python numpy实现多次循环读取文件 等间隔过滤数据
numpy的np.fromfile会出现如下的问题,只能一次性读取文件的内容,不能追加读取,连续两次的np.fromfile读到的东西一样
如果数据文件太大(几个G或以上)不能一次性全读进去,需要追加读取
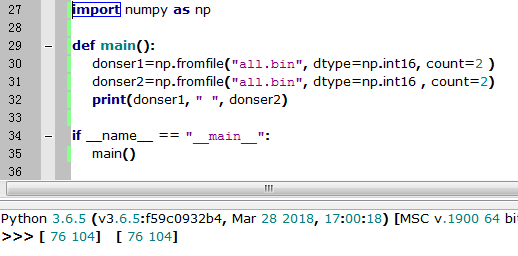
而我希望读到的donser1和donser2是连续的两段
(实际使用时,比如说读取的文件是二进制数据文件,每一块文件都包括包头+数据,希望将这两块分开获取,然后再做进一步处理)
代码:
import numpy as np length=2500
plt_arr=np.linspace(0.0, 0.0, length*2048*16)
start=0
tail_size = 40 #40bit
num_size=16*1024-40 # 16kb -40b def one_file(f, loop):
global tail_size, num_size
while loop:
num = np.fromfile(f, dtype=np.int16, count=num_size)
tail=np.fromfile(f, dtype=np.int16, count=tail_size)
loop=loop-1
yield num, tail def main():
file_path="E://1-gl300c.r3f"
global length, plt_arr, start
loop=length
with open(file_path, 'rb') as f:
for num, tail in one_file(f, loop):
plt_arr[start:start+len(num)]=num[:]
start=start+len(num)
return plt_arr[0:start] if __name__ == "__main__":
donser=main()
print(donser)
假设数据文件的格式是 数据+包尾,plt_arr存储全部的数据部分,包尾丢弃,该方法实现了多次连续追加读取数据文件的内容
plt_arr最好使用先开好大小再逐次赋值,亲测append方法和concatenate方法时间效率极差
或者不用numpy也可以,代码:
def read_in_chunks(filePath, chunk_size=16*1024):
file_object = open(filePath,'rb')
count=0
while True:
chunk_data = file_object.read(chunk_size)
if not chunk_data:
break
yield chunk_data[0:16*1024-28] if __name__ == "__main__":
num=0
for chunk in read_in_chunks("E:\\1-gl300c.r3f"):
#process(chunk) # <do something with chunk>
name=str(num)+".bin"
num=num+1
if num<303000:
continue
if num>308001:
break
file_object = open(name, 'wb')
file_object.write(chunk)
file_object.close( )
numpy.fromfile的其他方法可以参考这个
python numpy实现多次循环读取文件 等间隔过滤数据的更多相关文章
- php使用PHPexcel类读取excel文件(循环读取每个单元格的数据)
error_reporting(E_ALL); date_default_timezone_set('Asia/ShangHai'); include_once('Classes/PHPExcel/I ...
- Halcon中循环读取文件的实现以及数字与字符的转换
在循环读取文件的位置时,常用到数字与字符的转换. 数字与字符的转换 将字符转换为数字 tuple_number(StringImageIndex,IntImageIndex)` 1 2 1 2 将数字 ...
- 循环读取文件夹中的图片matlab代码
参考:http://blog.csdn.net/guoxiaojie_415/article/details/21317323:http://blog.csdn.net/qikaihuting/art ...
- Day16_95_IO_循环读取文件字节流read()方法(四)
循环读取文件字节流read()方法(四) 使用 int read(byte[] bytes) 循环读取字节流数据 import java.io.FileInputStream; import java ...
- Day16_94_IO_循环读取文件字节流read()方法(二)
循环读取文件字节流read()方法 通过read()循环读取数据,但是read()每次都只能读取一个字节,频繁读取磁盘对磁盘有伤害,且效率低. import java.io.FileInputStre ...
- python 3.x 循环读取文件用户登录
import os # 导入python自带库的模块 import sys # 导入python自带库的模块 import getpass # 导入python自带库的模块 lock_file = ' ...
- Matlab如何循环读取文件
循环读取图片第一种方法①List =dir('*.jpg'); %如需其它图片格式支持,可以自己[重载dir()]函数,实现查找所有图片文件的功能,%如果图片是其它路径,可以用 ["路径&q ...
- linux 循环读取文件的每一行
在Linux中有很多方法逐行读取一个文件的方法,其中最常用的就是下面的脚本里的方法,而且是效率最高,使用最多的方法.为了给大家一个直观的感受,我们将通过生成一个大的文件的方式来检验各种方法的执行效率. ...
- windows 和 linux 上 循环读取文件名称的区别和方法
function showGetFileName($type){ $url="/opt/mobile_system/gscdn"; //另一台服务器映射到linux过来的路径. # ...
随机推荐
- Service 回顾
绑定本地service需要实现onBind()方法
- PHP 教父鸟哥 Yar 的原理分析
模块越来越多,业务越来越复杂,RPC 就上场了,在 PHP 的世界里,鸟哥的作品一直备受广大网友的青睐.下面一起学习下鸟哥的 PRC 框架 Yar . 揭开 Yar 神秘面纱 RPC 采用客户端/服务 ...
- hdu3667
Transportation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- POJ 2181 Jumping Cows
Jumping Cows Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6398 Accepted: 3828 Desc ...
- JDBC 学习笔记(七)—— CallableStatement
在大型关系型数据库中,有一组为了完成特定功能的 SQL 语句集被称为存储过程(Stored Procedure),它是数据库中的对象. JDBC 使用 CallableStatement 对象,完成对 ...
- Mysql 数值类型
Mysql数值类型 整数型 小数型(浮点数) 日期时间型
- NOJ——1627Alex’s Game(II)(尺取)
[1627] Alex’s Game(II) 时间限制: 2000 ms 内存限制: 65535 K 问题描述 Alex likes to play with one and zero as you ...
- [AtCoderContest010D]Decrementing
[AtCoderContest010D]Decrementing 试题描述 There are \(N\) integers written on a blackboard. The \(i\)-th ...
- 平面凸包Graham算法
板题hdu1348Wall 平面凸包问题是计算几何中的一个经典问题 具体就是给出平面上的多个点,求一个最小的凸多边形,使得其包含所有的点 具体形象就类似平面上有若干柱子,一个人用绳子从外围将其紧紧缠绕 ...
- poj1734Sightseeing trip
Sightseeing trip Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6811 Accepted: 2602 ...