强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN。本章内容主要参考了ICML 2016的deep RL tutorial和Dueling DQN的论文<Dueling Network Architectures for Deep Reinforcement Learning>(ICML 2016)。
1. Dueling DQN的优化点考虑
在前面讲到的DDQN中,我们通过优化目标Q值的计算来优化算法,在Prioritized Replay DQN中,我们通过优化经验回放池按权重采样来优化算法。而在Dueling DQN中,我们尝试通过优化神经网络的结构来优化算法。
具体如何优化网络结构呢?Dueling DQN考虑将Q网络分成两部分,第一部分是仅仅与状态$S$有关,与具体要采用的动作$A$无关,这部分我们叫做价值函数部分,记做$V(S,w,\alpha)$,第二部分同时与状态状态$S$和动作$A$有关,这部分叫做优势函数(Advantage Function)部分,记为$A(S,A,w,\beta)$,那么最终我们的价值函数可以重新表示为:$$Q(S,A, w, \alpha, \beta) = V(S,w,\alpha) + A(S,A,w,\beta)$$
其中,$w$是公共部分的网络参数,而$\alpha$是价值函数独有部分的网络参数,而$\beta$是优势函数独有部分的网络参数。
2. Dueling DQN网络结构
由于Q网络的价值函数被分为两部分,因此Dueling DQN的网络结构也和之前的DQN不同。为了简化算法描述,这里不使用原论文的CNN网络结构,而是使用前面文中用到的最简单的三层神经网络来描述。是否使用CNN对Dueling DQN算法本身无影响。
在前面讲到的DDQN等DQN算法中,我使用了一个简单的三层神经网络:一个输入层,一个隐藏层和一个输出层。如下左图所示:
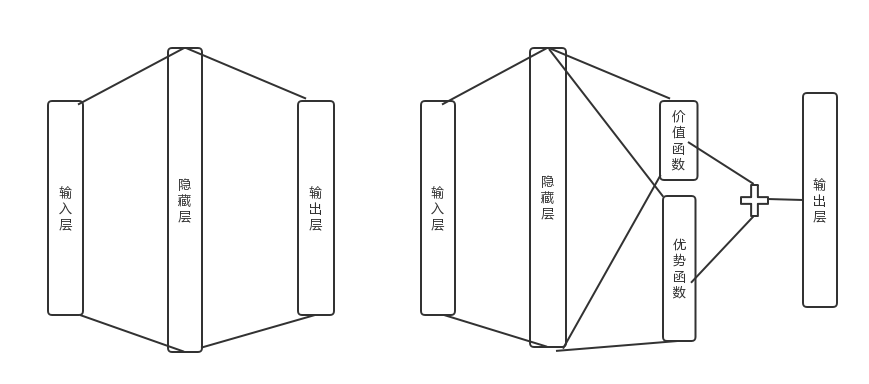
而在Dueling DQN中,我们在后面加了两个子网络结构,分别对应上面上到价格函数网络部分和优势函数网络部分。对应上面右图所示。最终Q网络的输出由价格函数网络的输出和优势函数网络的输出线性组合得到。
我们可以直接使用上一节的价值函数的组合公式得到我们的动作价值,但是这个式子无法辨识最终输出里面$V(S,w,\alpha)$和$A(S,A,w,\beta)$各自的作用,为了可以体现这种可辨识性(identifiability),实际使用的组合公式如下:$$Q(S,A, w, \alpha, \beta) = V(S,w,\alpha) + (A(S,A,w,\beta) - \frac{1}{\mathcal{A}}\sum\limits_{a' \in \mathcal{A}}A(S,a', w,\beta))$$
其实就是对优势函数部分做了中心化的处理。以上就是Duel DQN的主要算法思路。由于它仅仅涉及神经网络的中间结构的改进,现有的DQN算法可以在使用Duel DQN网络结构的基础上继续使用现有的算法。由于算法主流程和其他算法没有差异,这里就不单独讲Duel DQN的算法流程了。
3. Dueling DQN实例
下面我们用一个具体的例子来演示Dueling DQN的应用。仍然使用了OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v0游戏的介绍参见这里。它比较简单,基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征。坚持到200分的奖励则为过关。
这个实例代基于Nature DQN,并将网络结构改为上图中右边的Dueling DQN网络结构,完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/duel_dqn.py
这里我们重点关注Dueling DQN和Nature DQN的代码的不同之处。也就是网络结构定义部分,主要的代码如下,一共有两个相同结构的Q网络,每个Q网络都有状态函数和优势函数的定义,以及组合后的Q网络输出,如代码红色部分:
def create_Q_network(self):
# input layer
self.state_input = tf.placeholder("float", [None, self.state_dim])
# network weights
with tf.variable_scope('current_net'):
W1 = self.weight_variable([self.state_dim,20])
b1 = self.bias_variable([20]) # hidden layer 1
h_layer_1 = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) # hidden layer for state value
with tf.variable_scope('Value'):
W21= self.weight_variable([20,1])
b21 = self.bias_variable([1])
self.V = tf.matmul(h_layer_1, W21) + b21 # hidden layer for action value
with tf.variable_scope('Advantage'):
W22 = self.weight_variable([20,self.action_dim])
b22 = self.bias_variable([self.action_dim])
self.A = tf.matmul(h_layer_1, W22) + b22 # Q Value layer
self.Q_value = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) with tf.variable_scope('target_net'):
W1t = self.weight_variable([self.state_dim,20])
b1t = self.bias_variable([20]) # hidden layer 1
h_layer_1t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t) # hidden layer for state value
with tf.variable_scope('Value'):
W2v = self.weight_variable([20,1])
b2v = self.bias_variable([1])
self.VT = tf.matmul(h_layer_1t, W2v) + b2v # hidden layer for action value
with tf.variable_scope('Advantage'):
W2a = self.weight_variable([20,self.action_dim])
b2a = self.bias_variable([self.action_dim])
self.AT = tf.matmul(h_layer_1t, W2a) + b2a # Q Value layer
self.target_Q_value = self.VT + (self.AT - tf.reduce_mean(self.AT, axis=1, keep_dims=True))
其余部分代码和Nature DQN基本相同。当然,我们可以也在前面DDQN,Prioritized Replay DQN代码的基础上,把网络结构改成上面的定义,这样Dueling DQN也可以起作用。
4. DQN总结
DQN系列我花了5篇来讲解,一共5个前后有关联的算法:DQN(NIPS2013), Nature DQN, DDQN, Prioritized Replay DQN和Dueling DQN。目前使用的比较主流的是后面三种算法思路,这三种算法思路也是可以混着一起使用的,相互并不排斥。
当然DQN家族的算法远远不止这些,还有一些其他的DQN算法我没有详细介绍,比如使用一些较复杂的CNN和RNN网络来提高DQN的表达能力,又比如改进探索状态空间的方法等,主要是在DQN的基础上持续优化。
DQN算是深度强化学习的中的主流流派,代表了Value-Based这一大类深度强化学习算法。但是它也有自己的一些问题,就是绝大多数DQN只能处理离散的动作集合,不能处理连续的动作集合。虽然NAF DQN可以解决这个问题,但是方法过于复杂了。而深度强化学习的另一个主流流派Policy-Based而可以较好的解决这个问题,从下一篇我们开始讨论Policy-Based深度强化学习。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
强化学习(十二) Dueling DQN的更多相关文章
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
- (转)SpringMVC学习(十二)——SpringMVC中的拦截器
http://blog.csdn.net/yerenyuan_pku/article/details/72567761 SpringMVC的处理器拦截器类似于Servlet开发中的过滤器Filter, ...
- 强化学习(四)—— DQN系列(DQN, Nature DQN, DDQN, Dueling DQN等)
1 概述 在之前介绍的几种方法,我们对值函数一直有一个很大的限制,那就是它们需要用表格的形式表示.虽说表格形式对于求解有很大的帮助,但它也有自己的缺点.如果问题的状态和行动的空间非常大,使用表格表示难 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十一) Prioritized Replay DQN
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差.今天我 ...
随机推荐
- 老司机告诉你高质量的Java代码是怎么练成的?
一提起程序员,首先想到的一定是"码农",对,我们是高产量的优质"码农",我们拥有超跃常人的逻辑思维以及不走寻常路的分析.判别能力,当然,我们也有良好的编码规范, ...
- D3中的each() 以及svg defs元素 clipPath的使用
each() 方法允许我们定制对选择集中DOM元素的处理行为: selection . each ( func ) 参数 func 是调用者定义的函数,在d3中被称为 访问器/accessor . d ...
- 基于.net的分布式系统限流组件
在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可以让整个系统的运行更加平稳.今天要与大 ...
- 如何提高缓存命中率(Redis)
缓存命中率的介绍 命中:可以直接通过缓存获取到需要的数据. 不命中:无法直接通过缓存获取到想要的数据,需要再次查询数据库或者执行其它的操作.原因可能是由于缓存中根本不存在,或者缓存已经过期. 通常来讲 ...
- linux ubuntukylin和deepin操作系统的比较及改进方向的建议
研发中国的操作系统的需求在我看来是安全,还有就是自主.如果做的好还可以在创新上,使用体验上进行一波超越.现有的所谓的国产操作系统我了解的除了基于安卓的凤凰系统就是基于Linux的像优麒麟和deepin ...
- 搭建Hadoop完全分布式
Centos7搭建hadoop完全分布式 虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基 ...
- mysql left join 左连接查询关联n多张表
left join 左连接即以左表为基准,显示坐标所有的行,右表与左表关联的数据会显示,不关联的则不显示.关键字为left join on. **基本用法如下: select table a left ...
- OAuth 2 开发人员指南(Spring security oauth2)
https://github.com/spring-projects/spring-security-oauth/blob/master/docs/oauth2.md 入门 这是支持OAuth2.0的 ...
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- 你不知道的JavaScript--Item20 作用域与作用域链(scope chain)
作用域是JavaScript最重要的概念之一,想要学好JavaScript就需要理解JavaScript作用域和作用域链的工作原理.今天这篇文章对JavaScript作用域和作用域链作简单的介绍,希望 ...