管道模型(Pipeline)
1.使用make_blobs来生成数据集,然后对数据集进行预处理
#导入数据集生成器
from sklearn.datasets import make_blobs
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#导入预处理工具
from sklearn.preprocessing import StandardScaler
#导入多层感知器神经网络
from sklearn.neural_network import MLPClassifier
#导入画图工具
import matplotlib.pyplot as plt
#生成样本数量200,分类为2,标准差为5的数据集
X,y = make_blobs(n_samples=200,centers=2,cluster_std=5)
#将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=38)
#对数据进行预处理
scaler = StandardScaler().fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
#将处理后的数据形态进行打印
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
#将处理后的数据形态进行打印
print('训练数据集:{}'.format(X_train_scaled.shape),' 标签形态:{}'.format(X_test_scaled.shape))
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
训练数据集:(150, 2) 标签形态:(50, 2)
====================================
#训练原始数据集
plt.scatter(X_train[:,0],X_train[:,1])
#经过预处理的训练集
plt.scatter(X_train_scaled[:,0],X_train_scaled[:,1],marker='^',edgecolor='k')
#添加图题
plt.title('training set & scaled training set')
#显示图片
plt.show()
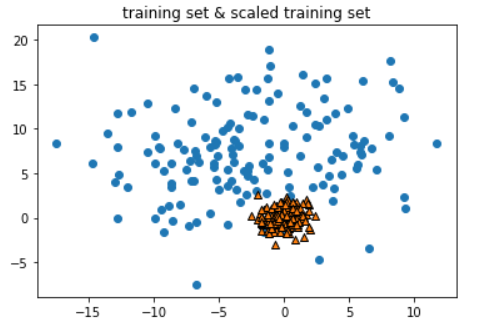
- 这里可以看到,StandardScaler将训练集的数据变得更加"聚拢"
#导入网格搜索
from sklearn.model_selection import GridSearchCV
#设定网格搜索的模型参数字典
params = {'hidden_layer_sizes':[(50,),(100,),(100,100)],'alpha':[0.0001,0.01,0.1]}
#建立网格搜索模型
grid = GridSearchCV(MLPClassifier(max_iter=1600,random_state=38),param_grid=params,cv=3,iid=False)
#拟合数据
grid.fit(X_train_scaled,y_train)
#将结果进行打印
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
print('模型最佳得分:{:.2f}'.format(grid.best_score_),' 模型最佳参数:{}'.format(grid.best_params_))
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
模型最佳得分:0.81 模型最佳参数:{'alpha': 0.0001, 'hidden_layer_sizes': (50,)}
====================================
#打印模型在测试集中的得分
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
print('测试集得分:{}'.format(grid.score(X_test_scaled,y_test)))
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
测试集得分:0.82
====================================
- 可以看到这种做法得到的模型分数很高,但是仔细想想这种做法是错误的,我们在交叉验证中,将训练集又拆分成了training fold和validation fold,但用StandardScaler进行预处理的时候,是使用training fold 和 validation fold 一起进行的拟合.这样一来,交叉验证的得分就是不准确的.
2.使用管道模型(Pipeline)
#导入管道模型
from sklearn.pipeline import Pipeline
#建立包含预处理和神经网络的管道模型
pipeline = Pipeline([('scaler',StandardScaler()),('mlp',MLPClassifier(max_iter=1600,random_state=38))])
#用管道模型对训练集进行拟合
pipeline.fit(X_train,y_train)
#打印管道模型的分数
print('使用管道模型的MLP模型评分:{:.2f}'.format(pipeline.score(X_test,y_test)))
使用管道模型的MLP模型评分:0.82
- 我们在管道模型Pipeline中使用了两个方法,一个是用来进行数据预处理的StandardScaler.另一个是最大迭代数为1600的MLP多层感知器神经网络.
3.使用管道模型进行网格搜索
GridSearchCV拆分的训练集和验证集,不是train_test_split拆分的训练集和测试集,而是在train_test_split拆分的训练集上再进行拆分,所得到的的结果
#设置参数字典--------(mlp__是用于指定pipeline中的mlp算法)
params = {'mlp__hidden_layer_sizes':[(50,),(100,),(100,100)],'mlp__alpha':[0.0001,0.001,0.01,0.1]}
#建立包含预处理和神经网络的管道模型
pipeline = Pipeline([('scaler',StandardScaler()),('mlp',MLPClassifier(max_iter=1600,random_state=38))])
#将管道模型加入网格搜索
grid = GridSearchCV(pipeline,param_grid=params,cv=3,iid=False)
#对训练集进行拟合
grid.fit(X_train,y_train)
#打印模型交叉验证分数.最佳参数和测试集得分
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
print('交叉验证最高分:{:.2f}'.format(grid.best_score_))
print('模型最有参数:{}'.format(grid.best_params_))
print('测试集得分:{}'.format(grid.score(X_test,y_test)))
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
交叉验证最高分:0.80
模型最有参数:{'mlp__alpha': 0.0001, 'mlp__hidden_layer_sizes': (50,)}
测试集得分:0.82
====================================
- 在hidden_layer_sizes和alpha前面都添加了mlp__这样一个前缀,这样做是为了pipeline中有多个算法,我们需要让pipeline知道这个参数是传给哪一个算法的.
#打印管道模型中的步骤
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
print(pipeline.steps)
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
[('scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('mlp', MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=1600, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=38, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False))]
====================================
总结 :
除了能够将更多的算法进行整合,实现代码的简洁之外,管道模型还可以避免我们在预处理过程中,使用不当的方式对训练集和验证集进行错误的预处理.通过使用管道模型,可以在网格搜索每次拆分训练集与验证集之前,重新对训练集和验证集进行预处理操作,避免了模型过拟合的情况.
文章引自 : 《深入浅出python机器学习》
管道模型(Pipeline)的更多相关文章
- 浅谈管道模型(Pipeline)
本篇和大家谈谈一种通用的设计与处理模型--Pipeline(管道). Pipeline简单介绍 Pipeline模型最早被使用在Unix操作系统中.据称,假设说Unix是计算机文明中最伟大的发明,那么 ...
- .NET客户端实现Redis中的管道(PipeLine)与事物(Transactions)
序言 Redis中的管道(PipeLine)特性:简述一下就是,Redis如何从客户端一次发送多个命令,服务端到客户端如何一次性响应多个命令. Redis使用的是客户端-服务器模型和请求/响应协议的T ...
- Redis中的管道(PipeLine)与事物(Transactions)
Redis中的管道(PipeLine)与事物(Transactions) 序言 Redis中的管道(PipeLine)特性:简述一下就是,Redis如何从客户端一次发送多个命令,服务端到客户端如何一次 ...
- Asp.net管道模型之(HttpModules 和 HttpHandler)
上一节我们从大概范围介绍了管道模型的整体流程,我们从其中知道管道最重要的两大组件为:HttpModules 跟 HttpHandler.今天我们着重来介绍一下这两大组件 一:asp.net处理管道 从 ...
- ASP.NET CORE 管道模型及中间件使用解读
说到ASP.NET CORE 管道模型不得不先来看看之前的ASP.NET 的管道模型,两者差异很大,.NET CORE 3.1 后完全重新设计了框架的底层,.net core 3.1 的管道模型更加灵 ...
- ASP.NET Web API 管道模型
ASP.NET Web API 管道模型 前言 ASP.NET Web API是一个独立的框架,也有着自己的一套消息处理管道,不管是在WebHost宿主环境还是在SelfHost宿主环境请求和响应都是 ...
- Redis学习笔记7--Redis管道(pipeline)
redis是一个cs模式的tcp server,使用和http类似的请求响应协议.一个client可以通过一个socket连接发起多个请求命令.每个请求命令发出后client通常会阻塞并等待redis ...
- Asp.net管道模型(管线模型)
Asp.net管道模型(管线模型) 前言 为什么我会起这样的一个标题,其实我原本只想了解asp.net的管道模型而已,但在查看资料的时候遇到不明白的地方又横向地查阅了其他相关的资料,而收获比当初预 ...
- 使用管道(PipeLine)和批量(Batch)操作
使用管道(PipeLine)和批量(Batch)操作 前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为product ...
随机推荐
- 第10组 Beta冲刺(5/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 将数据分析以可视化形式展示出来 新增数据分析展示等功能API 服务器后端部署, ...
- 微信小程序实例:分享给一个人还是分享到群的判断代码
微信小程序的分享功能,在最新版库的ide上已经不能拿到分享回调了,官方api也删除了对应的回调函数,看样子是砍掉了,不过真机测试还是可以的,话不多说,上代码: /* // 分享功能回调 onLoad: ...
- 深度强化学习 之 运行环境 mujoco 报错 ERROR: GLEW initalization error: Missing GL version
使用 mujoco环境 运行代码,报错 ERROR: GLEW initalization error: Missing GL version 一直无法解决,发现网址: https://blog. ...
- osg指定向量旋转指定角度
向量AB,沿着n旋转10度 osg::Vec3 left = AB*osg::Matrix::rotate(osg::inDegrees(10), n); osg::Vec3 right = AB*o ...
- win10 启动后会自动恢复上次关机前的应用
转载:https://www.v2ex.com/t/425101
- [LeetCode] 857. Minimum Cost to Hire K Workers 雇K个工人的最小花费
There are N workers. The i-th worker has a quality[i] and a minimum wage expectation wage[i]. Now w ...
- Jenkins - 插件管理
1 - Jenkins插件 Jenkins通过插件来增强功能,可以集成不同的构建工具.云平台.分析和发布工具等,从而满足不同组织或用户的需求. Jenkins 提供了不同的的方法来安装插件(需要不同级 ...
- 【视频开发】四大图像库:OpenCV/FreeImage/CImg/CxImage
1.对OpenCV 的印象:功能十分的强大,而且支持目前先进的图像处理技术,体系十分完善,操作手册很详细,手册首先给大家补计算机视觉的知识,几乎涵盖了近10年内的主流算法: 然后将图像格式和矩阵运算, ...
- vue-cli3 每次打包都改变css img js文件名,还有自带版本号
let Version = new Date().getTime(); css: { // 是否使用css分离插件 ExtractTextPlugin extract: { //一种方式,打包后的cs ...
- html5+springboot+websocket的简单实现
环境 window7,IntelliJ IDEA 2019.2 x64 背景:利用IntelliJ来搭建springboot框架,之后来实现websocket的功能.websocket只是实现了画面上 ...