ID3算法(决策树)
一,预备知识:
- 信息量:
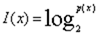
- 单个类别的信息熵:
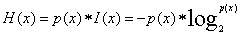
- 条件信息量:
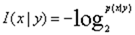
- 单个类别的条件熵:
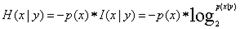
- 信息增益:
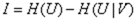
- 信息熵:
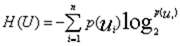
- 条件熵:
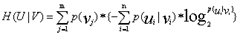 (
(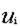 表示分类的类,
表示分类的类,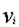 表示属性V的取值,m为属性V的取值个数,n为分类的个数)
表示属性V的取值,m为属性V的取值个数,n为分类的个数)
二.算法流程:

实质:递归的先根建树,结束条件(当前子集类别一致),建树量化方法(信息增益)
三.示例代码:
package com.mechinelearn.id3; import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter; public class ID3 {
private ArrayList<String> attribute = new ArrayList<String>(); // 存储属性的名称
private ArrayList<ArrayList<String>> attributevalue = new ArrayList<ArrayList<String>>(); // 存储每个属性的取值
private ArrayList<String[]> data = new ArrayList<String[]>();; // 原始数据
int decatt; // 决策变量在属性集中的索引
public static final String patternString = "@attribute(.*)[{](.*?)[}]"; Document xmldoc;
Element root; public ID3() {
xmldoc = DocumentHelper.createDocument();
root = xmldoc.addElement("root");
root.addElement("DecisionTree").addAttribute("value", "null");
} public static void main(String[] args) {
ID3 inst = new ID3();
inst.readARFF(new File("data.txt"));
inst.setDec("play");
LinkedList<Integer> ll = new LinkedList<Integer>();
for (int i = 0; i < inst.attribute.size(); i++) {
if (i != inst.decatt)
ll.add(i);
}
ArrayList<Integer> al = new ArrayList<Integer>();
for (int i = 0; i < inst.data.size(); i++) {
al.add(i);
}
inst.buildDT("DecisionTree", "null", al, ll);
inst.writeXML("dt.xml");
return;
} // 读取arff文件,给attribute、attributevalue、data赋值
public void readARFF(File file) {
try {
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
String line;
Pattern pattern = Pattern.compile(patternString);
while ((line = br.readLine()) != null) {
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
attribute.add(matcher.group(1).trim());// 增加属性
String[] values = matcher.group(2).split(",");
ArrayList<String> al = new ArrayList<String>(values.length);
for (String value : values) {
al.add(value.trim());
}
attributevalue.add(al);// 每个属性对应的属性值
} else if (line.startsWith("@data")) {
while ((line = br.readLine()) != null) {
if (line == "")
continue;
String[] row = line.split(",");
data.add(row);// 增加训练数据
}
} else {
continue;
}
}
br.close();
} catch (IOException e1) {
e1.printStackTrace();
}
} // 设置决策变量
public void setDec(String name) {
int n = attribute.indexOf(name);
if (n < 0 || n >= attribute.size()) {
System.err.println("决策变量指定错误。");
System.exit(2);
}
decatt = n;
} // 计算每一个属性的属性值对应的的熵
public double getEntropy(int[] arr) {
double entropy = 0.0;
int sum = 0;
for (int i = 0; i < arr.length; i++) {
entropy -= arr[i] * Math.log(arr[i] + Double.MIN_VALUE)
/ Math.log(2);
sum += arr[i];
}
entropy += sum * Math.log(sum + Double.MIN_VALUE) / Math.log(2);
entropy /= sum;
return entropy;
} // 给一个样本数组及样本的算术和,计算它的熵
public double getEntropy(int[] arr, int sum) {
double entropy = 0.0;
for (int i = 0; i < arr.length; i++) {
entropy -= arr[i] * Math.log(arr[i] + Double.MIN_VALUE)
/ Math.log(2);
}
entropy += sum * Math.log(sum + Double.MIN_VALUE) / Math.log(2);
entropy /= sum;
return entropy;
} //是否到达叶子节点
public boolean infoPure(ArrayList<Integer> subset) {
String value = data.get(subset.get(0))[decatt];
for (int i = 1; i < subset.size(); i++) {
String next = data.get(subset.get(i))[decatt];
// equals表示对象内容相同,==表示两个对象指向的是同一片内存
if (!value.equals(next))
return false;
}
return true;
} // 给定原始数据的子集(subset中存储行号),当以第index个属性为节点时计算它的信息熵
public double calNodeEntropy(ArrayList<Integer> subset, int index) {
int sum = subset.size();
double entropy = 0.0;
int[][] info = new int[attributevalue.get(index).size()][];//属性值个数为行
for (int i = 0; i < info.length; i++)
info[i] = new int[attributevalue.get(decatt).size()];//分类属性值个数为列
int[] count = new int[attributevalue.get(index).size()];//每个属性值在整个样本中出现的概率
for (int i = 0; i < sum; i++) {
int n = subset.get(i);
String nodevalue = data.get(n)[index];
int nodeind = attributevalue.get(index).indexOf(nodevalue);
count[nodeind]++;
String decvalue = data.get(n)[decatt];
int decind = attributevalue.get(decatt).indexOf(decvalue);
info[nodeind][decind]++;
}
for (int i = 0; i < info.length; i++) {
entropy += getEntropy(info[i]) * count[i] / sum;// 计算条件熵
}
return entropy;
} // 构建决策树(递归建树)
public void buildDT(String name, String value, ArrayList<Integer> subset,
LinkedList<Integer> selatt) {
Element ele = null;
@SuppressWarnings("unchecked")
List<Element> list = root.selectNodes("//" + name);
Iterator<Element> iter = list.iterator();
while (iter.hasNext()) {
ele = iter.next();
if (ele.attributeValue("value").equals(value))
break;
}
if (infoPure(subset)) {// 深度优先建树是否结束
ele.setText(data.get(subset.get(0))[decatt]);// 设置决策
return;
}
int minIndex = -1;
double minEntropy = Double.MAX_VALUE;
for (int i = 0; i < selatt.size(); i++) {
if (i == decatt)
continue;
double entropy = calNodeEntropy(subset, selatt.get(i));
if (entropy < minEntropy) {
minIndex = selatt.get(i);
minEntropy = entropy;
}
}
String nodeName = attribute.get(minIndex);
selatt.remove(new Integer(minIndex));
ArrayList<String> attvalues = attributevalue.get(minIndex);
for (String val : attvalues) {
ele.addElement(nodeName).addAttribute("value", val);
ArrayList<Integer> al = new ArrayList<Integer>();
for (int i = 0; i < subset.size(); i++) {
if (data.get(subset.get(i))[minIndex].equals(val)) {
al.add(subset.get(i));
}
}
buildDT(nodeName, val, al, selatt);// 递归建树
}
} // 把xml写入文件
public void writeXML(String filename) {
try {
File file = new File(filename);
if (!file.exists())
file.createNewFile();
FileWriter fw = new FileWriter(file);
OutputFormat format = OutputFormat.createPrettyPrint(); // 美化格式
XMLWriter output = new XMLWriter(fw, format);
output.write(xmldoc);
output.close();
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
}
ID3算法(决策树)的更多相关文章
- ID3算法 决策树的生成(2)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
- ID3算法 决策树的生成(1)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
- ID3算法 决策树 C++实现
人工智能课的实验. 数据结构:多叉树 这个实验我写了好久,开始的时候从数据的读入和表示入手,写到递归建树的部分时遇到了瓶颈,更新样例集和属性集的办法过于繁琐: 于是参考网上的代码后重新写,建立决策树类 ...
- Python 实现基于信息熵的 ID3 算法决策树模型
版本说明 Python version: 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 11:21:07) [MSC v.1900 32 bit (Int ...
- 决策树笔记:使用ID3算法
决策树笔记:使用ID3算法 决策树笔记:使用ID3算法 机器学习 先说一个偶然的想法:同样的一堆节点构成的二叉树,平衡树和非平衡树的区别,可以认为是"是否按照重要度逐渐降低"的顺序 ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
- 02-21 决策树ID3算法
目录 决策树ID3算法 一.决策树ID3算法学习目标 二.决策树引入 三.决策树ID3算法详解 3.1 if-else和决策树 3.2 信息增益 四.决策树ID3算法流程 4.1 输入 4.2 输出 ...
- 决策树ID3算法的java实现(基本试用所有的ID3)
已知:流感训练数据集,预定义两个类别: 求:用ID3算法建立流感的属性描述决策树 流感训练数据集 No. 头痛 肌肉痛 体温 患流感 1 是(1) 是(1) 正常(0) 否(0) 2 是(1) 是(1 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树 -- ID3算法小结
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代),是一个由Ross Quinlan发明的用于决策树的算法:简单理论是越是小型的决策树越优于大的决策树. 算法归 ...
随机推荐
- [转] GPS坐标转换经纬度及换算方法
GPS坐标和经纬度的算法和概率不太一样,但是我们可能会将他们互通起来用,下面先贴上我做的转换工具:http://map.yanue.net/gps.html.里面实现了gps到谷歌地图百度地图经纬度的 ...
- ERROR<53761> - Plugins - conn=-1 op=-1 msgId=-1 - Connection Bind through PTA failed (91). Retrying...
LDAP6.3在DSCC控制台启动实例完成,但是操作状态显示“意外错误”,查看日志如下: 04/May/2016:21:10:39 +0800] - Sun-Java(tm)-System-Direc ...
- Java多线程——线程池
系统启动一个新线程的成本是比较高的,因为它涉及到与操作系统的交互.在这种情况下,使用线程池可以很好的提供性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池. 与数据库连接池类似 ...
- css07家用电器分类
1.创建一个html页面 <!DOCTYPE html> <html> <head lang="en"> <meta charset=&q ...
- spring-data-redis问题总结
如何判断一个字符串是否是合法的long类型? 参考文档如下: http://www.oschina.net/question/59889_45179 spring-data-redis http:// ...
- Hyper-V虚拟机和主机的网络配置
Hyper-V虚拟机和主机的网络配置 方式1.共享式 这种方式是将Hyper-V内部的虚拟网络与外部网络共享.使得内部是一个私有的网络.属于NAT的类型.(不知道这么说对不对) 优点: 相对来说属于私 ...
- 关于ASP.Net 4.0的ClientID
我们知道因为在原来的ASP.NET应用程序中使用服务端控件在生成ClientID的时,是很难控制的,特别是在嵌套的控件的时候,比如在多个嵌套Repeater中要控制某一个控件生成的html的ID属性, ...
- exp导出出现:ORA-00904: "POLTYP": invalid identifier
相关文章: <exp导出出现:ORA-00904: : invalid identifier>:http://blog.itpub.net/23135684/viewspace-13 ...
- PHP E-mail
PHP E-mail 注入 首先,请看上一章中的 PHP 代码: <html><body> <?phpif (isset($_REQUEST['email']))//if ...
- PyQt5+python3的FindDialog
import sys from PyQt5.QtWidgets import * from PyQt5.QtCore import Qt, pyqtSignal class FindDialog(QD ...