使用Xpath+多进程爬取诗词名句网的史书典籍类所有文章。update~
上次写了爬取这个网站的程序,有一些地方不完善,而且爬取速度较慢,今天完善一下并开启多进程爬取,速度就像坐火箭。。
# 需要的库
from lxml import etree
import requests
from multiprocessing import Pool
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 保存文本的地址
pathname=r'E:\爬虫\诗词名句网\\'
# 获取书籍名称的函数
def get_book(url):
try:
response = requests.get(url,headers)
etrees = etree.HTML(response.text)
url_infos = etrees.xpath('//div[@class="bookmark-list"]/ul/li')
urls = []
for i in url_infos:
url_info = i.xpath('./h2/a/@href')
book_name = i.xpath('./h2/a/text()')[0]
print('开始下载.'+book_name)
urls.append('http://www.shicimingju.com' + url_info[0])
# print('http://www.shicimingju.com'+url_info[0])
# get_index('http://www.shicimingju.com'+url_info[0])
# 开启多进程
pool.map(get_index,urls)
except Exception:
print('get_book failed')
# 获取书籍目录的函数
def get_index(url):
try:
response = requests.get(url, headers)
etrees = etree.HTML(response.text)
url_infos = etrees.xpath('//div[@class="book-mulu"]/ul/li')
for i in url_infos:
url_info = i.xpath('./a/@href')
# print('http://www.shicimingju.com' + url_info[0])
get_content('http://www.shicimingju.com' + url_info[0])
except Exception as e:
print(e)
# 获取书籍内容并写入.txt文件
def get_content(url):
try:
response = requests.get(url, headers)
etrees = etree.HTML(response.text)
title = etrees.xpath('//div[@class="www-main-container www-shadow-card "]/h1/text()')[0]
content = etrees.xpath('//div[@class="chapter_content"]/p/text()')
if not content:
content = etrees.xpath('//div[@class="chapter_content"]/text()')
content = ''.join(content)
book_name = etrees.xpath('//div[@class="nav-top"]/a[3]/text()')[0]
with open(pathname + book_name + '.txt', 'a+', encoding='utf-8') as f:
f.write(title + '\n\n' + content + '\n\n\n')
print(title + '..下载完成')
else:
content = ''.join(content)
book_name=etrees.xpath('//div[@class="nav-top"]/a[3]/text()')[0]
with open(pathname+book_name+'.txt','a+',encoding='utf-8') as f:
f.write(title+'\n\n'+content+'\n\n\n')
print(title+'..下载完成')
except Exception:
print('get_content failed')
# 程序入口
if __name__ == '__main__':
url = 'http://www.shicimingju.com/book/'
# 开启进程池
pool = Pool()
# 启动函数
get_book(url)
控制台输出;
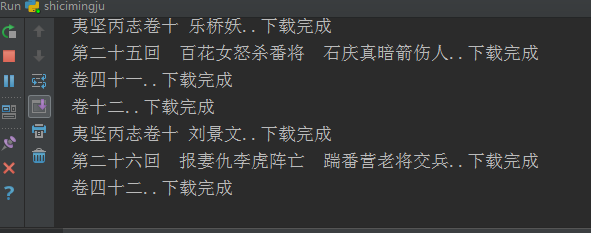
查看文件夹,可以发现文件是多个多个的同时在下载;
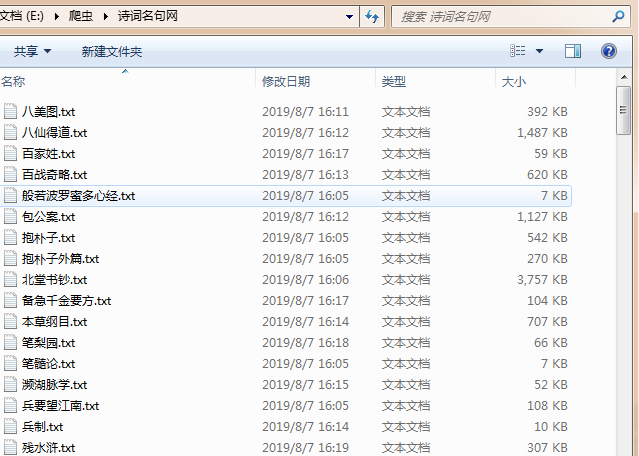
done。
使用Xpath+多进程爬取诗词名句网的史书典籍类所有文章。update~的更多相关文章
- 使用Xpath爬虫库下载诗词名句网的史书典籍类所有文章。
# 需要的库 from lxml import etree import requests # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows ...
- xpath+多进程爬取网易云音乐热歌榜。
用到的工具,外链转换工具 网易云网站直接打开源代码里面并没有对应的歌曲信息,需要对url做处理, 查看网站源代码路径:发现把里面的#号去掉会显示所有内容, 右键打开的源代码路径:view-source ...
- xpath+多进程爬取全书网纯爱耽美类别的所有小说。
# 需要的库 import requests from lxml import etree from multiprocessing import Pool import os # 请求头 heade ...
- xpath+多进程爬取八零电子书百合之恋分类下所有小说。
代码 # 需要的库 import requests from lxml import etree from multiprocessing import Pool import os # 请求头 he ...
- 爬取斗图网图片,使用xpath格式来匹配内容,对请求伪装成浏览器, Referer 防跨域请求
6.21自我总结 一.爬取斗图网 1.摘要 使用xpath匹配规则查找对应信息文件 将请求伪装成浏览器 Referer 防跨域请求 2.爬取代码 #导入模块 import requests #爬取网址 ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
随机推荐
- Redis常用运维命令
1.启动命令 按照我其他博客的按照方法,启动命令为/etc/init.d/redis_6379 start 2.查看内存统计信息 [root@bogon ~]# redis-cli > info ...
- POJ-图论-并查集模板
POJ-图论-并查集模板 1.init:把每一个元素初始化为一个集合,初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变). void init() { for ...
- ThreadLocal源代码3
public class ThreadLocal1<T> { //当创建了一个 ThreadLocal 的实例后,它的散列值就已经确定了, //threadLocal实例的hashCode ...
- Mac多SSH Key配置
多SSH key配置 工作的时候碰到SSH配置的问题,就是公司用的是gittea的仓库,而本人的github平常也要使用,这个时候就需要配置不同的SSH key了.将同一个公钥分配配置给github和 ...
- c++中共享内存原理及实现
共享内存 (也叫内存映射文件) 主要是通过映射机制实现的 , Windows 下进程的地址空间在逻辑上是相互隔离的 , 但在物理上却是重叠的 ; 所谓的重叠是指同一块内存区域可能被多个进程同时使用 , ...
- Python-07-高阶函数
一.定义 默认满足以下两个条件中的一个就是高阶函数: 函数的传入参数是一个函数名 函数的返回值是一个函数名 二.map函数 map接收两个参数,一个函数和一个Iterable,map将接收到的函数作用 ...
- Vue框架(四)——路由跳转、路由传参、cookies、axios、跨域问题、element-ui模块
路由跳转 三种方式: $router.push / $router.go / router-link to this.$router.push('/course'); this.$router.pus ...
- C基础 stack 设计
前言 - stack 设计思路 先说说设计 stack 结构的原由. 以前我们再释放查找树的时候多数用递归的后续遍历去释放. 其内部隐含了运行时的函数栈, 有些语言中存在爆栈风险. 所以想运用显示栈来 ...
- 【Linux】Ubuntu替换阿里源
--------------------------------------------------------- 参考文章:https://www.jianshu.com/p/97c35d569aa ...
- golang 之 context包
概述 context是Go中广泛使用的程序包,由Google官方开发,在1.7版本引入.它用来简化在多个go routine传递上下文数据.(手动/超时)中止routine树等操作,比如,官方 ...