DFS和BFS
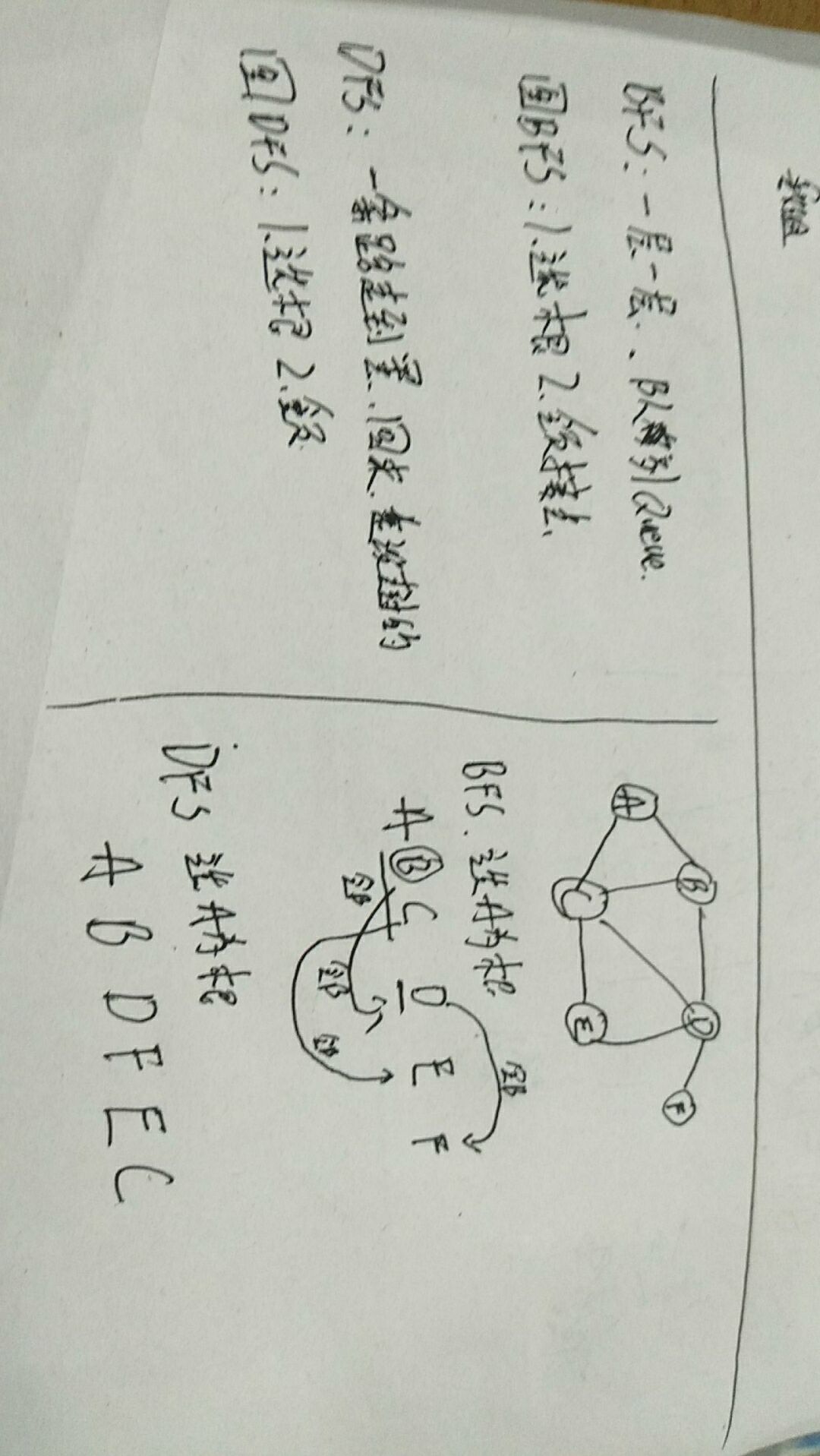
BFS
代码步骤:
1、写出每个点和每个点的邻接点的对应关系
2、方法参数:传一个对应关系和起始点
3、创建一个队列,然后每次都移除第一个,然后把移除的邻接点添加进去,打印取出的第一个,然后循环,一直到队列没有元素
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class BFS {
public static void main(String[] args) {
List list = new ArrayList();//A的邻接点
list.add("B");
list.add("C"); List list2 = new ArrayList();//B的邻接点
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();//C的邻接点
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();//D的邻接点
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();//E的邻接点
list5.add("C");
list5.add("D"); List list6 = new ArrayList();//F的邻接点
list6.add("D"); Map<String,List> map = new HashMap<>();//使得邻接点和该值对应上
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); BFS(map,"E"); }
/**
* 利用对列的方式
* @param map 字典
* @param s 根节点
*/
public static void BFS(Map map,String s){
List<String> queue = new ArrayList();//队列
queue.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s);
while(queue.size()>0) {//队列没有元素位置
String vertex = (String) queue.remove(0);//每次取队列第一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点
for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
queue.add(w);
seen.add(w);
}
}
System.out.println(vertex);
}
} }
BFS的最短路径
就是添加一个键值对,键就是该字母,值就是他的前一个字母
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class BFS最短路径 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("B");
list.add("C"); List list2 = new ArrayList();
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();
list5.add("C");
list5.add("D"); List list6 = new ArrayList();
list6.add("D"); Map<String,List> map = new HashMap<>();
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); BFS(map,"A"); }
/**
* 利用对列的方式
* @param map
* @param s
*/
public static void BFS(Map map,String s){
List<String> queue = new ArrayList();//队列
queue.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s); Map parent = new HashMap();
parent.put(s, null);
while(queue.size()>0) {
String vertex = (String) queue.remove(0);//那队列第一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点 for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
queue.add(w);
seen.add(w);
parent.put(w, vertex);//添加字符前一个字符
}
}
//System.out.println(vertex); }
//输出最短路径
String end = "E";
while(end!=null) {
System.out.println(end);
end = (String) parent.get(end);
} } }
DFS
就是把BFS的队列换成栈,根本区别就是变成移除最后一个了
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class DFS {
public static void main(String[] args) {
List list = new ArrayList();
list.add("B");
list.add("C"); List list2 = new ArrayList();
list2.add("A");
list2.add("C");
list2.add("D"); List list3 = new ArrayList();
list3.add("A");
list3.add("B");
list3.add("D");
list3.add("E"); List list4 = new ArrayList();
list4.add("B");
list4.add("C");
list4.add("E");
list4.add("F"); List list5 = new ArrayList();
list5.add("C");
list5.add("D"); List list6 = new ArrayList();
list6.add("D"); Map<String,List> map = new HashMap<>();
map.put("A", list);
map.put("B", list2);
map.put("C", list3);
map.put("D", list4);
map.put("E", list5);
map.put("F", list6); DFS(map,"E"); }
/**
* 利用对列的方式
* @param map
* @param s
*/
public static void DFS(Map map,String s){
List<String> stack = new ArrayList();//栈
stack.add(s);
ArrayList seen = new ArrayList();//用来放已经访问过的元素
seen.add(s);
while(stack.size()>0) {
String vertex = (String) stack.remove(stack.size()-1);//拿队列最后一个元素
List<String> nodes = (List) map.get(vertex);//把vertex所有临近点
for(String w:nodes) {//遍历所有邻接点,没有包含的进入队列
if(!seen.contains(w)) {
stack.add(w);
seen.add(w);
}
}
System.out.println(vertex);
}
} }
DFS和BFS的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- dfs和bfs的区别
详见转载博客:https://www.cnblogs.com/wzl19981116/p/9397203.html 1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索 ...
- 邻接矩阵实现图的存储,DFS,BFS遍历
图的遍历一般由两者方式:深度优先搜索(DFS),广度优先搜索(BFS),深度优先就是先访问完最深层次的数据元素,而BFS其实就是层次遍历,每一层每一层的遍历. 1.深度优先搜索(DFS) 我一贯习惯有 ...
- 判断图连通的三种方法——dfs,bfs,并查集
Description 如果无向图G每对顶点v和w都有从v到w的路径,那么称无向图G是连通的.现在给定一张无向图,判断它是否是连通的. Input 第一行有2个整数n和m(0 < n,m < ...
随机推荐
- pytest--fixture参数化的实现方式和执行顺序
之前看到fixture函数可以通过添加,params参数来实现参数化,后续看到了悠悠 的博客,可以通过@pytest.mark.parametrize来实现,现在做一个总结 实现方式一 通过param ...
- 运维案例 | Exchange2010数据库损坏的紧急修复思路
关注嘉为科技,获取运维新知 Exchange后端数据库故障,一般都会是比较严重的紧急故障,因为这会直接影响到大面积用户的正常使用,而且涉及到用户数据.一旦遇到这种级别的故障,管理员往往都是在非常紧 ...
- Failed to find configured root that contains
这个主要问题是在android系统下7.0 拍照时,Android提供FileProvider类来供应用之间共享数据. 出现这个问题多为xml文件 path 类型和代码中调用的类型不同导致的 以下为多 ...
- 8.3 GOF设计模式二: 适配器模式 Adapter
GOF设计模式二: 适配器模式 Adapter 为中国市场生产的电器,到了美国,需要有一个转接器才能使用墙上的插座,这个转接 器的功能.原理?复习单实例模式 SingleTon的三个关键点 ...
- Golang安装与命令
1. 安装 Windows - https://golang.org/dl/ 下载msi安装包,点击安装即可.安装后cmd运行go version弹出版本号即安装成功. 2. 命令行 生成exe文件 ...
- 微信小程序如何使用iconfont阿里巴巴图标库?
步骤: 1.如图先下载: 2.找到iconfont.css改为iconfont.css 3.修改iconfont.wxss文件的内容,如图复制内容至其文件 4.替换到文件页面当中 5.去页面中引入i ...
- [cf contest697] D - Puzzles
[cf contest697] D - Puzzles time limit per test 1 second memory limit per test 256 megabytes input s ...
- shogun docker image 中import shogun error
- django自定义模板标签
# 创建自定义模板标签目录 django_project_name app_name templatetags (创建Python Packge,注意一定要用templatetags这个名字) my_ ...
- webbench安装使用
简介 运行在linux上的一个性能测试工具 官网地址:http://home.tiscali.cz/~cz210552/webbench.html 如果不能打开的话,也可以直接到网盘下载:http:/ ...