Beautiful Soup解析网页
使用前步骤:
1.Beautiful Soup目前已经被移植到bs4,所以导入Beautiful Soup时先安装bs4库。
2.安装lxml库:如果不使用此库,就会使用Python默认的解析器,而lxml具有功能更加强大、速度更快的特点。
爬取:http://www.cntour.cn/
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
from bs4 import BeautifulSoup
import re url="http://www.cntour.cn/" #需要爬取的网址
strhtml = requests.get(url); #使用GET方式,获取网页数据 soup = BeautifulSoup(strhtml.text,'lxml') #HTML文档将被转换成Unicode
# 编码格式,然后BeautifulSoup选择最适合的解析器来解析文档,此处指定
# lxml解析器,解析后转换成属性结构,每个节点都是Python对象,保存在变量soup中
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #采用select选择器定位数据
for item in data: #数据清洗和组织数据
result = {
'title':item.get_text(), #获得a标签的文本内内容
'link':item.get('href'), #获得a标签的href属性
'ID':re.findall('\d+',item.get('href')) #使用正则匹配其中的数字,\d匹配数字,+匹配一个字符一次或多次
}
print(result)
结果:
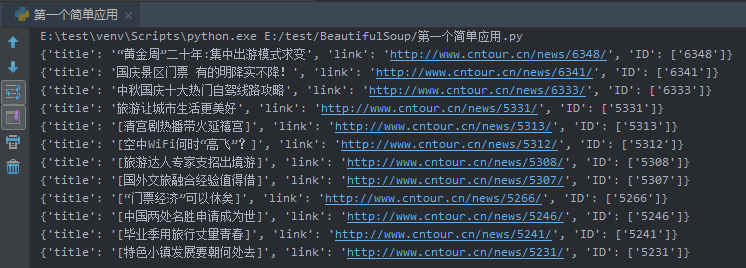
Beautiful Soup解析网页的更多相关文章
- Python Beautiful Soup 解析库的使用
Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Beautiful Soup是Python的一个HTML或XML的解析库. 1.解析器 解析 ...
- 爬虫5_python2_使用 Beautiful Soup 解析数据
使用 Beautiful Soup 解析数据(感谢东哥) 有的小伙伴们对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HT ...
- Beautiful Soup解析库的安装和使用
Beautiful Soup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据.它拥有强大的API和多样的解析方式.官方文档:https://www.crummy.co ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- 用Beautiful Soup解析html源码
#xiaodeng #python3 #用Beautiful Soup解析html源码 html_doc = """ <html> <head> ...
- Python爬虫系列(四):Beautiful Soup解析HTML之把HTML转成Python对象
在前几篇文章,我们学会了如何获取html文档内容,就是从url下载网页.今天开始,我们将讨论如何将html转成python对象,用python代码对文档进行分析. (牛小妹在学校折腾了好几天,也没把h ...
- 爬虫(五)—— 解析库(二)beautiful soup解析库
目录 解析库--beautiful soup 一.BeautifulSoup简介 二.安装模块 三.Beautiful Soup的基本使用 四.Beautiful Soup查找元素 1.查找文本.属性 ...
- Beautiful Soup 解析html表格
from bs4 import BeautifulSoup import urllib.request doc = urllib.request.urlopen('http://www.bkzy.or ...
- Python3编写网络爬虫06-基本解析库Beautiful Soup的使用
二.Beautiful Soup 简介 就是python的一个HTML或XML的解析库 可以用它来很方便的从网页中提取数据 0.1 提供一些简单的 python式的函数来处理导航,搜索,修改分析树等功 ...
随机推荐
- 301. Remove Invalid Parentheses去除不符合匹配规则的括号
[抄题]: Remove the minimum number of invalid parentheses in order to make the input string valid. Retu ...
- spring4-2-bean配置-6-使用外部属性文件
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAk0AAAFGCAIAAAD4tzxRAAAgAElEQVR4nO2d27HsOm+tOxWn4CeXAm ...
- Python Windows下打包成exe文件
Python Windows 下打包成exe文件,使用PyInstaller 软件环境: 1.OS:Win10 64 位 2.Python 3.7 3.安装PyInstaller 先检查是否已安装Py ...
- Ubuntu Phone开箱上手
在昨晚举行的发布会上Canonical和硬件厂商BQ进行合作,推出了首款面向消费市场的Ubuntu手机--Aquaris E4.5,带来了与常见的iPhone和Android机完全不同的操作体验,设备 ...
- 在OpenSSL中添加自定义加密算法
一.简介 本文以添加自定义算法EVP_ssf33为例,介绍在OpenSSL中添加自定义加密算法的方法 二.步骤 1.修改crypto/object/objects.txt,注册算法OID,如下: rs ...
- IntelliJ IDEA 安装
1.在终端输入sudo vim /private/etc/hosts 2.在打开的hosts文件中,在尾行添加 0.0.0.0 account.jetbrains.com 3.去网站http://id ...
- Sublime Text 2 安装配置插件
最近学习python,看网上推荐用sublime text2挺方便,就学习了一下对sublime text2 安装插件,先放在这里,以备以后查找 根据晚上资料修改,原文请看这里 Python的自动补全 ...
- [GO]结构体类型添加方法
package main import "fmt" type Person struct { name string sex byte age int } //带有接收者的函数叫方 ...
- jQuary总结6:元素的操作
1 empty方法 //html <div> <p></p> <span></span> </div> //js $('div) ...
- 创建EDM
在学习linq过程中,我们难免会要创建EDM,这里简单的介绍一下EDM的创建过程 图示如下: 1.右击→添加→新建项→数据→Ado.net实体数据模型 选择适当的数据库,表后点击完成,vs中会自动生成 ...