一文彻底弄清Redis的布隆过滤器
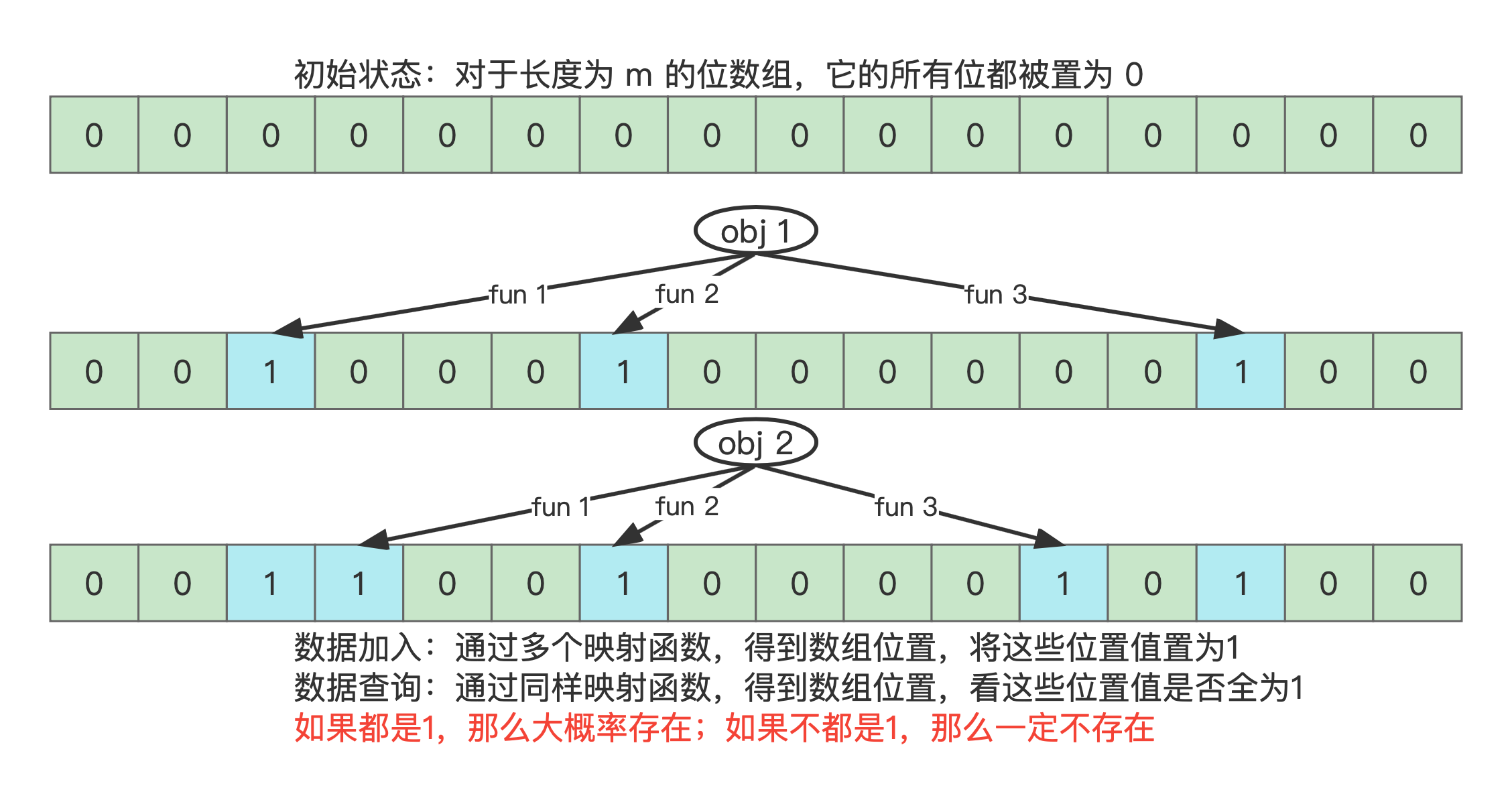
布隆过滤器(Bloom Filter)是一种空间效率极高的数据结构,用于快速判断一个元素是否在集合中。它能够节省大量内存,但它有一个特点:可能存在误判,即可能会认为某个元素存在于集合中,但实际上不存在;而对于不存在的元素,它保证一定不会误判。布隆过滤器适合在对存储空间要求极为严格,同时能接受少量误判的应用场景中使用。
1. 布隆过滤器的工作原理
布隆过滤器的核心思想是使用多个哈希函数(Hash Functions)和一个位数组(Bit Array)。其操作过程如下:
1.1 插入元素
- 当插入一个元素时,布隆过滤器会使用多个不同的哈希函数对该元素进行哈希计算,得到多个哈希值(位置索引),并将这些哈希值对应的位数组位置设置为
1。 - 例如,一个元素经过 3 个哈希函数后,得到了 3 个不同的位置,布隆过滤器就在这 3 个位置上将位数组的值设为
1。
1.2 查询元素
- 查询某个元素时,布隆过滤器会使用相同的哈希函数对该元素进行哈希计算,得到多个位置。如果所有这些位置的位都为
1,则布隆过滤器认为这个元素可能存在;如果任意一个位置的位为0,则可以确定这个元素一定不存在。
1.3 特点
- 可能存在误判:布隆过滤器有可能出现误判,查询一个不存在的元素时,有小概率会因为位数组中的某些位被其他元素设为
1,而误认为这个元素存在。 - 不会漏判:如果某个元素不存在,布隆过滤器一定不会误判其存在,即布隆过滤器查询某个元素是否存在时,若判断不存在,结果是可靠的。
2. 布隆过滤器的组成部分
2.1 位数组(Bit Array)
位数组是布隆过滤器的核心数据结构。它是一个长度为 m 的数组,每个位置上只能存储 0 或 1。初始时,位数组中所有位置的值都为 0。在插入元素时,哈希函数根据元素值生成若干个位置索引,并将这些索引对应的位设为 1。
2.2 哈希函数(Hash Functions)
布隆过滤器使用多个哈希函数(通常是独立的哈希函数)来对元素进行哈希操作。每个哈希函数会生成一个不同的位数组索引,用于确定元素的存储位置。
- 选择的哈希函数应当具有较好的均匀性,确保哈希值能够均匀分布在位数组上,减少冲突。
2.3 哈希函数的数量(k 值)
k 表示用于每个元素的哈希函数的个数。哈希函数数量越多,误判的概率越低,但查询和插入的复杂度会增加。因此,k 的数量一般选择一个合适的中间值,以在查询性能和误判率之间取得平衡。
2.4 位数组的长度(m 值)
m 是位数组的长度,位数组越长,误判率越低,但需要占用的内存也更多。因此,位数组的长度应该根据实际的业务需求和内存开销进行权衡设计。
3. 布隆过滤器的误判率
布隆过滤器的误判率是指在查询时,布隆过滤器错误地认为一个不存在的元素存在于集合中的概率。误判率随着集合中插入的元素数量的增加而增加,主要受到以下几个因素的影响:
- 位数组长度(m):位数组越长,误判率越低。
- 哈希函数数量(k):哈希函数数量适中时误判率最低,但数量过多会使得误判率增加。
- 元素数量(n):插入的元素越多,误判率越高,因为位数组中被设置为
1的位越来越多,哈希函数的碰撞机会增大。
布隆过滤器的误判率计算公式如下: p=(1−e−k⋅nm)kp = \left( 1 - e^{- \frac{k \cdot n}{m}} \right)^kp=(1−e−mk⋅n)k
p是误判率;k是哈希函数的数量;n是插入的元素数量;m是位数组的长度。
4. 布隆过滤器的优缺点
4.1 优点
- 高效的空间利用率:布隆过滤器可以用较小的空间存储大量数据,尤其在元素数量很大时,它可以显著节省内存。
- 查询和插入操作的时间复杂度很低:无论插入还是查询,布隆过滤器的时间复杂度都是 O(k),即与哈希函数的数量成线性关系,速度非常快。
- 适合大规模数据过滤:对于海量数据的存在性判断,布隆过滤器非常高效,适合在需要快速判断某个元素是否存在的场景中使用。
4.2 缺点
- 存在误判:布隆过滤器可能会误判一个元素存在,即判断结果可能为“假阳性”(False Positive),这意味着虽然布隆过滤器认为某个元素存在,但实际上它并不存在。布隆过滤器不适合用于需要精准判断的场景。
- 无法删除元素:布隆过滤器无法直接删除元素,因为哈希函数将多个元素映射到同一位数组位置,删除某个元素可能会导致其他元素的哈希结果失效。虽然有计数布隆过滤器(Counting Bloom Filter)可以支持删除操作,但其实现更加复杂。
5. 布隆过滤器的典型应用场景
5.1 缓存穿透防护
布隆过滤器最常见的应用之一就是防止
缓存穿透
。在 Redis 缓存场景中,用户请求的数据可能在缓存和数据库中都不存在,如果不加以防护,这些请求会直接打到数据库。通过布隆过滤器,可以在请求前判断元素是否可能存在于数据库中,从而减少无效的数据库查询。
- 场景: 一个电商系统中,用户可能会频繁查询一些并不存在的商品 ID。布隆过滤器可以用来存储所有合法商品 ID,在查询前进行判断,如果布隆过滤器中不存在,则可以直接返回空结果,而不必查询数据库和缓存。
5.2 垃圾邮件过滤
- 布隆过滤器可以用于垃圾邮件系统,用来快速判断某个电子邮件地址或 IP 是否在黑名单列表中。由于布隆过滤器的高效性,可以极大提高垃圾邮件检测的速度,并节省内存资源。
5.3 大数据去重
- 在大规模数据处理场景中,布隆过滤器可以用来检测某个元素是否已经出现过,从而实现去重操作。它特别适用于对内存要求严格的系统中,比如分布式爬虫系统中需要去重的 URL 处理。
5.4 数据库和存储系统
- 布隆过滤器被广泛应用于数据库和存储系统中,用于减少不必要的磁盘 I/O 操作。例如:
- HBase 使用布隆过滤器来加快查找速度,避免不必要的磁盘读取。
- Cassandra 使用布隆过滤器来判断某个 SSTable 是否包含某个键,从而减少磁盘扫描次数。
6. 布隆过滤器的扩展
6.1 计数布隆过滤器(Counting Bloom Filter)
计数布隆过滤器是一种支持删除操作的布隆过滤器。与标准布隆过滤器不同的是,计数布隆过滤器的位数组中的每个位置不再是二进制的 0 和 1,而是一个计数器。当插入一个元素时,多个哈希函数对应的位上的计数器增加;当删除一个元素时,计数器相应减少。
计数布隆过滤器的缺点是需要更多的存储空间(因为每个位置是一个计数器),但它允许删除元素,这使得它适用于动态更新的场景。
6.2 分布式布隆过滤器
在大规模分布式系统中,布隆过滤器可以扩展为分布式布隆过滤器,即将位数组分布在多个节点上,并且每个节点负责一部分位数组的存储和哈希计算。这样可以提高系统的可扩展性,适应更大规模的数据集。
总结
布隆过滤器是一种空间效率极高的数据结构,适用于需要快速判断某个元素是否存在的场景,尤其适用于防止缓存穿透、垃圾邮件过滤、大数据去重等场景。虽然它存在一定的误判率,但其出色的空间效率和查询性能使其成为许多大规模应用中的重要工具。
一文彻底弄清Redis的布隆过滤器的更多相关文章
- Redis实现布隆过滤器解析
布隆过滤器原理介绍 [1]概念说明 1)布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合 ...
- 09 redis中布隆过滤器的使用
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容.问题来了,新闻客户端推荐系统如何实现推送去重的? 会想到服务器记录了用户看过的所有历史记录,当推 ...
- redis之布隆过滤器
布隆过滤器是什么? 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判.但是布隆过滤器也不是特别不精确,只要参数设置的合理,它 ...
- 浅谈redis的HyperLogLog与布隆过滤器
首先,HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法. HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元 ...
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- Redis05——Redis高级运用(管道连接,发布订阅,布隆过滤器)
Redis高级运用 一.管道连接redis(一次发送多个命令,节省往返时间) 1.安装nc yum install nc -y 2.通过nc连接redis nc localhost 6379 3.通过 ...
- Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
Redis: 缓存过期.缓存雪崩.缓存穿透.缓存击穿(热点).缓存并发(热点).多级缓存.布隆过滤器 2019年08月18日 16:34:24 hanchao5272 阅读数 1026更多 分类专栏: ...
- Redis 布隆过滤器
1.布隆过滤器 内容参考:https://www.jianshu.com/p/2104d11ee0a2 1.数据结构 布隆过滤器是一个BIT数组,本质上是一个数据,所以可以根据下标快速找数据 2.哈希 ...
- 详细解析Redis中的布隆过滤器及其应用
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货. 什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告 ...
- Redis详解(十三)------ Redis布隆过滤器
本篇博客我们主要介绍如何用Redis实现布隆过滤器,但是在介绍布隆过滤器之前,我们首先介绍一下,为啥要使用布隆过滤器. 1.布隆过滤器使用场景 比如有如下几个需求: ①.原本有10亿个号码,现在又来了 ...
随机推荐
- 连接huggingface.co报错:(MaxRetryError("SOCKSHTTPSConnectionPool(host='huggingface.co', port=443) (SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)
参考: https://blog.csdn.net/shizheng_Li/article/details/132942548 https://blog.csdn.net/weixin_4220944 ...
- 一款比较好用的 ssh、 ftp 服务的客户端软件 —— NxShell
该软件地址: https://gitee.com/nxshell/nxshell 截图: ======================================================= ...
- baselines算法库common/tile_images.py模块分析
该模块只有一个函数,全部内容: import numpy as np def tile_images(img_nhwc): """ Tile N images into ...
- 白鲸开源 DataOps 平台加速数据分析和大模型构建
作者 | 李晨 编辑 | Debra Chen 数据准备对于推动有效的自助式分析和数据科学实践至关重要.如今,企业大都知道基于数据的决策是成功数字化转型的关键,但要做出有效的决策,只有可信的数据才能提 ...
- vue 文件流下载
/** * 文件转为文件流 * @param {file} file //文件 */ export function getFileBlob(file) { var dataUrl va ...
- 修复 Longhorn 卷挂载失败(”CentOS 7.6-'fsck' found errors on device“)
查看 Pod 日志 kubectl describe po clickhouse-0 -n clickhouse ...... #Events: # Type Reason Age From Mess ...
- C#数据结构与算法实战入门指南
前言 在编程领域,数据结构与算法是构建高效.可靠和可扩展软件系统的基石.它们对于提升程序性能.优化资源利用以及解决复杂问题具有至关重要的作用.今天大姚分享一些非常不错的C#数据结构与算法实战教程,希望 ...
- SMU Summer 2024 Contest Round 8
SMU Summer 2024 Contest Round 8 Product 思路 注意到 \(\prod\limits_{i=1}^NL_i\le10^5\),也就是说 N 不会超过 16,因为 ...
- 设计模式之cglib动态代理
什么是动态代理呢?动态代理就是在java进程运行时,通过字节码技术,动态的生成某个类的代理类.在这个代理类中,我们可以做一些额外的操作,一方面仍然保持原有的方法的能力,另外一方面还增强了这些能力.听着 ...
- Win32 GDI 在内存中绘制彩色的位图
Wind32 GDI在内存中绘制彩色位图 1创建兼容的内存DC hPicture为创建的静态文本框控件句柄 LRESULT OnPaint(HWND hWnd) { PAINTSTRUCT ps; H ...