现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。 buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t”分割
实验内容(mapReduce安装请按照林子雨教程http://dblab.xmu.edu.cn/blog/631-2/)
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以空格分割,样本数据及格式如下:
10181 1000481 2010-04-04 16:54:31
20001 1001597 2010-04-07 15:07:52
20001 1001560 2010-04-07 15:08:27
20042 1001368 2010-04-08 08:20:30
20067 1002061 2010-04-08 16:45:33
20056 1003289 2010-04-12 10:50:55
20056 1003290 2010-04-12 11:57:35
20056 1003292 2010-04-12 12:05:29
20054 1002420 2010-04-14 15:24:12
20055 1001679 2010-04-14 19:46:04
20054 1010675 2010-04-14 15:23:53
20054 1002429 2010-04-14 17:52:45
20076 1002427 2010-04-14 19:35:39
20054 1003326 2010-04-20 12:54:44
20056 1002420 2010-04-15 11:24:49
20064 1002422 2010-04-15 11:35:54
20056 1003066 2010-04-15 11:43:01
20056 1003055 2010-04-15 11:43:06
20056 1010183 2010-04-15 11:45:24
20056 1002422 2010-04-15 11:45:49
20056 1003100 2010-04-15 11:45:54
20056 1003094 2010-04-15 11:45:57
20056 1003064 2010-04-15 11:46:04
20056 1010178 2010-04-15 16:15:20
20076 1003101 2010-04-15 16:37:27
20076 1003103 2010-04-15 16:37:05
20076 1003100 2010-04-15 16:37:18
20076 1003066 2010-04-15 16:37:31
20054 1003103 2010-04-15 16:40:14
20054 1003100 2010-04-15 16:40:16
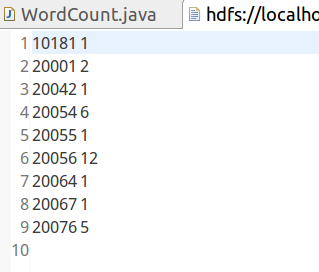
要求编写MapReduce程序,统计每个买家收藏商品数量。
实验原理
MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
1.MapReduce的工作原理
在分布式计算中,MapReduce框架负责处理了并行编程里分布式存储、工作调度,负载均衡、容错处理以及网络通信等复杂问题,现在我们把处理过程高度抽象为Map与Reduce两个部分来进行阐述,其中Map部分负责把任务分解成多个子任务,Reduce部分负责把分解后多个子任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中输入的value值存储的是文本文件中的一行(以回车符为行结束标记),而输入的key值存储的是该行的首字母相对于文本文件的首地址的偏移量。然后用StringTokenizer类将每一行拆分成为一个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map方法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输入到reduce方法中,reduce方法只要遍历values并求和,即可得到某个单词的总次数。
在main()主函数中新建一个Job对象,由Job对象负责管理和运行MapReduce的一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。本实验是设置使用将继承Mapper的doMapper类完成Map过程中的处理和使用doReducer类完成Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由字符串指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务,其余的工作都交由MapReduce框架处理。
2.MapReduce框架的作业运行流程
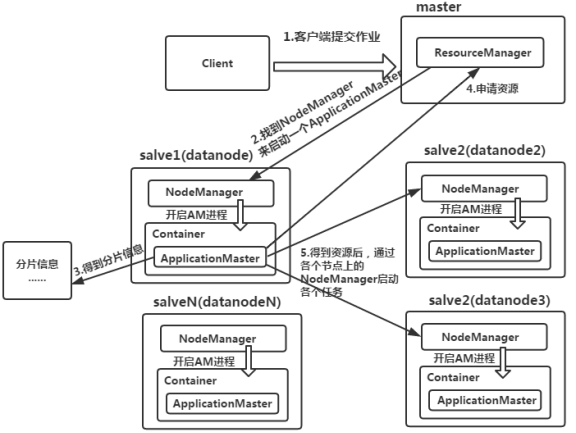
(1)ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
(2)NodeManager:简称NM,NodeManager是ResourceManager在每台机器上的代理,负责容器管理,并监控他们的资源使用情况(cpu、内存、磁盘及网络等),以及向ResourceManager提供这些资源使用报告。
(3)ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动Container,并告诉Container做什么事情。
(4)Container:资源容器。YARN中所有的应用都是在Container之上运行的。AM也是在Container上运行的,不过AM的Container是RM申请的。Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster。Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
①运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源。
②运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并为了ApplicationMaster与NodeManager通信以启动的。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
新建map Reduce项目:(自动导入包)
将buyer_favorite1.txt放入hdfs中
package mapReduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/buyer_favorite1");
Path out = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
boolean flag = job.waitForCompletion(true);
System.out.println(flag);
System.exit(flag? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, IntWritable> {
//第一个Object表示输入key的类型;第二个Text表示输入value的类型;第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {//抛出异常
StringTokenizer tokenizer = new StringTokenizer(value.toString(), " ");//以空格分割
//StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分
word.set(tokenizer.nextToken());
//返回当前位置到下一个分隔符之间的字符串
context.write(word, one);
//将word存到容器中,记一个数
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
运行结果:
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。 buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t”分割的更多相关文章
- 如何一步一步用DDD设计一个电商网站(四)—— 把商品卖给用户
阅读目录 前言 怎么卖 领域服务的使用 回到现实 结语 一.前言 上篇中我们讲述了“把商品卖给用户”中的商品和用户的初步设计.现在把剩余的“卖”这个动作给做了.这里提醒一下,正常情况下,我们的每一步业 ...
- 如何一步一步用DDD设计一个电商网站(三)—— 初涉核心域
一.前言 结合我们本次系列的第一篇博文中提到的上下文映射图(传送门:如何一步一步用DDD设计一个电商网站(一)—— 先理解核心概念),得知我们这个电商网站的核心域就是销售子域.因为电子商务是以信息网络 ...
- [.NET] 一步步打造一个简单的 MVC 电商网站 - BooksStore(三)
一步步打造一个简单的 MVC 电商网站 - BooksStore(三) 本系列的 GitHub地址:https://github.com/liqingwen2015/Wen.BooksStore &l ...
- 小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 利用 jQuery 操作页面元素的方法,实现电商网站购物车页面商品数量的增加和减少操作,要求单项价格和总价随着数量的改变而改变
查看本章节 查看作业目录 需求说明: 利用 jQuery 操作页面元素的方法,实现电商网站购物车页面商品数量的增加和减少操作,要求单项价格和总价随着数量的改变而改变 当用户单击"+" ...
- 小白学 Python 爬虫:Selenium 获取某大型电商网站商品信息
目标 先介绍下我们本篇文章的目标,如图: 本篇文章计划获取商品的一些基本信息,如名称.商店.价格.是否自营.图片路径等等. 准备 首先要确认自己本地已经安装好了 Selenium 包括 Chrome ...
- 如何一步一步用DDD设计一个电商网站(十一)—— 最后的准备
阅读目录 前言 准备 实现 结语 一.前言 最近实在太忙,上周停更了一周.按流程一步一步走到现在,到达了整个下单流程的最后一公里——结算页的处理.从整个流程来看,这里需要用户填写的信息是最多的,那么 ...
- DDD设计一个电商网站
DDD设计一个电商网站(十一)-- 最后的准备 阅读目录 前言 准备 实现 结语 一.前言 最近实在太忙,上周停更了一周.按流程一步一步走到现在,到达了整个下单流程的最后一公里--结算页的处理. ...
- 如何一步一步用DDD设计一个电商网站(九)—— 小心陷入值对象持久化的坑
阅读目录 前言 场景1的思考 场景2的思考 避坑方式 实践 结语 一.前言 在上一篇中(如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成),有一行注释的代码: public interfa ...
随机推荐
- SpringBoot的入门程序
1. 创建一个springboot工程 可以参考springboot入门程序 2. 创建一个实体类 @Data //想相当于@Setter.@Getter和@ToString替代了setter.get ...
- 【开发工具】- Idea.2018.02注册码激活
1.从下面地址下载一个jar包,名称是 JetbrainsCrack-3.1-release-enc.jar 下载地址: 链接: https://pan.baidu.com/s/1VZjklI3qh ...
- 【Jmeter】他人总结篇链接(共八篇相关文章)
[Jmeter]他人总结篇链接(共八篇相关文章) https://blog.csdn.net/mu_wind/article/category/9029006
- python基础-函数递归
函数递归 概念:直接或间接地重复调用函数本身,是一种函数嵌套调用的表现形式. 直接调用:在函数内部,直接调用函数本身 def foo(): print("这是foo函数") foo ...
- centos7 docker安装Jenkins BlueOcean
Jenkins是一款Java开发的跨平台持续集成和持续发布的开源项目,Jenkins已经作为各大公司进行CI/CD的首选工具.而BlueOcean是Jenkins推出的一个插件,其目的就是让程序员执行 ...
- cadvisor应用
cadvisor主页:https://github.com/google/cadvisor 容器主页:https://hub.docker.com/r/google/cadvisor cAdvisor ...
- SpringCloud2.0 Ribbon 服务发现 基础教程(四)
1.启动[服务中心]集群,即 Eureka Server 参考 SpringCloud2.0 Eureka Server 服务中心 基础教程(二) 2.启动[服务提供者]集群,即 Eureka Cli ...
- 17、Learning and Transferring IDs Representation in E-commerce笔记
一.摘要 电子商务场景:主要组成部分(用户ID.商品ID.产品ID.商店ID.品牌ID.类别ID等) 传统的编码两个缺陷:如onehot,(1)存在稀疏性问题,维度高(2)不能反映关系,以两个不同的i ...
- P1197 [JSOI2008]星球大战[并查集+图论]
题目来源:洛谷 题目描述 很久以前,在一个遥远的星系,一个黑暗的帝国靠着它的超级武器统治着整个星系. 某一天,凭着一个偶然的机遇,一支反抗军摧毁了帝国的超级武器,并攻下了星系中几乎所有的星球.这些星球 ...
- springboot,eclipse打包出错处理
打jar包报错 [WARNING] The POM for org.apache.maven.plugins:maven-clean-plugin:jar:3.1.0 is invalid, tran ...