李航《统计学习方法》CH01
CH01 统计学方法概论
前言
章节目录
- 统计学习
- 监督学习
- 基本概念
- 问题的形式化
- 统计学习三要素
- 模型
- 策略
- 算法
- 模型评估与模型选择
- 训练误差与测试误差
- 过拟合与模型选择
- 正则化与交叉验证
- 正则化
- 交叉验证
- 泛化能力
- 泛化误差
- 泛化误差上界
- 生成模型与判别模型
- 分类问题
- 标注问题
- 回归问题
导读
直接看目录结构,会感觉有点乱,就层级结构来讲感觉并不整齐。
可以看本章概要部分,摘录几点,希望对本章内容编排的理解有帮助:
1. 统计学习三要素对理解统计学习方法起到提纲挈领的作用
2. 本书主要讨论监督学习
3. 分类问题、标注问题和回归问题都是监督学习的重要问题
4. 本书中介绍的统计学习方法包括...。这些方法是主要的分类、标注以及回归方法。他们又可归类为生成方法与判别方法。
本章最后的三个部分,这三个问题可以对比着看,暂时没有概念,略过也可以,回头对各个算法有了感觉回头再看这里。 这三部分怎么对比,三部分都有个图来说明,仔细看下差异,本文后面会对此展开。
关于损失函数,风险函数与目标函数注意体会差异
Losses, Metrics, 在Keras里面划分了两个模块, 解释是Losses是BP过程用到的, 而Metrics实际和损失函数类似, 用来评价模型的性能, 但是不参与反向传播. 从源码也能看到, Metrics里面import了很多Loss算法
1. 实现统计学习方法的步骤
统计学习方法三要素:模型,策略,算法.
1. 得到一个有限的训练数据集合
2. 确定包含所有可能的模型的假设空间, 即学习模型的集合.
3. 确定模型选择的准则, 即学习的策略
4. 实现求解最优模型的算法, 即学习的算法
5. 通过学习方法选择最优的模型
6. 利用学习的最优模型对新数据进行预测或分析.
2. 监督学习
- 输入变量与输出变量均为连续变量的预测问题称为回归问题;
- 输出变量为有限个离散变量的预测问题称为分类问题;
- 输入变量与输出变量均为变量序列的预侧问题称为标注问题
监督学习假设输入与输出的随机变量X和Y遵循联合概率分布P (X,Y)。
3. 统计学习方法三要素
3.1 模型
3.1.1 模型是什么?
在监督学习过程中, 模型就是所要学习的条件概率分布或者决策函数.
注意书中的这部分描述,整理了一下到表格里:
| 假设空间$\cal F$ | 输入空间$\cal X$ | 输出空间$\cal Y$ | 参数空间 | |
|---|---|---|---|---|
| 决策函数 | $\cal F\it ={f | Y = f_{\theta}(X),\theta \in \bf R \it^n}$ | $X$ | $Y$ | 变量 |
| 条件概率分布 | $\cal F\it ={P | P_\theta(Y|X), \theta \in \bf R \it ^n}$ | $X$ | $Y$ | 随机变量 |
书中描述的时候,有提到条件概率分布族,这个留一下,后面CH06有提到确认逻辑斯谛分布属于指数分布族。
3.2 策略
3.3.1损失函数与风险函数
损失函数度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
损失函数(loss function)或代价函数(cost function) 损失函数定义为给定输入$X$的预测值$f(X)$和真实值$Y$之间的非负实值函数, 记作$L(Y,f(X))$
风险函数(risk function)或期望损失(expected loss) 这个和模型的泛化误差的形式是一样的 $R_{exp}(f)=E_p[L(Y, f(X))]=\int_{\mathcal X\times\mathcal Y}L(y,f(x))P(x,y) {\rm d}x{\rm d}y$ 模型$f(X)$关于联合分布$P(X,Y)$的平均意义下的损失(期望损失), 但是因为$P(X,Y)$是未知的, 所以前面的用词是期望, 以及平均意义下的.
这个表示其实就是损失的均值, 反映了对整个数据的预测效果的好坏, $P(x,y)$转换成$\frac {\nu(X=x, Y=y)}{N}$更容易直观理解, 可以参考CH09, 6.2.2节的部分描述来理解, 但是真实的数据N是无穷的.
经验风险(empirical risk)或经验损失(empirical loss) $R_{emp}(f)=\frac{1}{N}\sum^{N}_{i=1}L(y_i,f(x_i))$ 是模型 $f$ 关于训练样本集的平均损失. 根据大数定律, 当样本容量N趋于无穷大时, 经验风险趋于期望风险.
结构风险(structural risk) $R_{srm}(f)=\frac{1}{N} \sum_{i=1}^{N} L(y_i,f(x_i))+\lambda J(f)$, $J(f)$为模型复杂度, $\lambda \geqslant 0$是系数, 用以权衡经验风险和模型复杂度.
3.2.2 常用损失函数
损失函数数值越小,模型就越好
$L(Y,f(X))$
1. 0-1损失函数
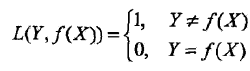
2. 平方损失函数
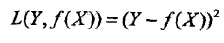
3. 绝对损失函数

4. 对数损失函数或对数似然损失函数
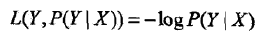
这里$P(Y|X)\leqslant 1$,对应的对数是负值,所以对数损失中包含一个负号,为什么不是绝对值?因为肯定是负的。
3.2.3 ERM与SRM
经验风险最小化(ERM)与结构风险最小化(SRM)
- 极大似然估计是经验风险最小化的一个例子. 当模型是条件概率分布, 损失函数是对数损失函数时, 经验风险最小化等价于极大似然估计.
- 贝叶斯估计中的最大后验概率估计是结构风险最小化的一个例子. 当模型是条件概率分布, 损失函数是对数损失函数, 模型复杂度由模型的先验概率表示时, 结构风险最小化等价于最大后验概率估计.
3.3 算法
这章里面简单提了一下,具体可以参考CH12表格中关于学习算法的描述。
4. 模型选择
当选择的模型复杂度过大(多项式次数增加)时,会发生过拟合现象。
模型选择常用方法:
1. 正则化 模型选择的典型方法是正则化
2. 交叉验证 另一种常用的模型选择方法是交叉验证
基本思想是重复地使用数据,把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择.
- 简单交叉验证:首先随机地将己给数据分为两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在各种条件下(例如,不同的参数个数)训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型.
- S折交叉验证:首先随机地将已给数据切分为S个互不相交的大小相同的子集;然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均侧试误差最小的模型.
- 留一交叉验证:S折交叉验证的特殊情形是S=N,N是给定数据集的容量.
5. 泛化能力
学习方法的泛化能力(generalization ability)是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。
- 现实中采用最多的方法是通过测试误差来评价学习方法的泛化能力
- 统计学习理论试图从理论上对学习方法的泛化能力进行分析
这本书里面讨论的不多,在CH08里面有讨论提升方法的误差分析。
注意泛化误差的定义,书中有说事实上,泛化误差就是所学习到的模型的期望风险
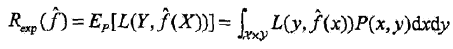
6. 生成模型与判别模型
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach). 所学到的模型分别称为生成模型(geuemtive model)和判别模型(discriminative model).
6.1 生成方法
generative approach
由数据学习联合概率分布 $P(X,Y)$ ,然后求出条件概率分布 $P(Y|X)$ 作为预测的模型,即生成模型
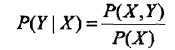
这样的方法之所以称为生成方法,是因为模型表示了给定输入 $X$ 产生输出 $Y$ 的生成关系.典型的生成模型有:朴素贝叶斯法和隐马尔可夫模型。
- 可以还原出联合概率分布$P(X,Y)$
- 收敛速度快, 当样本容量增加时, 学到的模型可以更快收敛到真实模型
- 当存在隐变量时仍可以用
6.2 判别方法
discriminative approach
由数据直接学习决策函数 $f(X)$ 或者条件概率分布 $P(Y|X)$ 作为预测的模型,即判别模型.判别方法关心的是对给定的输入 $X$ ,应该预测什么样的输出 $Y$ .典型的判别模型包括k近邻法、感知机、决策树、逻辑斯谛回归模型、最大嫡模型、支持向量机、提升方法和条件随机场等。
- 直接学习条件概率$P(Y|X)$或者决策函数$f(X)$
- 直接面对预测, 往往学习准确率更高
- 可以对数据进行各种程度的抽象, 定义特征并使用特征, 可以简化学习问题
7. 分类问题、标注问题、回归问题
Classification, Tagging, Regression
- 图1.4和图1.5除了分类系统和标注系统的差异外,没看到其他差异,但实际上这两幅图中对应的输入数据有差异,序列数据的$x_i = (x_i^{(1)},x_i^{(2)},\dots,x_i^{(n)})^T$对应了
- 图1.5和图1.6,回归问题的产出为$Y=\hat f(X)$
李航《统计学习方法》CH01的更多相关文章
- 李航统计学习方法——算法2k近邻法
2.4.1 构造kd树 给定一个二维空间数据集,T={(2,3),(5,4),(9,6)(4,7),(8,1),(7,2)} ,构造的kd树见下图 2.4.2 kd树最近邻搜索算法 三.实现算法 下面 ...
- 李航-统计学习方法-笔记-3:KNN
KNN算法 基本模型:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例.这k个实例的多数属于某个类,就把输入实例分为这个类. KNN没有显式的学习过程. KNN使用的模型 ...
- 李航统计学习方法(第二版)(六):k 近邻算法实现(kd树(kd tree)方法)
1. kd树简介 构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点.在超矩形区域(结点)上选择一个坐标轴和 ...
- 李航统计学习方法(第二版)(五):k 近邻算法简介
1 简介 k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类.k近邻法假设给定一个训练数据集,其中的实例类别已定.分类时,对新的实例,根据其k个最近邻的训练实例的类别,通 ...
- 李航统计学习方法(第二版)(十):决策树CART算法
1 简介 1.1 介绍 1.2 生成步骤 CART树算法由以下两步组成:(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;(2)决策树剪枝:用验证数据集对己生成的树进行剪枝并选择最优子 ...
- Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的<统计学习方法(第二版)>,对AdaBoost算法进行了学习. 在第八章的8.1.3小节中,举了一个具体的算法计算实例.美中不足的是书上只给出了数值解,这里用代码将它实现一 ...
- 统计学习方法学习(四)--KNN及kd树的java实现
K近邻法 1基本概念 K近邻法,是一种基本分类和回归规则.根据已有的训练数据集(含有标签),对于新的实例,根据其最近的k个近邻的类别,通过多数表决的方式进行预测. 2模型相关 2.1 距离的度量方式 ...
- 统计学习方法(李航)朴素贝叶斯python实现
朴素贝叶斯法 首先训练朴素贝叶斯模型,对应算法4.1(1),分别计算先验概率及条件概率,分别存在字典priorP和condP中(初始化函数中定义).其中,计算一个向量各元素频率的操作反复出现,定义为c ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
随机推荐
- 【DOM练习】百度历史搜索栏
HTML: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <t ...
- Lua 哑变量
[1]哑变量 哑变量,又称为虚拟变量.名义变量. 还得理解汉语的博大精深,‘虚拟’.‘名义’.‘哑’等等,都是没有实际意义.所以,哑变量即没有现实意义的变量. 哑变量的应用示例如下: local fi ...
- Flask实战-留言板-使用Faker生成虚拟数据
使用Faker生成虚拟数据 创建虚拟数据是编写Web程序时的常见需求.在简单的场景下,我们可以手动创建一些虚拟数据,但更方便的选择是使用第三方库实现.流行的python虚拟数据生成工具有Mimesis ...
- mysql在Windows下使用mysqldump命令手动备份数据库和自动备份数据库
手动备份: cmd控制台: 先进入mysql所在的bin目录下,如:cd C:\Program Files\MySQL\MySQL Server 5.5\bin mysqldump -u root - ...
- MyPython
目录 Python,那些不可不知的事儿 Python简介 Python环境搭建 从Hello World开始 Python中的数据类型 函数 模块 面向对象 More Python,那些不可不知的事儿 ...
- PHP操作RabbitMQ的类 exchange、queue、route kye、bind
RabbitMQ是常见的消息中间件.也许是还是不够了解的缘故,感觉功能还好吧. 讲到队列,大家脑子里第一印象是下边这样的. P生产者推送消息-->队列-->C消费者取出消息 结构很简单,但 ...
- 《Java程序设计》课程实验要求
目录 <Java程序设计>课程实验要求 注册实验楼账号 实验一 Java开发环境的熟悉 实验二<Java面向对象程序设计> 实验三 <敏捷开发与XP实践> 实验四 ...
- Guitar Por如何演奏刮弦
每当我们听到吉他现场演出的时候,看到吉他手在激烈的刮弦时,都觉得很酷,非常有感染力.刮弦在我们弹吉他或编曲时,会经常用到,虽然时间很短,但会为你加分不少. 那么我们应该如何演奏刮弦呢,我们先用E5和弦 ...
- redux&&createStore
const createStore = (reducer,presetState, enhancer) => { if (typeof presetState === "functio ...
- python数据库多字段插入
# -*- co;ding: utf-8 -*-#企业详细信息写入数据库+征信得分import pymysqlfrom impala.dbapi import connect conn = pymys ...