Linux -- 之HDFS实现自动切换HA(全新HDFS)
Linux -- 之HDFS实现自动切换HA(全新HDFS)
JDK规划
1.7及以上 https://blog.csdn.net/meiLin_Ya/article/details/80650945
防火墙规划
系统防火墙关闭
SSH免密码规划
hadoop01(nn1)--> hadoop01(nn1) 需要免密码
hadoop01(nn1)--> hadoop02(nn2) 需要免密码
hadoop01(nn1)--> hadoop03(dn) 需要免密码
hadoop02(nn2)--> hadoop01(nn1) 需要免密码
hadoop02(nn2)--> hadoop02(nn2) 需要免密码
hadoop02(nn2)--> hadoop03(dn) 需要免密码
如果多节点之间全部免密码更好(生产环境不建议) 默认环境
Zk集群规划
已有可用zk集群 https://blog.csdn.net/meiLin_Ya/article/details/80654268
开始配置
首先我们要将所有的hadoop删除干净。如/temp /hadoopdata 等等,然后将hadoop的压缩包导入。你的集群中的每个节点也是,都要删除的。
删除后解压hadoop:
tar zxvf hadoop-2.6.0.tar.gz
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://beiwang</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopdata/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
修改hdfs-site.xml
注意:中文注释不要带
<configuration>
<!-- 指定hdfs的nameservice为beiwang,就是那个代理程序,询问zk集群哪个namenode还活着 -->
<property>
<name>dfs.nameservices</name>
<value>beiwang</value>
</property>
<!—指定hdfs的两个NameNode都是什么名字(等会儿下面会配置他们所对应的机器的信息)-->
<property>
<name>dfs.ha.namenodes.beiwang</name>
<value>nn1,nn2</value>
</property>
<!—NameNode1的rpc通讯地址-->
<property>
<name>dfs.namenode.rpc-address.beiwang.nn1</name>
<value> hadoop01:8020</value>
</property>
<!—NameNode2的rpc通讯地址-->
<property>
<name>dfs.namenode.rpc-address.beiwang.nn2</name>
<value> hadoop02:8020</value>
</property>
<!—NameNode1的web界面地址-->
<property>
<name>dfs.namenode.http-address.beiwang.nn1</name>
<value> hadoop01:50070</value>
</property>
<!—NameNode2的web界面地址-->
<property>
<name>dfs.namenode.http-address.beiwang.nn2</name>
<value> hadoop02:50070</value>
</property>
######如果给一个有数据的HDFS添加HA,此处无需更改,保持原有地址即可#####
<!---namenode存放元数据信息的Linux本地地址,这个目录不需要我们自己创建->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hdfs/name</value>
</property>
<!—datanode存放用户提交的大文件的本地Linux地址,这个目录不需要我们自己创建-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hdfs/data</value>
</property>
###########################################################
<!—QJM存放共享数据的方式-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal:// hadoop01:8485; hadoop02:8485; hadoop03:8485/beiwang</value>
</property>
<!—单个QJM进程(角色)存放本地edits文件的Linux地址-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/bigdata/hadoop/journal1</value>
</property>
<!—开启hdfs的namenode死亡后自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群地址,辅助两个namenode进行失败切换 -->
<property>
<name>ha.zookeeper.quorum</name>
<value> hadoop01:2181, hadoop02:2181, hadoop03:2181</value>
</property>
<!—zkfc程序的主类-->
<property>
<name>dfs.client.failover.proxy.provider.beiwang</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!—防止多个namenode同时active(脑裂)的方式-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!—指定本机的私钥所在目录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!—指定ssh通讯超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME="/home/bigdata/jdk1.8.0_161"
建一个master文本在hadoop-2.6.0/etc/hadoop/
注意:
新建master文件,该文件中写 所有namenode主机
hu-hadoop1
hu-hadoop2
hu-hadoop3
slaves:
hu-hadoop1
hu-hadoop2
hu-hadoop3
开启日志文件:
hadoop-daemons.sh start journalnode

启动zookeeper:
zkServer.sh start


然后进行格式化:
hadoop namenode -format
在master上开启namenode
hadoop-daemon.sh start namenode

在salve11机上 同步元数据信息
hdfs namenode -bootstrapStandby
格式化ZK(在Master上执行即可)
# hdfs zkfc -formatZK

格式化后可以查看zookeeper存放文件:
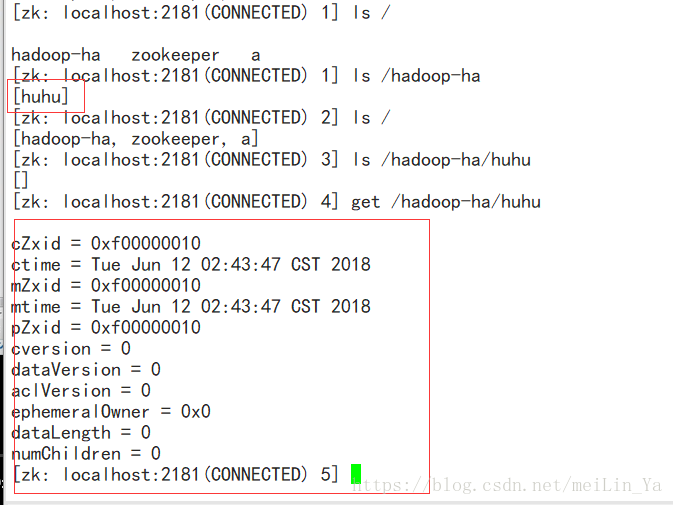
启动dfs:然后再查看zookeeper
start-dfs.sh

进入网页:
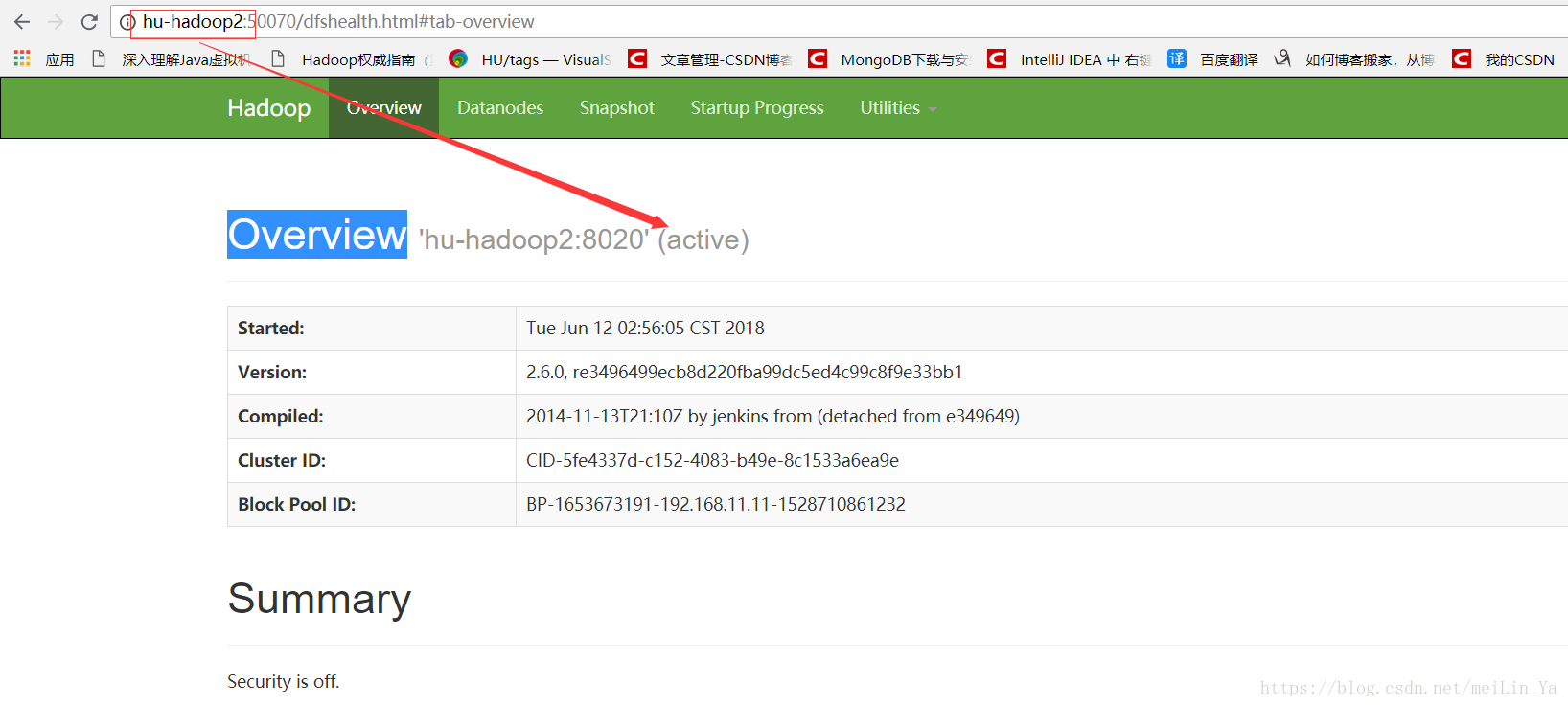

现在我们来测试下,杀死hu-hadoop2 ,然后看hu-hadoop1是否 可以从 standby=>active

然后我们再启动下刚刚的hu-hadoop2:查看它的状态
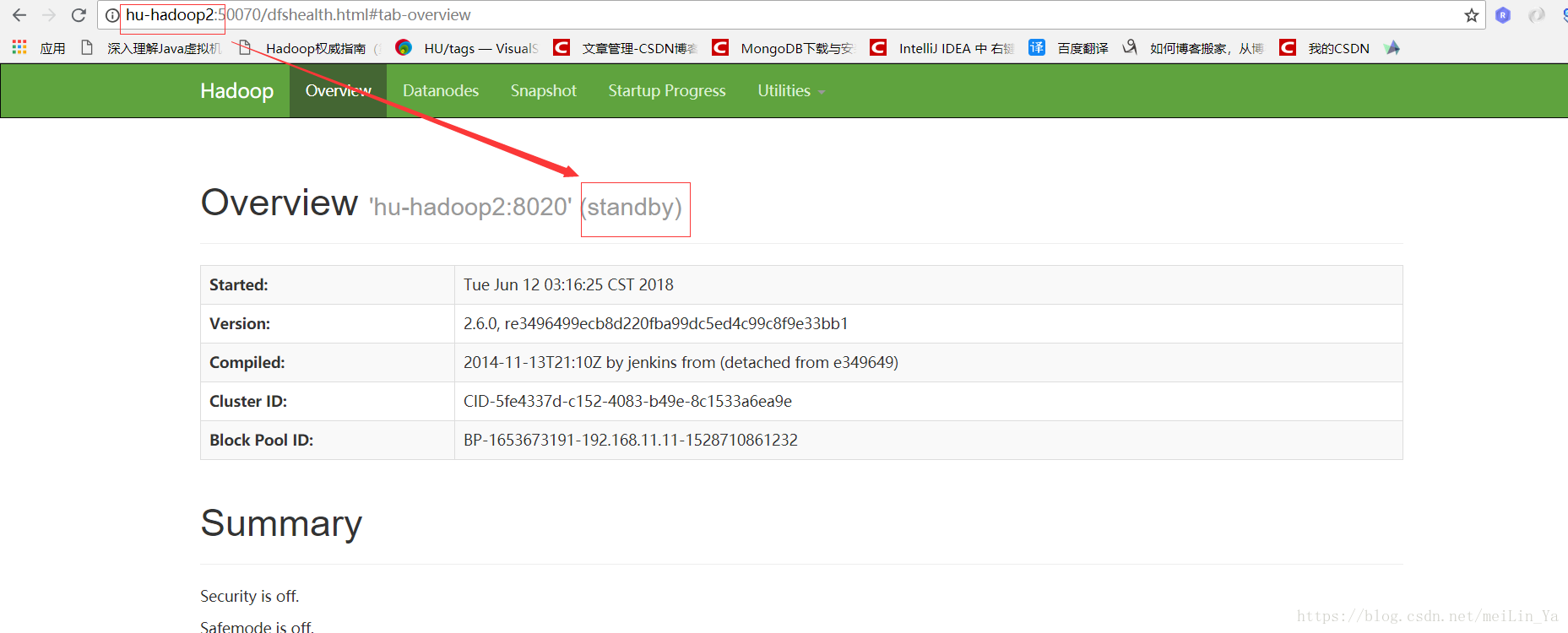
很明确的看出来了吧
然后我们看看zookeeper
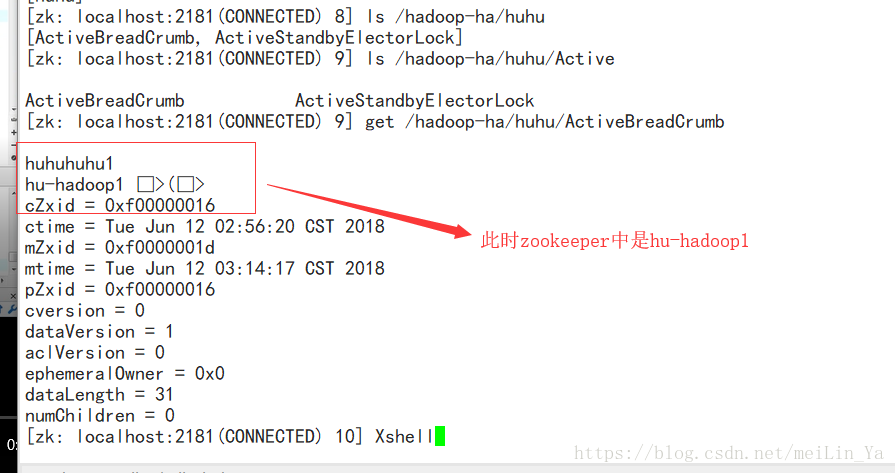
然后现在我们去杀掉hu-hadoop1:再看zookeeper
当然此时网页hu-hadoop2又从刚刚的standby==>active

这是为什么呢?
记得我们前面做了一步 hdfs zkfc -formatZK 这一步就是将hdfs信息记录到zookeeper,还有hdfs-core.xml中的配置。
这就是zookeeper的强大之处。我们可以将zookeeper理解为数据库,而它和数据库又不太是因为他是一个树形,只有在树枝的末梢才会存储数据。它的大小有1MB,不要小看它的1MB,它的作用比你想象的要强大
再记录下我运行成功后的配置文件吧
hadoop-env.sh
export JAVA_HOME="/home/bigdata/jdk1.8.0_161"
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://huhu</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopdata/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>huhu</value>
</property>
<property>
<name>dfs.ha.namenodes.huhu</name>
<value>huhu1,huhu2</value>
</property> <property>
<name>dfs.namenode.rpc-address.huhu.huhu1</name>
<value>hu-hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.huhu.huhu2</name>
<value>hu-hadoop2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.huhu.huhu1</name>
<value>hu-hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.huhu.huhu2</name>
<value>hu-hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hu-hadoop1:8485;hu-hadoop2:8485;hu-hadoop3:8485/huhu</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/bigdata/hadoop/journal1</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hu-hadoop1:2181,hu-hadoop2:2181,hu-hadoop3:2181</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.huhu</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>beiwangyarn</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hu-hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hu-hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hu-hadoop1:2181,hu-hadoop2:2181,hu-hadoop3:2181</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hu-hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hu-hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hu-hadoop1:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hu-hadoop1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hu-hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hu-hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hu-hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hu-hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hu-hadoop2:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hu-hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hu-hadoop2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hu-hadoop2:8033</value>
</property>
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/tmp/pseudo-dist/yarn/local</value>
</property>
<name>yarn.nodemanager.log-dirs</name>
<value>/tmp/pseudo-dist/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hu-hadoop1:2181,hu-hadoop2:2181,hu-hadoop3:2181</value>
</property>
</configuration>
master
hu-hadoop1
hu-hadoop2
hu-hadoop3
slaves
hu-hadoop1
hu-hadoop2
hu-hadoop3
Linux -- 之HDFS实现自动切换HA(全新HDFS)的更多相关文章
- Hadoop2.2.0 自动切换HA环境搭建
自动切换的HA,比手动切换HA集群多了一个zookeeper集群 机器分配: zookeeper:hadoop4,hadoop5,hadoop6 namenode:hadoop4,hadoop5 da ...
- hadoop ha zkfc 异常自动切换机制和hdfs 没有空间问题解决
在我搭建hadoop ha 后,我启动了各个功能,但是发现hadoop hdfs 没法使用,在web 页面也显示hdfs 可用空间为零,并且自动备份机制无法使用,本人也不理解,然后就是指定hdfs t ...
- 【解决】HDFS HA无法自动切换问题
[解决]HDFS HA无法自动切换问题 原因: 最早设置为root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件.更改为hdfs账号免密钥登录恢复正常. ...
- hadoop搭建HA集群之后不能自动切换namenode
在搭好HA集群之后,想测试一下集群的高可用性,于是先把active的namenode给停掉: hadoop-daemon.sh stop namenode 或者直接kill掉该节点namenode的对 ...
- Linux登录自动切换root账户与历史命令优化
1:当我们Linux系统优化完成,会使用oldboy用户远程连接CRT登录,每次连接都需要使用sudo su - 或者su - 输入密码登录,请问如何在CRT连接的时候自动的切换到root账户,(提示 ...
- 一次goldengate故障引发的操作系统hang起,HA自动切换
现场: 跑着数据库的主机A报警应用连接不上数据库,我们无法ssh到主机.第一反应是通过telnet到远程控制口,发现数据库资源和硬件资源在被切换到HA架构的主机B(备机,通常性能比主机A的差,抗不住应 ...
- Linux自动切换用户
Linux自动切换用户 一.创建sh文件 touch su_user.sh 二.下载脚本 yum install -y expect 三.脚本内容 #!/bin/bash# This is our f ...
- HDFS High Availability(HA)高可用配置
高可用性(英语:high availability,缩写为 HA) IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度.是进行系统设计时的准则之一. 高可用性系统意味着系统服务可以更长时间 ...
- Hadoop2.2.0 手动切换HA环境搭建
ssh-copy-id -i hadoop5含义: 节点hadoop4上执行ssh-copy-id -i hadoop5的含义是把hadoop4上的公钥id_rsa.pub的内容追加到hadoop5的 ...
随机推荐
- C语言: 从 CodeBlocks 到 Microsoft Visual Studio 2017
开学到现在寒假,学习了一个学期的C语言,同时也已然用了大半年的 CodeBlocks 来写 C/C++ 程序.CodeBlocks 是写 C/C++ 语言的程序最轻量的IDE(集成开发环境),在 C ...
- _attribute_creature
生物属性控制表 comment 备注 Entry 生物ID,对就creature_template中entry Level 不等于0时改变等级为该值 Health 不等于0时改变生命值为该值 Atta ...
- C++图形开发相关
1. WxWidgets 2. GTK+ 3. U++ Framework 4. QT
- SpringBoot配置Aop demo
1. Demo部分 package com.example.demo.controller; import org.springframework.web.bind.annotation.Reques ...
- Oracel 中的分页
--效率低 select * from (select rownum rn, d.* from table d )p where p.rn<=20 and p.rn>=10; select ...
- JVM——Java虚拟机架构
0. 前言 Java虚拟机(Java virtualmachine)实现了Java语言最重要的特征:即平台无关性. 平台无关性原理:编译后的 Java程序(.class文件)由 JVM执行.JVM屏蔽 ...
- C++之初体验
#include<iostream> using namespace std; int main() { cout<<" Hello imooc "< ...
- MySQL学习(六)
1 注意 select cout(*) from 表名: 查询的就是绝对的行数,哪怕某一列所有字段全部为NULL,也计算在内.而select cout(列名) form 表名:查询的是该列不为null ...
- 虚拟机上自动化部署(EFI网络安装)ESXi服务器遇到的问题
1,虚拟机的CPU为2核或以上. 2,虚拟机选项中不选择: 启用UEFI安全引导.3,引导延迟:设置3000毫秒或以上 4,#GP Exception 13 in world 1:unknown @ ...
- angular2 学习笔记 (Typescript - Attribute & reflection & decorator)
更新 : 2018-11-27 { date: Date } 之前好像搞错了,这个是可以用 design:type 拿到的 { date: Date | null } 任何类型一但配上了 | 就 de ...