Hadoop 学生平均成绩
1.实例描述
通过一个计算学生平均成绩的例子来讲解开发MapReduce程序的流程。输入文件都是纯文本文件,输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。输出文件每行包含学生的姓名和平均成绩。下面给出样本输入文件,以及跑MapReduce程序过后的输出文件。代码亲测可用。注意:本人的开发环境是在Ubuntu+Eclipse下跑的。
1)math
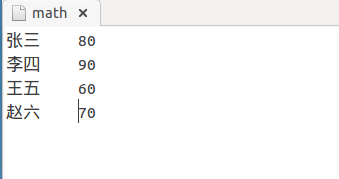
2)china
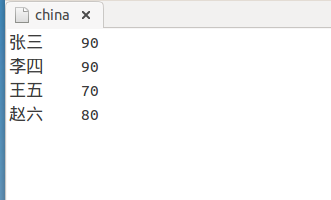
3)english
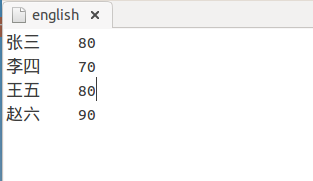
4)输出文件
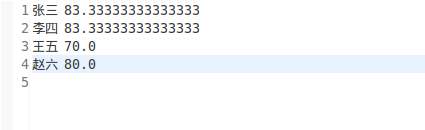
2.程序代码
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class AvgScore { public static class Map extends Mapper<Object, Text, Text, DoubleWritable>{
private static Text name = new Text();
private static DoubleWritable score = new DoubleWritable();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
// super.map(key, value, context);
String[] splits = value.toString().split("\t"); // 源文件一定要用tab键分割,不然会出错。
if(splits.length!=2){
return ;
}
name.set(splits[0]);
score.set(Double.parseDouble(splits[1]));
// System.out.println(name);
// System.out.println(score);
context.write(name, score);
}
} public static class Reduce extends Reducer<Text, DoubleWritable, Text, DoubleWritable>{
private static DoubleWritable avg = new DoubleWritable();
@Override
protected void reduce(Text name, Iterable<DoubleWritable> scores,Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
// super.reduce(arg0, arg1, arg2);
double sum = 0;
int count = 0;
for(DoubleWritable score:scores){
sum += score.get();
count ++;
}
avg.set(sum/count);
// System.out.println(avg);
context.write(name, avg);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Score Avg");
job.setJarByClass(AvgScore.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1);
} }
3.程序解释
Mapper处理的数据是由InputFormat分解过的数据集,其中 InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSlit将由一个Mapper负责处理。此 外,InputFormat中还提供了一个RecordReader的实现,并将一个InputSplit解析成<key,value>对提 供给了map函数。InputFormat的默认值是TextInputFormat,它针对文本文件,按行将文本切割成InputSlit,并用 LineRecordReader将InputSplit解析成<key,value>对,key是行在文本中的位置,value是文件中的 一行。
Map的结果会通过partion分发到Reducer,Reducer做完Reduce操作后,将通过以格式OutputFormat输出。
Mapper最终处理的结果对<key,value>,会送到Reducer中进行合并,合并的时候,有相同key的键/值对则送到同一个 Reducer上。Reducer是所有用户定制Reducer类地基础,它的输入是key和这个key对应的所有value的一个迭代器,同时还有 Reducer的上下文。Reduce的结果由Reducer.Context的write方法输出到文件中。
Hadoop 学生平均成绩的更多相关文章
- PTA的Python练习题(十二)-第4章-7 统计学生平均成绩与及格人数
第4章-7 统计学生平均成绩与及格人数 a=eval(input()) b=list(map(int,input().split())) sum=sum(b) c=[i for i in b if i ...
- mapreduce实现学生平均成绩
思路: 首先从文本读入一行数据,按空格对字符串进行切割,切割后包含学生姓名和某一科的成绩,map输出key->学生姓名 value->某一个成绩 然后在reduce里面对成绩进行遍历 ...
- SQL 查询:查询学生平均成绩
编程萌新,因为遇到这么个SQL 查询的问题:在一张表A里有如下字段:学生姓名.学科名.学科成绩.写一条SQL 语句查出各科平均成绩并按学生姓名分组,按如下格式显示:学生姓名|语文|数学|英语.一开始遇 ...
- HDU2023-求平均成绩
描述: 假设一个班有n(n<=50)个学生,每人考m(m<=5)门课,求每个学生的平均成绩和每门课的平均成绩,并输出各科成绩均大于等于平均成绩的学生数量. 输入数据有多个测试实例,每个测试 ...
- sql-hive笔试题整理 1 (学生表-成绩表-课程表-教师表)
题记:一直在写各种sql查询语句,最长的有一百多行,自信什么需求都可以接,可......,想了想,可能一直在固定的场景下写,平时也是以满足实际需求为目的,竟不知道应试的题都是怎么出的,又应该怎么做.遂 ...
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- 案例:利用累加器计算前N个学生的总成绩和平均成绩
/* *录入N个学生的成绩,并求出这些学生的总成绩和平均成绩! * */ import java.util.Scanner; public class SumTest{ public static v ...
- /* * 有五个学生,每个学生有3门课的成绩,从键盘输入以上数据 *(包括学生号,姓名,三门课成绩),计算出平均成绩, *将原有的数据和计算出的平均分数存放在磁盘文件"stud"中。 */
1.Student类:类中有五个变量,分别是学号,姓名,三门成绩 package test3; public class Student { private int num; private Stri ...
- 按平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“英语”三门的课程成绩,按如下形式显示: 学生ID,,数据库,企业管理,英语,有效课程数,有效平均分
SELECT S# as 学生ID ,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='004') AS 数据库 ,(SELECT score FROM S ...
随机推荐
- 初识C语言(六)
数组 程序中需要容器,该容器有点特殊,它在程序中是一块连续的,大小固定并且里面的数据类型一致的内存空间,它的名字叫数组. 声明一个数组: 数据类型 数组名称[长度]; C语言中的数组初始化是有三种形式 ...
- figure 的使用
1.figure语法及操作(1)figure语法说明 figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, ...
- Shell常用快捷键
编辑命令 ctr+u 删除光标到行首(unix-line-discard) ctrl+k 删除此处至末尾(kill-line) ctr+e 光标移到末尾(end) ctr+a 光标移到行首(ahead ...
- struts2第一章-基本用法
一.struts简介 1.回顾 MVC M-model模型层 V-view 视图层 前端界面 C-controller 控制层 struts2: Apache提供的开源的控制层框架,相当于servl ...
- Python OpenCV 图像相识度对比
强大的openCV能做什么我就不啰嗦,你能想到的一切图像+视频处理. 这里,我们说说openCV的图像相似度对比, 嗯,说好听一点那叫图像识别,但严格讲, 图像识别是在一个图片中进行类聚处理,比如图片 ...
- GLSL ES 中的存储变量修饰符(const/attribute/uniform/varying/in/centroid in/out/centroid out)
GLSL ES 3.00 中支持的存储变量修饰符 变量名称 作用 示例 const 编译过程常量,或者函数的只读参数 const vec3 zAxis = vec3 (0.0, 0.0, 1.0); ...
- SOUI中TaskLoop组件介绍
SOUI是一套开源(MIT协议)的Windows平台下的DirectUI框架,它提供了大量的高效控件,也提供了很多扩展组件,目前已经持续维护近10年,在大量的项目中证明稳定可靠. GIT地址: 国内: ...
- UOJ#335. 【清华集训2017】生成树计数 多项式,FFT,下降幂,分治
原文链接www.cnblogs.com/zhouzhendong/p/UOJ335.html 前言 CLY大爷随手切这种题. 日常被CLY吊打系列. 题解 首先从 pruffer 编码的角度考虑这个问 ...
- IO流2
一.IO流简介及分类 1.IO流简介 IO流: 简单理解数据从一个地方流向另外一个地方 2.IO流分类 按照数据流动的方向 分为 输入流和输出流 按照数据流动的单位分为 字节流和字符流 二.四大 ...
- 使用JumpServer管理你的服务器
本文介绍CentOS 7从安装jumpserver到简单使用jumpserver管理服务器. 1.Jumpserver介绍 Jumpserver是一款开源的开源的堡垒机,如下图是官网介绍. 官网地址: ...