文本离散表示(一):词袋模型(bag of words)
一、文本表示
文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。文本表示是自然语言处理的开始环节。
文本表示按照细粒度划分,一般可分为字级别、词语级别和句子级别的文本表示。字级别(char level)的如把“邓紫棋实在太可爱了,我想养一只”这句话拆成一个个的字:{邓,紫,棋,实,在,太,可,爱,了,我,想,养,一,只},然后把每个字用一个向量表示,那么这句话就转化为了由14个向量组成的矩阵。
文本表示分为离散表示和分布式表示。离散表示的代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。分布式表示也叫做词嵌入(word embedding),经典模型是word2vec,还包括后来的Glove、ELMO、GPT和最近很火的BERT。
这篇文章介绍一下文本的离散表示。
二、词袋模型
假如现在有1000篇新闻文档,把这些文档拆成一个个的字,去重后得到3000个字,然后把这3000个字作为字典,进行文本表示的模型,叫做词袋模型。这种模型的特点是字典中的字没有特定的顺序,句子的总体结构也被舍弃了。下面分别介绍词袋模型中的one-hot、TF-IDF和n-gram文本表示方法。
(一)one-hot
看一个简单的例子。有两句话“邓紫棋太可爱了,我爱邓紫棋”,“我要看邓紫棋的演唱会”,把这两句话拆成一个个的字,整理得到14个不重复的字,这14个字决定了在文本表示时向量的长度为14。
下面这个表格的第一行是这两句话构成的一个词袋(或者说字典),有14个字。要对两句话进行数值表示,那么先构造一个2×14的零矩阵,然后找到第一句话中每个字在字典中出现的位置,把该位置的0替换为1,第二句话也这样处理。只管字出现了没有(出现了就填入1,不然就是0),而不管这个字在句子中出现了几次。
下面表格中的二、三行就是这两句话的one-hot表示。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
第一个问题是数据稀疏和维度灾难。数据稀疏也就是向量的大部分元素为0,如果词袋中的字词达数百万个,那么由每篇文档转换成的向量的维度是数百万维,由于每篇文档去重后字数较少,因此向量中大部分的元素是0。而且对数百万维的向量进行计算是一件比较蛋疼的事。
但是这样进行文本表示有几个问题。可见,尽管两个句子的长度不一样,但是one-hot编码后长度都一样了,方便进行矩阵运算。
第二个问题是没有考虑句中字的顺序性,假定字之间相互独立。这意味着意思不同的句子可能得到一样的向量。比如“我太可爱了,邓紫棋爱我”,“邓紫棋要看我的演唱会”,得到的one-hot编码和上面两句话的是一样的。
第三个问题是没有考虑字的相对重要性。这种表示只管字出现没有,而不管出现的频率,但显然一个字出现的次数越多,一般而言越重要(除了一些没有实际意义的停用词)。
接下来用TF-IDF来解决字的相对重要性问题。
(二)TF-IDF
TF-IDF用来评估字词对于文档集合中某一篇文档的重要程度。字词的重要性与它在某篇文档中出现的次数成正比,与它在所有文档中出现的次数成反比。TF-IDF的计算公式为:
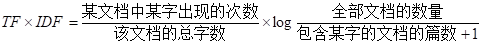
下面一步步来理解。
1 TF——词频
TF(term frequency),即词频,用来衡量字在一篇文档中的重要性,计算公式为:

首先统计字典中每个字在句子中出现的频率:
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
2 |
2 |
2 |
1 |
1 |
2 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
为了防止数值过大,将其归一化,其中下表的二、三行构成的就是TF值矩阵。可以看到,第一句话中“邓、紫、棋、爱”这4个字对应的值更大,在第一句中更重要。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
0.14 |
0.14 |
0.14 |
0.07 |
0.07 |
0.14 |
0.07 |
0.07 |
0 |
0 |
0 |
0 |
0 |
0 |
|
0.07 |
0.07 |
0.07 |
0 |
0 |
0 |
0 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
2 IDF——逆文档频率
IDF((inverse document frequency),叫做逆文档频率,衡量某个字在所有文档集合中的常见程度。当包含某个字的文档的篇数越多时,这个字也就烂大街了,重要性越低。计算公式为:

计算出来的IDF矩阵如下表。值为负或0,因为这个例子比较极端,只有两句话,所以得到了这个极端的结果。“邓、紫、棋、我”这四个字由于在两句话中都出现了,所以得到的IDF值较小。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
-0.41 |
-0.41 |
-0.41 |
0 |
0 |
0 |
0 |
-0.41 |
0 |
0 |
0 |
0 |
0 |
0 |
最后得到TF-IDF = TF × IDF,这里就不再计算了。
TF-IDF的思想比较简单,但是却非常实用。然而这种方法还是存在着数据稀疏的问题,也没有考虑字的前后信息。
(三)n-gram
上面词袋模型的两种表示方法假设字与字之间是相互独立的,没有考虑它们之间的顺序。于是引入n-gram(n元语法)的概念。n-gram是从一个句子中提取n个连续的字的集合,可以获取到字的前后信息。一般2-gram或者3-gram比较常见。
比如“邓紫棋太可爱了,我爱邓紫棋”,“我要看邓紫棋的演唱会”这两个句子,分解为2-gram词汇表:
{邓,邓紫,紫,紫棋,棋,棋太,太,太可,可,可爱,爱,爱了,了,了我,我,我爱,爱邓,我要,要,要看,看邓,棋的,的,的演,演,演唱,唱会,会}
于是原来只有14个字的1-gram字典(就是一个字一个字进行划分的方法)就成了28个元素的2-gram词汇表,词表的维度增加了一倍。
结合one-hot,对两个句子进行编码得到:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0]
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1]
也可以结合TF-IDF来得到文本表示,这里不再计算。
这种表示方法的好处是可以获取更丰富的特征,提取字的前后信息,考虑了字之间的顺序性。
但是问题也是显而易见的,这种方法没有解决数据稀疏和词表维度过高的问题,而且随着n的增大,词表维度会变得更高。
三、总结
文本的离散表示存在着数据稀疏、向量维度过高、字词之间的关系无法度量的问题,适用于浅层的机器学习模型,不适用于深度学习模型。
后续我会再写两篇文章,分析如何用代码实现文本的one-hot编码和TF-IDF编码。
参考资料:
1、《Python深度学习》
2、https://www.cnblogs.com/lianyingteng/p/7755545.html
3、https://www.jianshu.com/p/7298deddca21
4、https://flashgene.com/archives/9201.html
文本离散表示(一):词袋模型(bag of words)的更多相关文章
- 机器学习入门-文本数据-构造Ngram词袋模型 1.CountVectorizer(ngram_range) 构建Ngram词袋模型
函数说明: 1 CountVectorizer(ngram_range=(2, 2)) 进行字符串的前后组合,构造出新的词袋标签 参数说明:ngram_range=(2, 2) 表示选用2个词进行前后 ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- 机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
TF-idf模型:TF表示的是词频:即这个词在一篇文档中出现的频率 idf表示的是逆文档频率, 即log(文档的个数/1+出现该词的文档个数) 可以看出出现该词的文档个数越小,表示这个词越稀有,在这 ...
- 【sklearn文本特征提取】词袋模型/稀疏表示/停用词/TF-IDF模型
1. 词袋模型 (Bag of Words, BOW) 文本分析是机器学习算法的一个主要应用领域.然而,原始数据的这些符号序列不能直接提供给算法进行训练,因为大多数算法期望的是固定大小的数字特征向量, ...
- 文本向量化及词袋模型 - NLP学习(3-1)
分词(Tokenization) - NLP学习(1) N-grams模型.停顿词(stopwords)和标准化处理 - NLP学习(2) 之前我们都了解了如何对文本进行处理:(1)如用NLTK文 ...
- 【CV知识学习】【转】beyond Bags of features for rec scenen categories。基于词袋模型改进的自然场景识别方法
原博文地址:http://www.cnblogs.com/nobadfish/articles/5244637.html 原论文名叫Byeond bags of features:Spatial Py ...
- 机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)
假设有一段文本:"I have a cat, his name is Huzihu. Huzihu is really cute and friendly. We are good frie ...
- 文本特征提取---词袋模型,TF-IDF模型,N-gram模型(Text Feature Extraction Bag of Words TF-IDF N-gram )
假设有一段文本:"I have a cat, his name is Huzihu. Huzihu is really cute and friendly. We are good frie ...
- 词袋模型(BOW, bag of words)
词集模型:单词构成的集合,每个单词只出现一次. 词袋模型:把每一个单词都进行统计,同时计算每个单词出现的次数. 在train_x中,总共有6篇文档,每一行代表一个样本即一篇文档.我们的目标是将trai ...
随机推荐
- C语言实现输出一组数字中的所有奇数
/*第二题*/ #include<stdio.h> //输入186732468 //输出173 //输入12345677 //输出13577 main(){ ;//输入的数字,数字的长度 ...
- Java Spring Boot 上传文件和预览文件地址解析
@RequestMapping(value ="/upload",method = RequestMethod.POST) @Permission(isAjax=false) pu ...
- memset库函数
头文件:#include <string.h> 定义函数:void * memset(void *s, int c, size_t n); 函数说明:memset()会将参数s 所 ...
- Flask信号和wtforms
一.信号 1.1.所有内置信号 request_started = _signals.signal('request-started') # 请求到来前执行 request_finished = _s ...
- js算法初窥01(排序算法01-冒泡、选择、插入)
排序,我想大家一定经历过或者正在经历着.或许你不懂算法,对排序算法一无所知,但是你一定用过一些第三方库的api来一键排序,那么,在你享受便捷的同时,你是否想过它的底层是如何实现的?这样的算法实现方式是 ...
- 什么是web service ?
一.序言 大家或多或少都听过WebService(Web服务),有一段时间很多计算机期刊.书籍和网站都大肆的提及和宣传WebService技术,其中不乏很多吹嘘和做广告的成分.但是不得不承认的是Web ...
- QTP自动化测试流程
1)准备TestCase - 在进行自动化之前,将测试内容进行文档化,不建议直接录制脚本 - 在录制脚本之前设计好脚本,便于录制过程的流畅 - 由于测试用例设 ...
- Python接口测试之对MySQL/unittest框架/Requests 的操作
单元测试支持测试自动化. 共享的安装程序和关闭代码测试. 聚合成集合,测试和报告框架从测试的独立性.单元测试模块提供可以很容易地支持这些素质的一组测试的类.关于unittest 测试框架建议可以到官方 ...
- 使用libpcap过滤arp
上一篇博客简单讲述了libpcap的工作流程及简单使用,今天我们需要做的是继续使用libpcap抓取我们感兴趣的流量,并进行简单的解析: 测试环境是centos 7 下面贴一张arp帧结构图: 下面我 ...
- mysql 创建用户
以管理员方式打开cmd命令提示符进入MySql的Bin目录下 一.以管理员身份登录mysql 密码不隐藏的登录方式:mysql -u root -p 123456 密码隐藏的登录方式:mysql -u ...