利用pipeline批量插入数据到redis
在推荐系统中,推荐候选集格式一般是,itemid itemid_list。要把itemid作为key,推荐列表作为value批量插入到redis。
比如文件cf.data为:
cf_763500210 342900215:0.210596124675,372400335:0.209455077845,663500334:0.0450228848833,771300304:0.303416465385
cf_4272909287 0197309320:1.0,1977309242:1.0,2171809288:0.987105477748,4041809109:1.0,4247509287:0.61113311824,4306209287:1.0,4687609332:0.842522148763,5364909320:1.0,7006909116:1.0,7578709264:0.300615689335,9405509328:0.710187812454,9578209232:1.0,9869609287:0.808605591539
在item前加cf,是为了标注此推荐候选集是有CF算法计算得到的。
cat cf.data | awk -F "\t" '{print "set" " " $1 " " $2}' > cf.insert
cat cf.insert | /home/app/redis-4.0.9/src/redis-cli --pipe
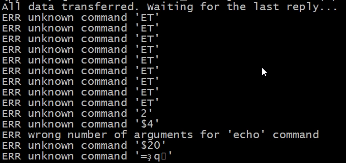
这时候会报错,那是字符编码格式问题,我的系统环境是LINUX。提前说一下哦,避免不必要的误会。
unix2dos data.insert

此时,可以看到5条数据批量插入成功,0个错误。
如果数据量很大,一次插入可能会报错,那就得做数据分片
#创建一个临时文件夹tmp
mkdir tmp
cd tmp
cp ../cf.insert cf.insert #将数据拷贝过来
#对文件进行分片处理
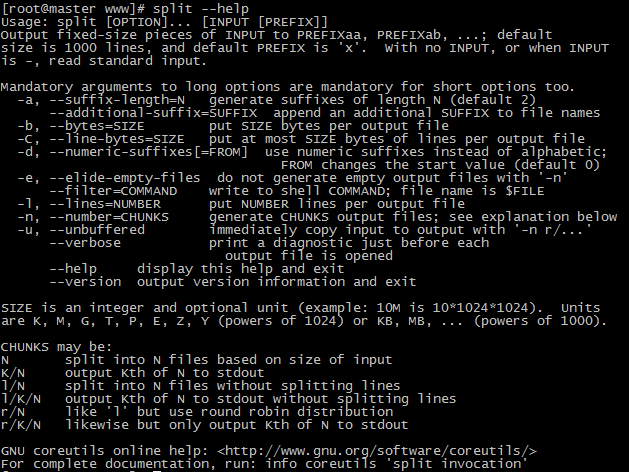
split cf.insert
#处理完,把文件删除
rm -rf cf.insert
#用shell脚本执行插入命令
for i in `ls`; do cat $i | /home/app/redis-4.0.9/src/redis-cli --pipe; done;
注意:ls使用Tab键上面的反引号括起来的。
`` 符号在shell里面正式的名称叫做backquote , 一般叫做命令替换
其作用是将引用命令的输出替换到字符串或者变量
通常如果需要在一个序列中用到其它命令的输出,就可以用``
split命令的使用
利用pipeline批量插入数据到redis的更多相关文章
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- mysql利用存储过程批量插入数据
最近需要测试一下mysql单表数据达到1000W条以上时增删改查的性能.由于没有现成的数据,因此自己构造,本文只是实例,以及简单的介绍. 首先当然是建表: [sql]view plaincopy CR ...
- 利用procedure批量插入数据
正文 要求在页面查询到5000条数据,为了方便插入,准备用shell脚本写curl命令调用自己写的代码接口,但是速度慢,而且写的时候遇到点儿小问题,故用sql语句写了这个功能 由于operat ...
- sqlalchemy ORM进阶- 批量插入数据
参考: https://www.jb51.net/article/49789.htm https://blog.csdn.net/littlely_ll/article/details/8270687 ...
- 在Redis集群中使用pipeline批量插入
在Redis集群中使用pipeline批量插入 由于项目中需要使用批量插入功能, 所以在网上查找到了Redis 批量插入可以使用pipeline来高效的插入, 示例代码如下: Pipeline p = ...
- django基础之day08,利用bulk_create 批量插入成千上万条数据
bulk_create批量插入数据 models.py文件 class Book(models.Model): title=models.CharField(max_length=32) urls.p ...
- SQLServer 批量插入数据的两种方法
SQLServer 批量插入数据的两种方法-发布:dxy 字体:[增加 减小] 类型:转载 在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Ins ...
- SQL 2005批量插入数据的二种方法
SQL 2005批量插入数据的二种方法 Posted on 2010-07-22 18:13 moss_tan_jun 阅读(2635) 评论(2) 编辑 收藏 在SQL Server 中插入一条数据 ...
- django----Sweetalert bulk_create批量插入数据 自定义分页器
目录 一.Sweetalert使用AJAX操作 二.bulk_create 三.分页器 divmod 分页器组件 自定义分页器的使用 一.Sweetalert使用AJAX操作 sweetalert ...
随机推荐
- BZOJ 1083 [SCOI2005]繁忙的都市 (最小生成树裸题无重边) 超简单写法!!
Description 城市C是一个非常繁忙的大都市,城市中的道路十分的拥挤,于是市长决定对其中的道路进行改造.城市C的道路是这样分布的:城市中有n个交叉路口,有些交叉路口之间有道路相连,两个交叉路口 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - Redis
文章目录 1. 环境依赖 2. 数据源 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 3. 使用 redisTemplate 操作4. 总结 3.1. 工具类 ...
- 大数据-04-Hbase入门
本文主要来自于 http://dblab.xmu.edu.cn/blog/install-hbase/ 谢谢原作者 本指南介绍了HBase,并详细指引读者安装HBase. 前面第二章学习指南已经指导大 ...
- python list和numpy互换
http://blog.csdn.net/baiyu9821179/article/details/53365476
- Java基础(1)IntelliJ IDEA入门、常用快捷键和数组操作
一. IntelliJ IDEA入门 1 快捷键和技巧 智能补全代码,比如只写首字母按回车: psvm+Enter :public stactic void main(String[] args) s ...
- ORA-03001,GATHER_TABLE_STATS数据库自动收集统计信息报错
1.根据Alert报错信息,查询Trace日志 /oracle/app/oracle/admin/fgsquery/bdump/fgsquery_j001_11111.trc Oracle Datab ...
- Linux内存压力测试stressapptest
/********************************************************************** * Linux内存压力测试stressapptest * ...
- Nginx配置之location模块和proxy模块
1.location指令的用法介绍 Location主要用来匹配url,如:http://www.beyond.com/nice,在这里对于location来说www.beyond.com是域名,/n ...
- 服务器死机 导致 mongo 挂掉
1.删除mongod.lock和mongodb.log日志文件 2.携带参数重新启动 mongod --dbpath=/var/lib/mongo --port=27017 --fork --logp ...
- SkyWalking+SkyApm-dotnet分布式链路追踪系统
SkyWalking+SkyApm-dotnet分布式链路追踪系统 对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操 ...