爬虫5_python2_使用 Beautiful Soup 解析数据
使用 Beautiful Soup 解析数据(感谢东哥)
有的小伙伴们对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HTML或XML标签中的内容,实在是方便,这一节就让我们一起来感受一下Beautiful Soup的魅力
1. Beautiful Soup的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
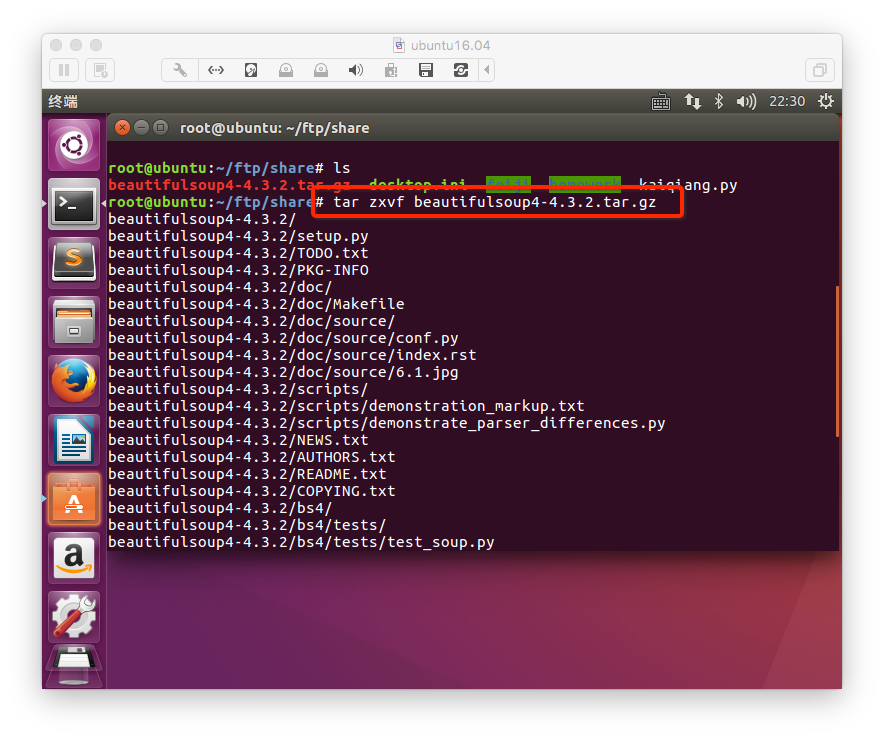
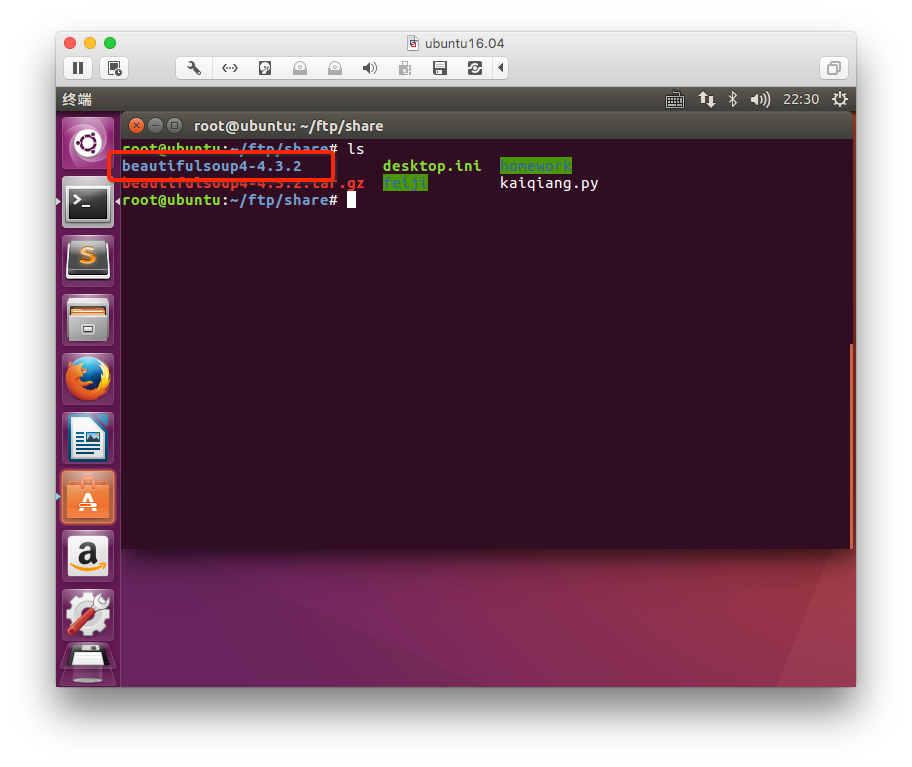
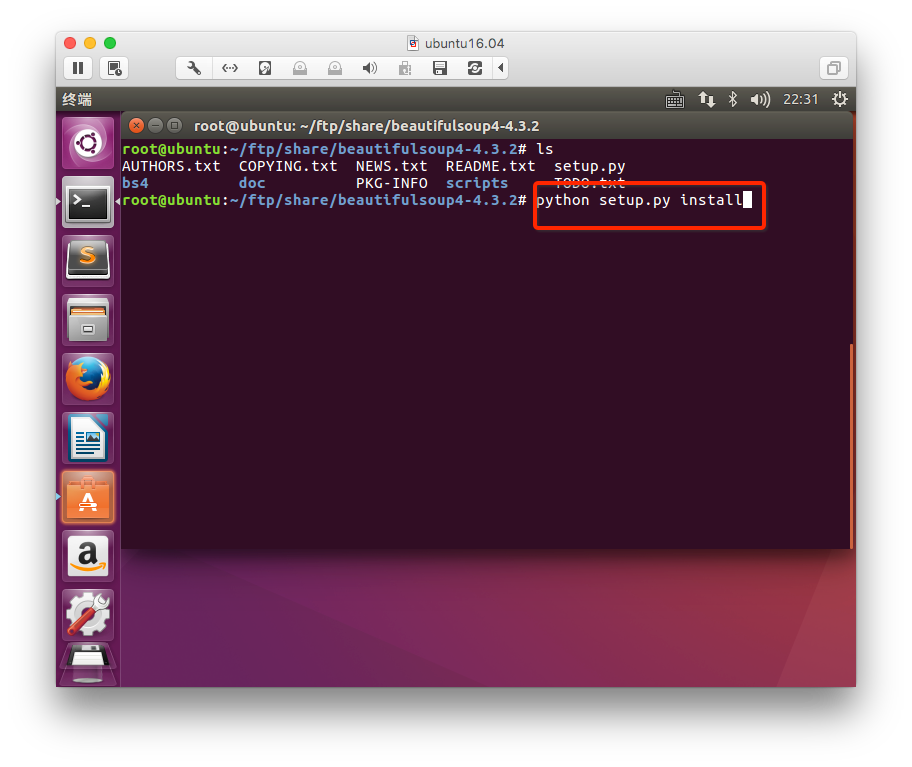
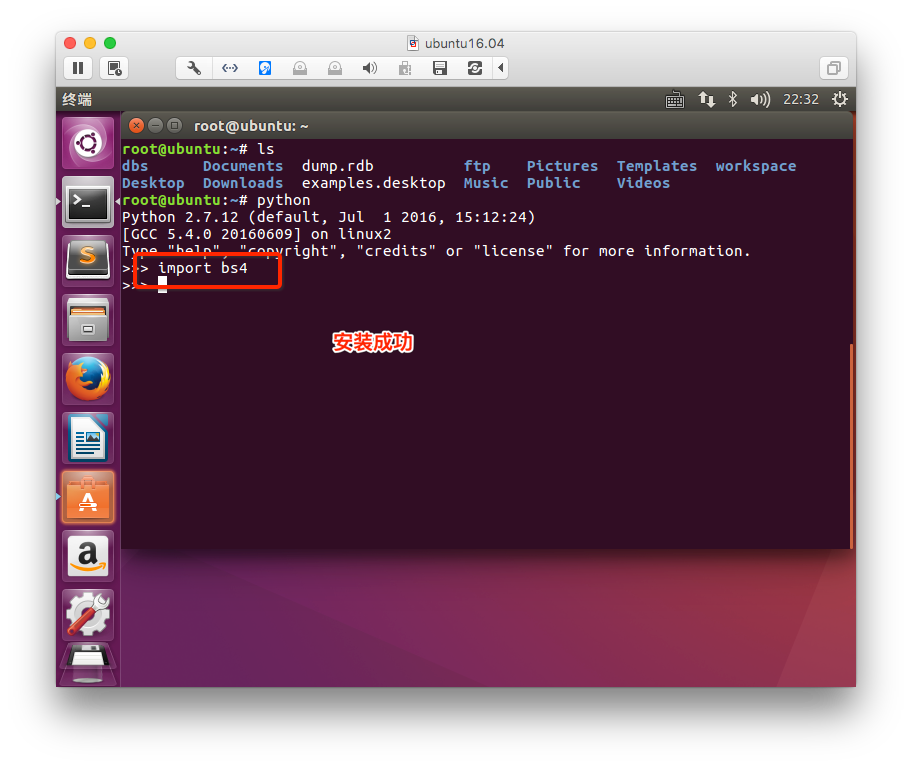
2. 安装
下载地址:https://pypi.python.org/pypi/beautifulsoup4/4.3.2
官方文档:http://beautifulsoup.readthedocs.org/zh_CN/latest
3. 使用
from bs4 import BeautifulSoup
我们创建一个字符串,后面的例子我们便会用它来演示
html = """<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
创建 beautifulsoup 对象
soup = BeautifulSoup(html)
下面我们来打印一下 soup 对象的内容,格式化输出
print soup.prettify()
3.1 找标签
直接打印标签
print soup.title
#<title>The Dormouse's story</title>
print soup.head
#<head><title>The Dormouse's story</title></head>
print soup.a
#<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.p
#<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
我们可以利用 soup加标签名轻松地获取这些标签的内容,是不是感觉比正则表达式方便多了?不过有一点是,它查找的是在所有内容中的第一个符合要求的标签
对于标签,它有两个重要的属性,是 name 和 attrs,下面我们分别来感受一下
print soup.name
print soup.head.name
#[document]
#head
soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称
print soup.p.attrs
#{'class': ['title'], 'name': 'dromouse'}
在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什么
print soup.p['class']
#['title']
3.2 获取文字
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例
print soup.p.string
#The Dormouse's story
3.3 CSS选择器
在CSS中,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
3.3.1 通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]
3.3.2 通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3.3.3 通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
3.3.4 组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
3.3.5 直接子标签查找
print soup.select("head > title")
#[<title>The Dormouse's story</title>]
3.3.6 属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
爬虫5_python2_使用 Beautiful Soup 解析数据的更多相关文章
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- Beautiful Soup解析库的安装和使用
Beautiful Soup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据.它拥有强大的API和多样的解析方式.官方文档:https://www.crummy.co ...
- 用Beautiful Soup解析html源码
#xiaodeng #python3 #用Beautiful Soup解析html源码 html_doc = """ <html> <head> ...
- 爬虫(五)—— 解析库(二)beautiful soup解析库
目录 解析库--beautiful soup 一.BeautifulSoup简介 二.安装模块 三.Beautiful Soup的基本使用 四.Beautiful Soup查找元素 1.查找文本.属性 ...
- Python爬虫系列(四):Beautiful Soup解析HTML之把HTML转成Python对象
在前几篇文章,我们学会了如何获取html文档内容,就是从url下载网页.今天开始,我们将讨论如何将html转成python对象,用python代码对文档进行分析. (牛小妹在学校折腾了好几天,也没把h ...
- Python爬虫利器:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.使用它来处理HTML页面就像JavaScript代码操作HTML DOM树一样方便.官方中文文档地址 1. 安 ...
- Beautiful Soup解析网页
使用前步骤: 1.Beautiful Soup目前已经被移植到bs4,所以导入Beautiful Soup时先安装bs4库. 2.安装lxml库:如果不使用此库,就会使用Python默认的解析器,而l ...
- Python Beautiful Soup 解析库的使用
Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Beautiful Soup是Python的一个HTML或XML的解析库. 1.解析器 解析 ...
- 爬虫系列二(数据清洗--->xpath解析数据)
一 xpath介绍 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 XML 文档中通过元素和属性进行导航. XPath 使用路径表达式在 XML 文档中进行导航 XPath 包 ...
随机推荐
- HTML学习笔记(一)HTML的一些概念区别
HTML HTML 指超文本标记语言.在 HTML 4 中,有若干的标签和属性是被废弃的,替换成style对应的属性 应该避免使用下面这些标签和属性: 标签 描述 style <center&g ...
- ObjectARX反应器概述[转载]
何为反应器? AutoCAD中提供了类似MFC消息机制的通知方式.用于处理以下情况: 执行AutoCAD命令.修改系统变量.保存和退出图形编辑器或者切换当前工作布局空间等等. 反应器机制是观察者模式的 ...
- C#基础知识回顾
值类型和引用类型 值类型存在栈上,结构,枚举,数值类型 引用类型存在堆上,数组,类,接口,委托 把值类型存到引用类型中就是封箱,耗时 引用类型中的值类型是存在堆上,不是栈上,但是作为参数传递时,还是会 ...
- iOS7 UITableView Row Height Estimation
This post is part of a daily series of posts introducing the most exciting new parts of iOS7 for dev ...
- linux 和windows 的定时任务
linux http://www.cnblogs.com/thinksasa/archive/2013/06/06/3121030.html windows http://www.myhack58.c ...
- one jar(转)
http://blog.csdn.net/kabini/article/details/1598827
- UINavigationController 的一些坑
坑一:自定义导航栏返回键 iOS7及之后版本 手势边缘右滑返回失效 解决方案: -(void)viewDidLoad{ [super viewDidLoad]; //self 为 UINavigati ...
- 用css固定textarea文本域大小尺寸
textarea元素在chrome等浏览器下可以被拖拉从而改变大小,对于查看textarea里面的内容来说相当方便,但是有时候 我们为了保持网页的美观,不得不想要禁掉这个功能,禁止用户随意拉动text ...
- 爬虫之图片懒加载技术、selenium和PhantomJS
爬虫之图片懒加载技术.selenium和PhantomJS 图片懒加载 selenium phantomJs 谷歌无头浏览器 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http:/ ...
- 牛客寒假6-J.迷宫
链接:https://ac.nowcoder.com/acm/contest/332/J 题意: 你在一个 n 行 m 列的网格迷宫中,迷宫的每一格要么为空,要么有一个障碍. 你当前在第 r 行第 c ...