XDocument读取xml的所有元素以及XPath语法
原文 http://www.cnblogs.com/xxyishutong/p/3326375.html
<?xml version="1.0" encoding="utf-8" ?>
<bookstore> <book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book> <book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book> <book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book> <book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book> </bookstore>

以上是BookStore.xml文件
接着开始处理
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.Elements();//获得根节点下的元素集合
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
DiGuiNode(item); //递归获得此元素下的子元素
}
private static void DiGuiNode(XElement xroot)
{
if (xroot!=null)
{
foreach (var item in xroot.Elements())
{
Console.WriteLine(item.Name);//获得元素名
Console.WriteLine(item.Value);//获得元素的基本值
DiGuiNode(item);
}
}
}
运行结果: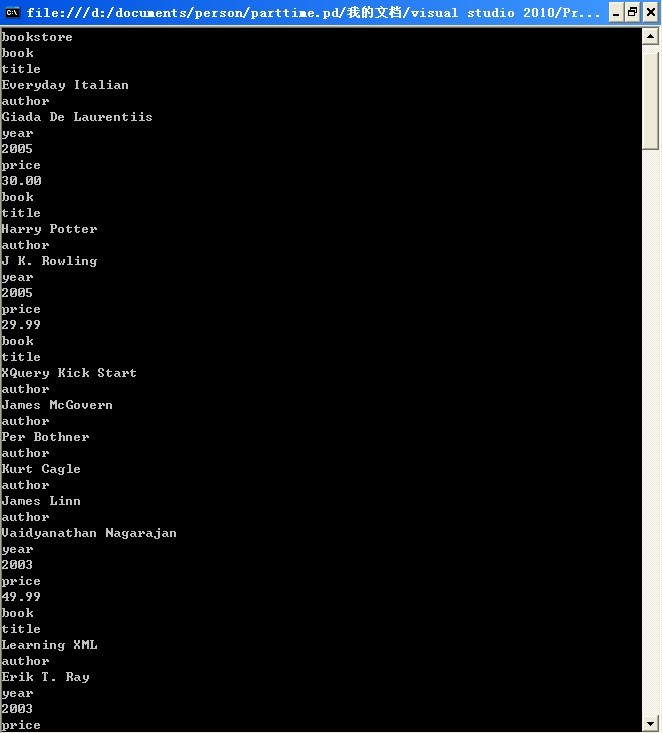
2.XPath语法:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有直接子nodename节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
2.1
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.XPathSelectElements("book");//找根节点的直接book子节点
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
}
运行结果: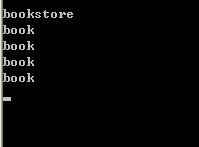
2.2 假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
IEnumerable<XElement> elements = xroot.XPathSelectElements("/bookstore/book/price");//假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
}
运行结果:
2.3 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.XPathSelectElements("//author");
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
}
运行结果:
2.4 .表示选取当前节点。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.XPathSelectElements(".");//.表示当前节点,此处表示根节点
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
}
运行结果: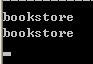
2.5 ..表示选取当前节点的父节点。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.XPathSelectElements("book");//找根节点的直接book子节点
foreach (XElement item in elements)
{
XElement element = item.XPathSelectElement("..");//..表示选取当前节点的父节点,此处获得的是item表示book节点,所以element就表示bookstore节点
Console.WriteLine(element.Name);
}
运行结果:
2.6 @表示选取带此属性的元素
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件
XElement xroot = xdoc.Root;//获取根节点
Console.WriteLine(xroot.Name);//输出根节点的名字
IEnumerable<XElement> elements = xroot.XPathSelectElements("//book[@category='WEB']");//表示选择出含有值为WEB的category属性的book元素
foreach (XElement item in elements)
{
Console.WriteLine(item.Name);
}
运行结果:
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
以上表格信息摘自http://www.w3school.com.cn/xpath/xpath_syntax.asp
XDocument读取xml的所有元素以及XPath语法的更多相关文章
- Xpath语法与lxml库
1. Xpath 1 )什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 2) X ...
- 转过来的Xpath语法
XPath 是XML的查询语言,和SQL的角色很类似.以下面XML为例,介绍XPath 的语法. <?xml version="1.0" encoding="I ...
- Dom4j使用Xpath语法读取xml节点
我们可以使用Xpath的语法来轻易的读取xml的某个节点[类似于jQuery的选择器]: 使用Xpath语法需要添加新的jaxen-1.1-beta-7.rar 这个jar包 dom4j完整jar包我 ...
- 【XML】-- C#读取XML中元素和属性的值
Xml是扩展标记语言的简写,是一种开发的文本格式. 啰嗦几句儿:老师布置的一个小作业却让我的脑细胞死了一堆,难的不是代码,是n多嵌套的if.foreach,做完这个,我使劲儿想:我一女孩,没有更多女孩 ...
- sax xpath读取xml字符串
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOExceptio ...
- 利用XPath读取Xml文件
之所以要引入XPath的概念,目的就是为了在匹配XML文档结构树时能够准确地找到某一个节点元素.可以把XPath比作文件管理路径:通过文件管理路 径,可以按照一定的规则查找到所需要的文件:同样,依据X ...
- java中的xpath,读取xml文档。
1,入门 XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力.起初 X ...
- JAVA读取XML文件并解析获取元素、属性值、子元素信息
JAVA读取XML文件并解析获取元素.属性值.子元素信息 关键字 XML读取 InputStream DocumentBuilderFactory Element Node 前言 最 ...
- C#中常用的读取xml的几种方法(转)
本文完全来源于http://blog.csdn.net/tiemufeng1122/article/details/6723764,仅作个人学习之用. XML文件是一种常用的文件格式,例如WinFor ...
随机推荐
- jQuery 动态绑定的点击事件
$(function () { , $_div = $('#test'); $('input[name=addbtn]').on('click', function () { $_div.append ...
- HTML5之Viewport详解
做移动Web开发也有一年多的时间了,虽然手机上浏览器对于PC上来说很友好了,但是手机各种设备的显示尺寸分辨率大小不一也要花大心思兼容它们. 关于HTML5中Viewport的文章Google,百度一搜 ...
- 根据群ID和用户Id查询 + string QueryQunByUserIdAndQunId(int userId, int qunId) V1.0
#region 根据群ID和用户Id查询 + string QueryQunByUserIdAndQunId(int userId, int qunId) V1.0 /// <summary ...
- python中实现多线程的几种方式
python实现多线程的方式大概有 1.threading 2._thread #!/usr/bin/python #!coding:utf-8 import threading def action ...
- MYSQL 查询缓存
查询缓存: 是指对select 语句的结果进行缓存,当下一次运行同样的select语句时,就可以直接返回数据,跳过解析,执行,优化阶段. 1.查询缓存会跟踪查询涉及的表,如果表发生变化,相关的缓存都会 ...
- 用做网页开发经历了三个阶段(附长篇讨论) good
用做网页开发经历了三个阶段:第一阶:傻干阶段使用Intraweb,傻瓜型,无需知道javascript,html,css,会pascal就可以了. 第二阶:困惑阶段使用Intraweb,有很多限制,比 ...
- delphi 对TThread扩充TSimpleThread
对线程的使用,是每个开发者都应该熟练掌握的,也是进阶的重要一环. 可以这样说,没有线程,连界面假死的问题都解决不了,就更别谈并行处理来提高效率了. 本例对线程进行改进,打造一个基础的线程,以后线程应用 ...
- perl 一个简单的面向对象的例子
<pre name="code" class="python">[root@wx03 wx]# cat x1.pm package x1; use ...
- nexus 7 2013 驱动安装及root
驱动安装 Nexus 7 2013连接上电脑后,设备管理器显示新设备 nexus 7 待安装驱动(其实是MTP设备待安装驱动).去谷歌网站下载最新的USB驱动,version 8.0 的.与以前的版本 ...
- Attempt to call getDuration without a valid mediaplayer
最近在做一个播放器的小例子,中途遇到 了这个错: Attempt to call getDuration without a valid mediaplayer 解决参考方案如下: 一是如果media ...