【Python】爬虫-2
8、 urllib2.urlopen可以接受一个Request对象或者url,(在接受Request对象时候,并以此可以来设置一个URL的headers),urllib.urlopen只接收一个url
9、 urllib 有urlencode,urllib2没有,这也是为什么总是urllib,urllib2常会一起使用的原因
10、 urlencode不能直接处理unicode对象,所以如果是unicode,需要先编码,有unicode转到utf8,举例:
urllib.urlencode (u'bl'.encode('utf-8'))
11、 编解码示例 urllib.quote(空格用%20代替)和urllib.urlencode(空格用+代替)都是编码,但用法不一样

8、 IV. urlretrieve() urlretrieve多数适用单纯的只下载的功能或者显示下载的进度,直接把url链接网页内容下载到retrieve_index.html里了,适用于单纯的下载的功能

8、 在对字典数据编码时候,用到的是urllib.urlencode()
9、 Scrapy组成
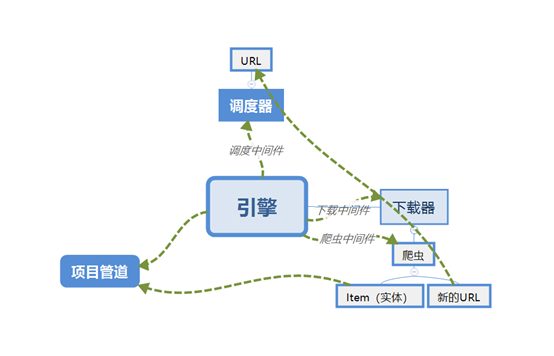
(1)引擎(Scrapy Engine):用来处理整个系统的数据流处理,触发事务。
(2)调度器(Scheduler):用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以决定下载器下一步要下载的网址并去除重复的网址。
(3)下载器(Downloader):用来下载网页内容,并将网页内容返回给爬虫(Spiders)。
(4)爬虫(Spiders):从特定的网页中提取出需要的信息。可以用它来制定特定网页的解析规则,提取特定的实体(Item)或URL链接。每一个Spider负责一个或多个特定的网站。
(5)项目管道(Item Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(6)下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(7)爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
(8)调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,处理从Scrapy引擎发送到调度的请求和响应。
10、 Scrapy执行流程
(1) 创建一个Scrapy项目
(2) 引擎从调度器取出一个URL用于抓取
(3) 引擎把URL封装成一个Requests请求然后传给下载器把相应结果下载下来并封装成应答包
(4) 解析应答包
(5) 定义解析规则(Item)
(6) 根据定义规则解析内容后交给实体管道等待处理
(7) 解析出URL交给调度器继续等待被抓取
【Python】爬虫-2的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- linux 查看日志命令
linux中命令cat.more.less均可用来查看文件内容, 区别:cat是一次性显示整个文件的内容,还可以将多个文件连接起来显示,它常与重定向符号配合使用,适用于文件内容少的情况:more和le ...
- blog项目知识点梳理
1.获取图片验证码: def get_validCode_img(request): # 方式1: # import os # path= os.path.join(settings.BASE_DIR ...
- 详解Oracle数据字典
Oracle通过数据字典来管理和展现数据库信息,数据字典通常储存数据库的元数据,是数据库的“数据库”.通常说的数据字典由4部分组成:内部RDBMS(X$)表.数据字典表.动态性能视图(V$)和(静态) ...
- C# 条件表达式max=(a>b)?a:b;含义
a?b:c 这个是条件表达式,表示如果a为真,则表达式值为b,如果a为假,则表达式值为c条件表达式具体说明如下条件语句: if(a>b) max=a; else max=b; 可用条件表达式写为 ...
- Shiro集成web环境[Springboot]-基础使用
Shiro集成web环境[Springboot] 1.shiro官网查找依赖的jar,其中shiro-ehcache做授权缓存时使用,另外还需要导入ehcache的jar包 <dependenc ...
- SpringMVC+HibernateValidator,配置在properties文件中的错误信息回显前端页面出现中文乱码
问题: 后台在springMVC中使用hibernate-validator做参数校验的时候(validator具体使用方法见GOOGLE),用properties文件配置了校验失败的错误信息.发现回 ...
- Django之权限管理插件
一.功能分析: 一个成熟的web应用,对权限的控制.管理是不可少的:对于一个web应用来说是什么权限? 这要从web应用的使用说起,用户在浏览器输入一个url,访问server端,server端返回这 ...
- Weblogic项目部署教程
说明: 其实Weblogic是允许直接以文件夹形式发布项目的,WAR包和文件夹发部的效果没有什么区别. 对于Eclipse项目,导出的WAR包其实确实只是项目下的WebContent文件夹中的内容,所 ...
- 微信UnionId 部分开放
以前要获得UnionID, 需要把公众号绑定到微信开放平台, 这个微信开放平台垃圾,还要300认证费. 今天突然发现在这个接口 https://api.weixin.qq.com/cgi-bin/us ...
- 文献管理软件zotero的一点使用感受作者: 杨林畅
作者是我的本科同学叶家鑫 http://www.renren.com/profile.do?id=240875124 文章写于去年12月,我做了一些排版上的修改,括号内的蓝字为我所加 ---- zot ...