块节点的节点树,再进行行级元素解析。
public Node parse(String markdownText) {
Node root = new DocumentNode();
// 统一换行符,替换所有 \r\n 或 \r 为 \n
String normalizedText = markdownText.replaceAll("\r\n|\r", "\n");
// 块级元素解析
blockParserContext.parser(normalizedText, root);
// 行级元素解析
this.parseInlines(root);
return root;
}
行级元素并不是所有块元素都需要进行处理,目前只对标题和段落块节点进行解析,因为其它块级元素的内容最终会通过段落节点进行保存。
根据语法特点,动态选择解析器完成行级元素的解析,关键代码如下:
// 检查字符对或单个字符,选择对应的解析器
String possibleDelimiter = this.getPossibleDelimiter(line, i);
InlineParser inlineParser = inlineParserMap.get(possibleDelimiter);
if (inlineParser != null) {
// 找到合适地解析器,尝试解析
InlineNode inlineNode = inlineParser.parser(sourceLine, this);
if(inlineNode!=null){
node.addChildNode(inlineNode);
}
}
2.5. 组合模式和迭代器模式
表示 Markdown 语法结构(如段落、标题、列表)之间的树形结构,每个语法对应一个Node节点,在块级元素和行级元素的解析过程,最终组合成节点树。节点和迭代器源码位于org.ytymark.node包。
通过迭代器结合递归来遍历节点树,在解析阶段,用于遍历块级元素进行行内元素解析。
使用迭代器完成兄弟节点的遍历(广度遍历),再结合递归完成子节点遍历(深度遍历),具体源码如下:
/**
* 行级元素解析
* @param parent 父节点
*/
@Override
public void parseInlines(Node parent) {
Iterator<Node> iterator = parent.createIterator();
while (iterator.hasNext()) {
// 获取下一个兄弟节点
Node node = iterator.next();
// 解析子节点行
if(node instanceof ParagraphNode){
inlineParserContext.parser(((ParagraphNode) node).getText(),node);
}
if(node instanceof HeadingNode) {
inlineParserContext.parser(((HeadingNode) node).getText(), node);
}
if(node.getFirstChild()!=null)
parseInlines(node);
}
}
3. 渲染器
目标:将 AST 语法树渲染为 HTML 文本预览。
使用到的设计模式:
中介者模式思想:加入AST节点树解耦解析器和渲染器,使其灵活地渲染成不同的文档。
迭代器模式:通过迭代器结合递归来遍历节点树,比如遍历节点树完成渲染操作。
访问者模式:负责分离节点数据与渲染操作,提高渲染的扩展性。
3.1. 中介者模式思想
在解析和渲染中间加入AST节点树,解耦解析器和渲染器,使得一次解析可以灵活地渲染成不同的文档。为了将低耦合,常常会在两者间多加一层。
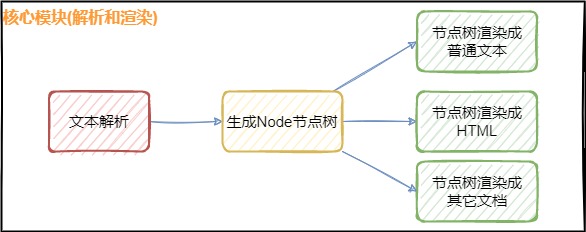
3.2. 迭代器模式
通过迭代器结合递归来遍历节点树,在渲染阶段,遍历节点树完成渲染操作。
/**
* 循环渲染兄弟节点
* 在实现这个抽象类的渲染器中,如果存在子节点行为就需要调用这个方法实现递归遍历子节点
*/
protected void renderChildren(Node parent) {
Iterator<Node> iterator = parent.createIterator();
while (iterator.hasNext()) {
// 获取下一个兄弟节点
Node next = iterator.next();
// 渲染节点
next.render(this);
}
}
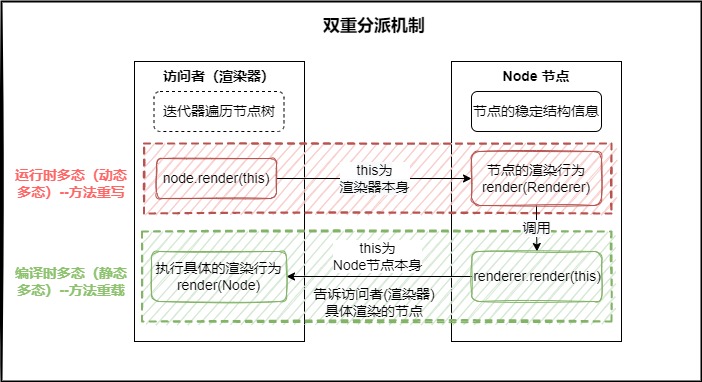
3.3. 访问者模式
负责分离Node节点数据与渲染操作行为,提高渲染的扩展性。在每个节点类中,实现渲染逻辑时只需要编写以下代码:
@Override
public void render(Renderer renderer) {
renderer.render(this);
}
将渲染逻辑抽离出来,由渲染器接口实现类来实现具体的渲染逻辑,不同的实现类对应不同的渲染行为,目前只实现了HTML的渲染。
在构建器中选择渲染器类型:
Renderer renderer = RendererBuilder.builder().build(HtmlRenderer.class);
解决渲染的扩展性(多样性)问题
如果需要将markdown文本渲染成普通文本,则只需要继承AbstractRenderer 抽象类,实现Renderer接口中所有方法即可。并且实现渲染逻辑非常简单,只需要关注当前节点要做的事情即可。
比如,表格最外层的渲染源码
@Override
public void render(TableNode tableNode) {
sbHTML.append("<table>\n");
renderChildren(tableNode);
sbHTML.append("</table>\n");
}
而兄弟节点(广度遍历)和嵌套子节点(深度遍历),只需要调用抽象类AbstractRenderer的 renderChildren(Node parent)方法即可完成渲染,使得渲染逻辑只需要关注当前节点的行为即可。比如上面的表格渲染代码renderChildren(tableNode);。
4. 项目亮点
高度模块化,任何 Markdown 语法都能独立添加/修改。
设计模式实战,适合做设计模式学习的项目。
️ 可按需获取,用户界面和文本解析渲染分为两个模块
只使用用户界面源码,然后轻松切换成熟的解析器依赖,开发一个完整的markdown文本编辑器;
仅学习文本解析渲染模块源码,不用关注用户界面源码。
解析性能毫秒级,确保解析效率。
轻松上手,使用JDK8 自带JavaFX模块,无需做额外处理。
开源项目,文档完善,方便学习和贡献。
️5. 总结
markdown 文本解析和渲染将多种设计模式融入到实际应用中,是一次系统性的 设计模式实践或架构设计实践。
更多详细内容可以前往笔者微信公众号回复:设计模式,来获取,后续有关设计模式的新资料都可以从这个入口获取到。
秘籍1设计模式手册:《掌握设计模式:23种经典模式实践、选择、价值与思想》
秘籍2练手项目:设计模式实战项目--markdown文本编辑器软件开发(已开源)
查看往期设计模式文章的:设计模式
三连支持!!!
markdown文本编辑器--核心功能(解析和渲染)的更多相关文章
- Unity5 新功能解析--物理渲染与standard shader
Unity5 新功能解析--物理渲染与standard shader http://blog.csdn.net/leonwei/article/details/48395061 物理渲染是UNITY5 ...
- PyQt(Python+Qt)学习随笔:纯文本编辑器QPlainTextEdit功能详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.概述 QPlainTextEdit是用于纯文本的一个高级文档编辑器 ...
- PyQt(Python+Qt)学习随笔:富文本编辑器QTextEdit功能详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.概述 QTextEdit是一个高级的所见即所得的文档查看器和编辑器 ...
- Cinder 架构分析、高可用部署与核心功能解析
目录 文章目录 目录 Cinder Cinder 的软件架构 cinder-api cinder-scheduler cinder-volume Driver 框架 Plugin 框架 cinder- ...
- drupal中安装CKEditor文本编辑器,并配置图片上传功能
一.下载: 1.CKEditor模块 2.IMCE模块 二.安装 1.复制: 下载完上面两个模块之后,解压,将解压后整个文件夹,复制粘贴,放到 sites\all\modules下面,个人 ...
- 现代富文本编辑器Quill的模块化机制
DevUI是一支兼具设计视角和工程视角的团队,服务于华为云DevCloud平台和华为内部数个中后台系统,服务于设计师和前端工程师.官方网站:devui.designNg组件库:ng-devui(欢迎S ...
- react 富文本编辑器
5大富文本编辑器今天,富文本编辑器被用于许多应用中,包括简单的博客和复杂的内容管理系统.然而,选择一个并不容易,因为有很多具有不同功能的编辑器. 因此,在这篇文章中,我将评估5个React的富文本编辑 ...
- javascript 简易文本编辑器
转载请注明出处:http://www.cnblogs.com/enzozo/p/4357031.html 写在前面: 本文本编辑器具备功能:选择字体大小.颜色.加粗.斜体.下划线.点击 'Submit ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(六)easyUI与富文本编辑器UEditor整合
日常啰嗦 本来这一篇和接下来的几篇是打算讲一下JDBC和数据库优化的,但是最近很多朋友加我好友也讨论了一些问题,我发现大家似乎都是拿这个项目作为练手项目,作为脚手架来用的,因此呢,改变了一下思路,JD ...
- ASP.NET MVC5 中百度ueditor富文本编辑器的使用
随着网站信息发布内容越来越多,越来越重视美观,富文本编辑就是不可缺少的了,众多编辑器比较后我选了百度的ueditor富文本编辑器. 百度ueditor富文本编辑器分为两种一种是完全版的ueditor, ...
随机推荐
- 另辟新径实现 Blazor/MAUI 本机交互(二)
Maui 基础 Preferences 是 .NET MAUI 提供的一个静态类,用于存储和检索应用程序的首选项(即设置或配置).它提供了一种简单的键值对存储机制,可以跨平台使用.每个平台使用其本地的 ...
- ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this
mysql操作错误: mysql> use mysql;ERROR 1820 (HY000): You must reset your password using ALTER USER sta ...
- C# Lambda || Linq 效率问题
255条数据 static void Main() { List<IPEndPoint> list = new List<IPEndPoint>(); for (int i = ...
- docker - [11] 数据卷之DockerFile
通过DockerFile可以生成一个镜像 一.DockerFile的介绍 狂神:dockerfile是用来构建docker镜像的文件命令参数脚本. 狂神:dockerfile是面向开发的,我们以后要发 ...
- Processing 使用pixels[]像素数组绘制矩形rect和圆形ellipse
余温 两次绘制了棋盘格,有了一些经验了,顺着学习态势,我们再接再厉,挖一些技巧.这一次要使用pixels[]数组绘制矩形rect和圆形ellipse,也就是代替rect()和ellipse()两个函数 ...
- excel 数字转中文大写金额
1.在单元格中输入公式: =SUBSTITUTE(SUBSTITUTE(IF(-RMB(A1,2),TEXT(A1,";负")&TEXT(INT(ABS(A1)+0.5%) ...
- 不止排名,Google SEO 10 大核心心得分享
原博客:https://bysocket.com/seo-tips-2025/ 在过去的一年中,我深入实践了 Google SEO,积累了自己一些经验和看法.以下是我的实操心得,希望对大家有所帮助. ...
- 【 Python 】补全fibersim 导出的xml语法
fibersim导出的xml文件中,node 和mesh部分的标签会缺失.即<R></R>变成了<R/>. 以下python脚本可以自动修正 # ********* ...
- Golang 入门 : 符文
字符串常用语表示一系列文本字符,而Go的符文(rune)则用于表示单个字符. 字符串字面量由双引号(")包围,但rune字面量由单引号(')包围. Go程序几乎可以使用地球上任何语言的任何字 ...
- PHP文件上传封装
class FileUploader { private $targetDirectory; private $allowedExtensions; private $maxFileSize; pub ...