大数据基础-2-Hadoop-1环境搭建测试
Hadoop环境搭建测试
1 安装软件
1.1 规划目录 /opt
[root@host2 ~]# cd /opt
[root@host2 opt]# mkdir java
[root@host2 opt]# mkdir cdh
[root@host2 opt]# ls
cdh java

1.2 安装RZ工具
RZ工具:可以直接从win平台拖动下载好的软件到Linux平台
sudo yum -y install lrzsz
1.3 上传软件
将windows准备好的软件上传

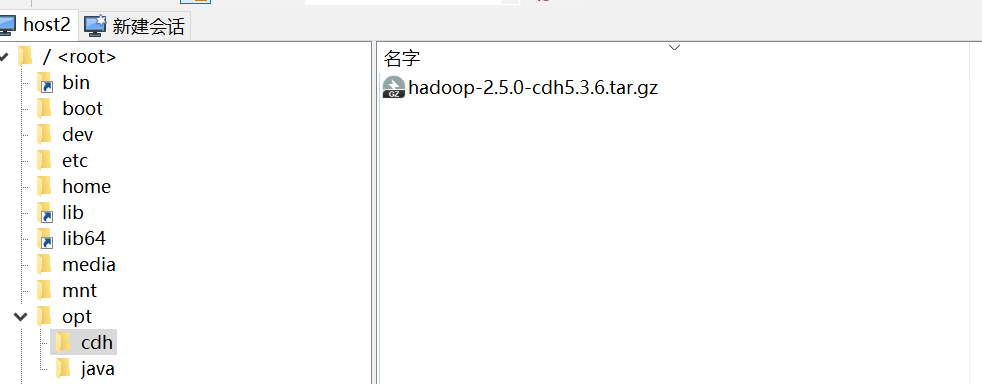
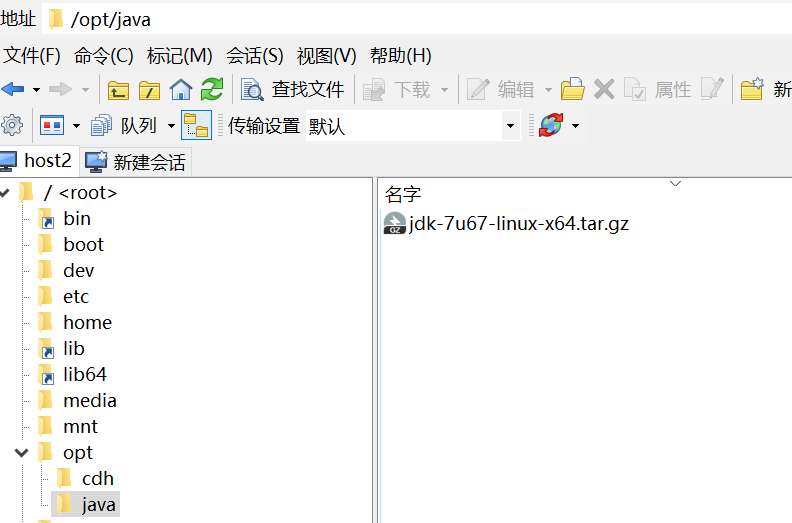
1.4 解压
[root@host2 java]# tar -zxf jdk-7u67-linux-x64.tar.gz #解压
[root@host2 java]# rm -rf jdk-7u67-linux-x64.tar.gz #删除压缩包
[root@host2 java]# ls
jdk1.7.0_67
[root@host2 java]# cd /opt/cdh/
[root@host2 cdh]# tar -zxf hadoop-2.5.0-cdh5.3.6.tar.gz #解压
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6 hadoop-2.5.0-cdh5.3.6.tar.gz
[root@host2 cdh]# rm -rf hadoop-2.5.0-cdh5.3.6.tar.gz #删除压缩包
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6
1.5删除hadoop说明文档,系统瘦身
[root@host2 opt]# rm -rf /opt/cdh/hadoop-2.5.0-cdh5.3.6/share/doc
2 配置JAVA、Hadoop环境变量
2.1 位置:/etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/java/jdk1.7.0_67
export PATH=$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/opt/cdh/hadoop-2.5.0-cdh5.3.6
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPPER_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
2.2 刷新
[root@host2 opt]# source /etc/profile #刷新
[root@host2 opt]# java -version #查看版本
java version "1.7.0_67"
Java(TM) SE Runtime Environment (build 1.7.0_67-b01)
Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
3 配置Hadoop环境
当前目录:/opt/cdh/hadoop-2.5.0-cdh5.3.6
3.1 配置JAVA环境变量
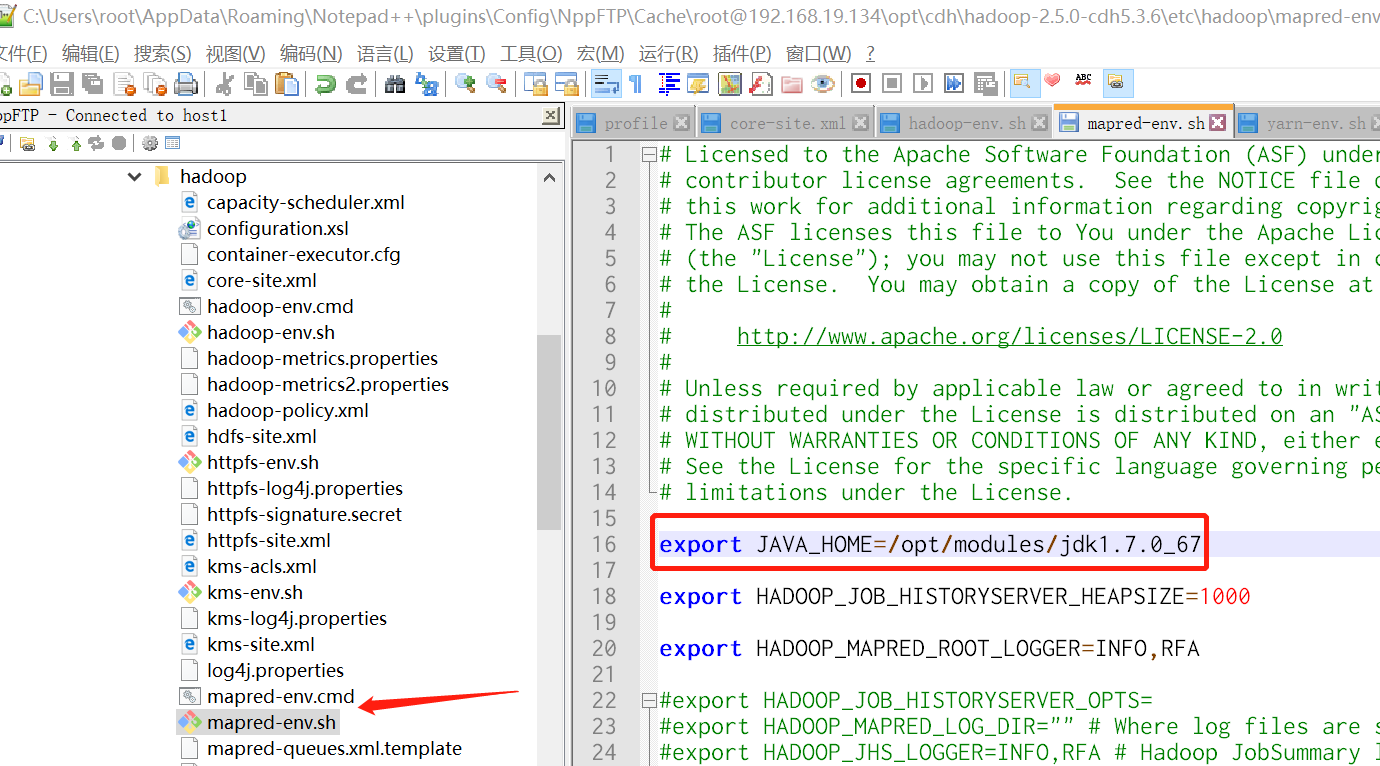
3.1.1 etc/hadoop/hadoop-env.sh
3.1.2 etc/hadoop/mapred-env.sh
3.1.3 etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/java/jdk1.7.0_67


3.2 配置文件
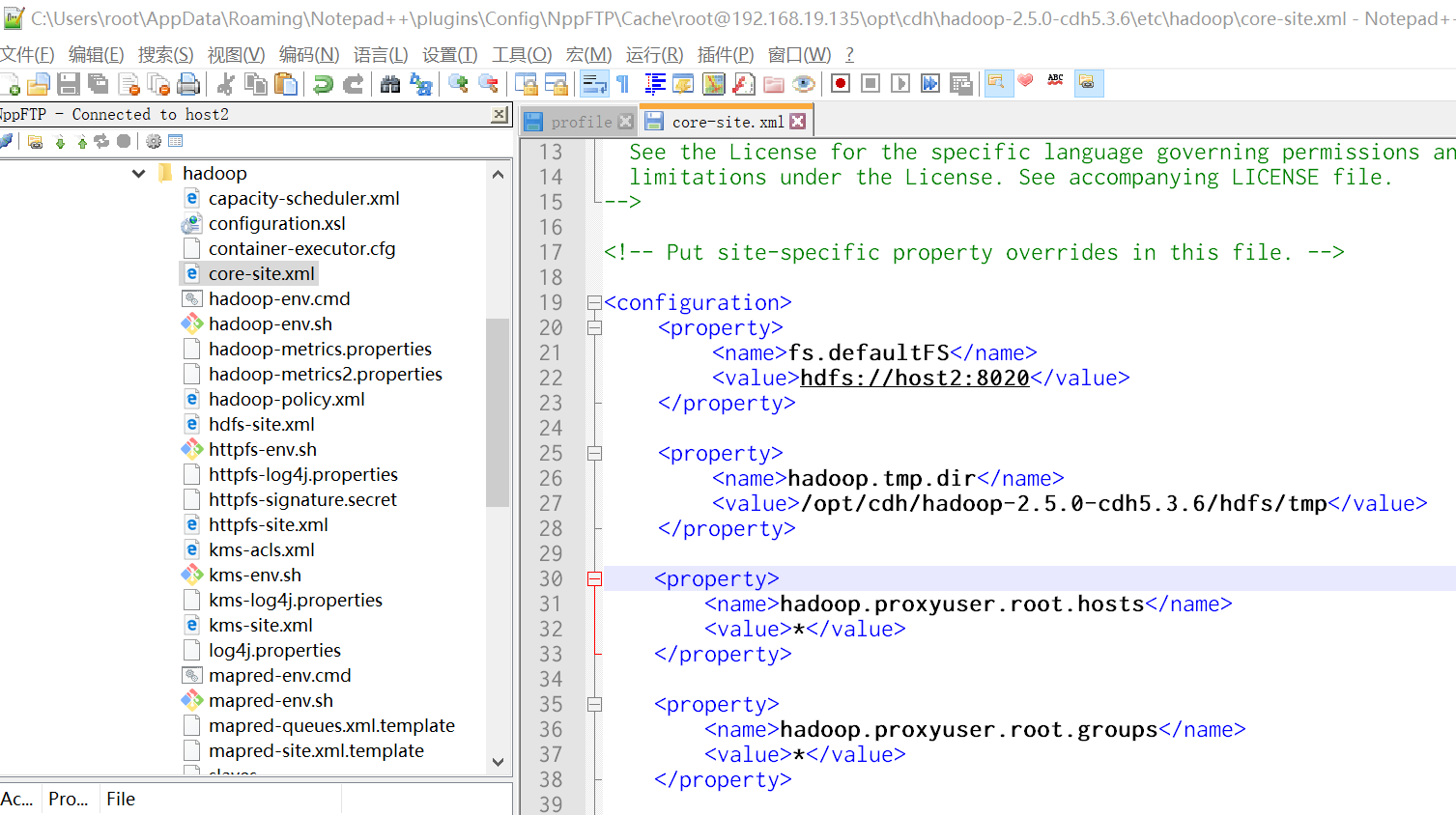
3.2.1 etc/hadoop/core-site.xml
说明:主节点NameNode位置及交互端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://host2:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/cdh/hadoop-2.5.0-cdh5.3.6/hdfs/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3.2.2 etc/hadoop/hdfs-site.xml
说明:系统中文件块的数据副本个数,是所有datanode总和,每个datanode上只能存放1个副本
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>

3.2.3 etc/hadoop/yarn-site.xml:
<configuration>
<!-- reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>host2</value>
</property>
</configuration>
3.2.4 etc/hadoop/mapred-site.xml
[root@host2 hadoop-2.5.0-cdh5.3.6]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定MapReduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置历史服务器端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-senior02.ibeifeng.com:10020</value>
</property>
<!-- 开历史服务器的WEB UI界面 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-senior02.ibeifeng.com:19888</value>
</property>
</configuration>
3.2.5 etc/hadoop/salves
说明:配置在从节点DataNode的位置,直接添加主机名
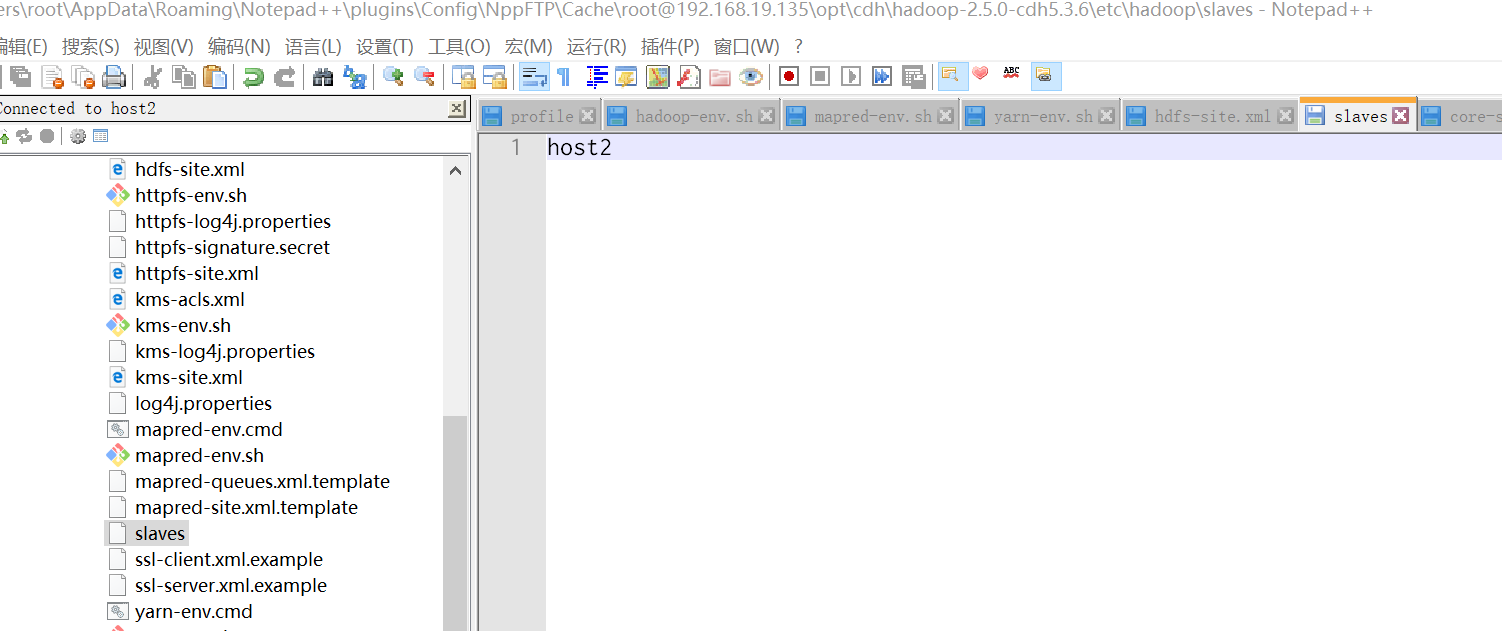
4 启动HDFS文件系统测试读写文件
4.1 格式化HDFS文件系统
[root@host2 ~]# cd /opt/cdh/
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6
[root@host2 cdh]# cd hadoop-2.5.0-cdh5.3.6/
[root@host2 hadoop-2.5.0-cdh5.3.6]# ls
bin bin-mapreduce1 cloudera etc examples examples-mapreduce1 include lib libexec sbin share src
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs namenode -format
18/06/03 10:57:06 INFO namenode.NameNode: STARTUP_MSG:
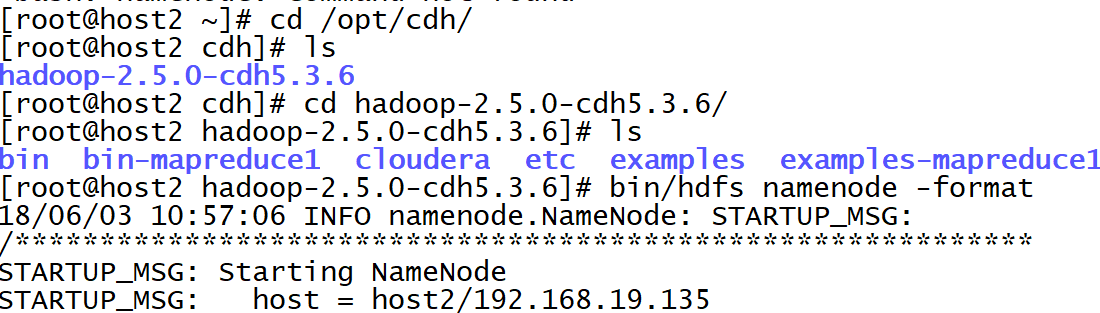
格式化成功
4.2 启动namenode和datanote
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/cdh/hadoop-2.5.0-cdh5.3.6/logs/hadoop-root-namenode-host2.out
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/cdh/hadoop-2.5.0-cdh5.3.6/logs/hadoop-root-datanode-host2.out
[root@host2 hadoop-2.5.0-cdh5.3.6]# jps
1255 Jps
1184 DataNode
1109 NameNode

4.3 登陆HDFS的WEB界面
端口号:50070
登陆WEB:http://host2:50070/explorer.html#/
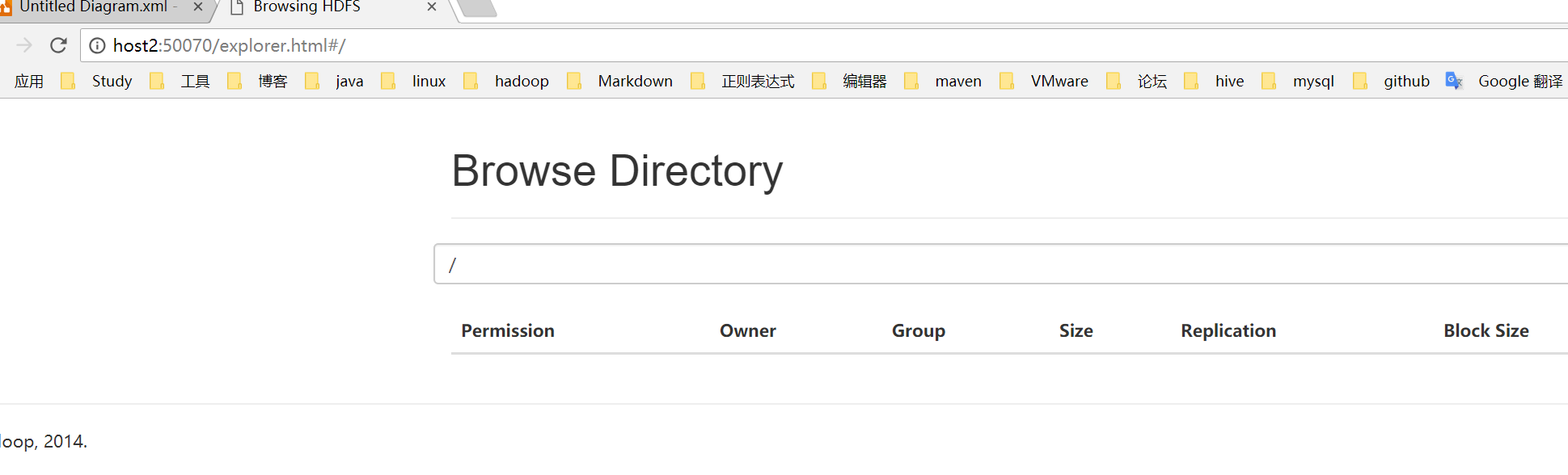
5 文件操作
5.1 创建目录
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -mkdir -p /test/day0603
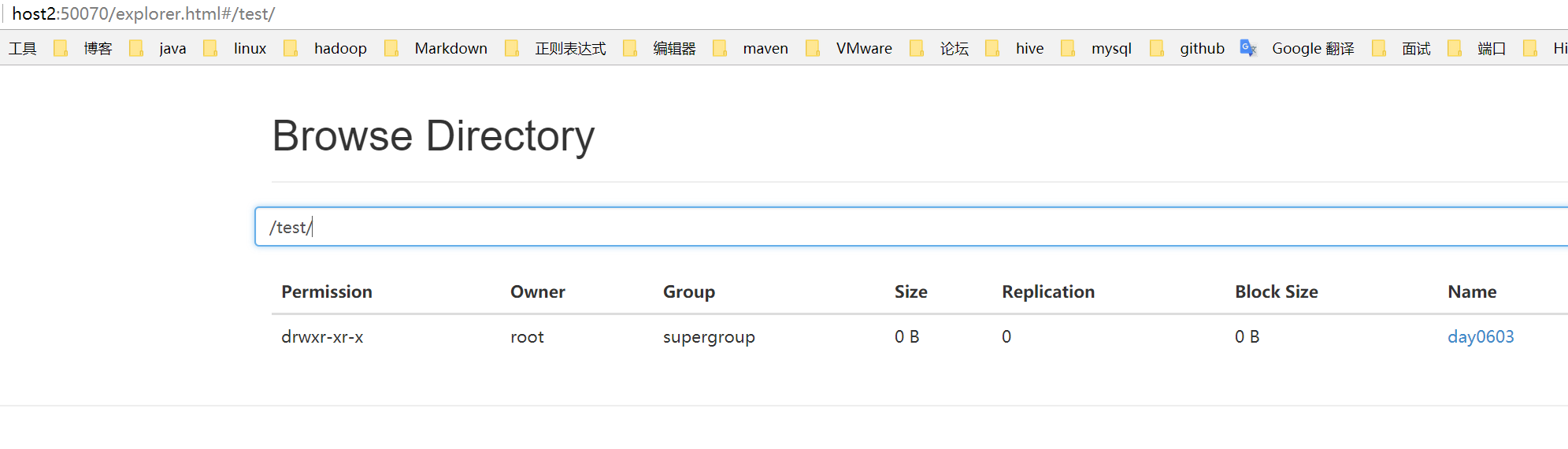
5.2 上传文件
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -put hdfs/060318-TheWolfAndTheDog.txt /test/day0603
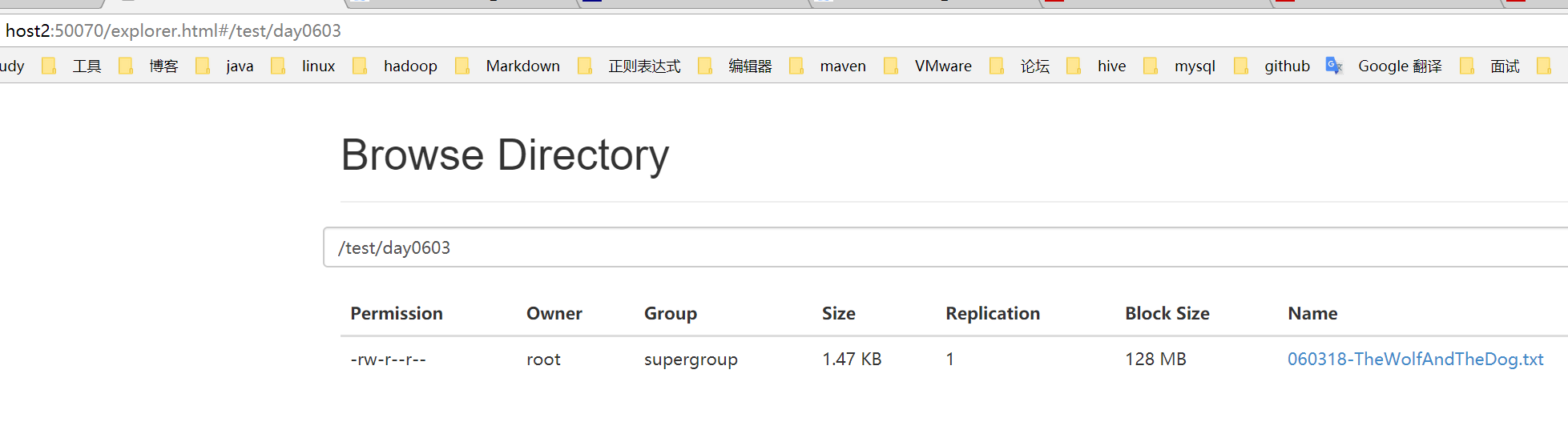
5.3 读取文件
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -cat /test/day0603/060318-TheWolfAndTheDog.txt

5.4 启动yarn并开启历史服务器
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start nodemanager
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start resourcemanager
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/mr-jobhistory-daemon.sh start historyserver #启动历史服务器
yarn管理界面
6 运行MapReduce WordCount程序
6.1 找到hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar

6.2 使用jar
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /test/day0603/060318-TheWolfAndTheDog.txt /test/output0603-1
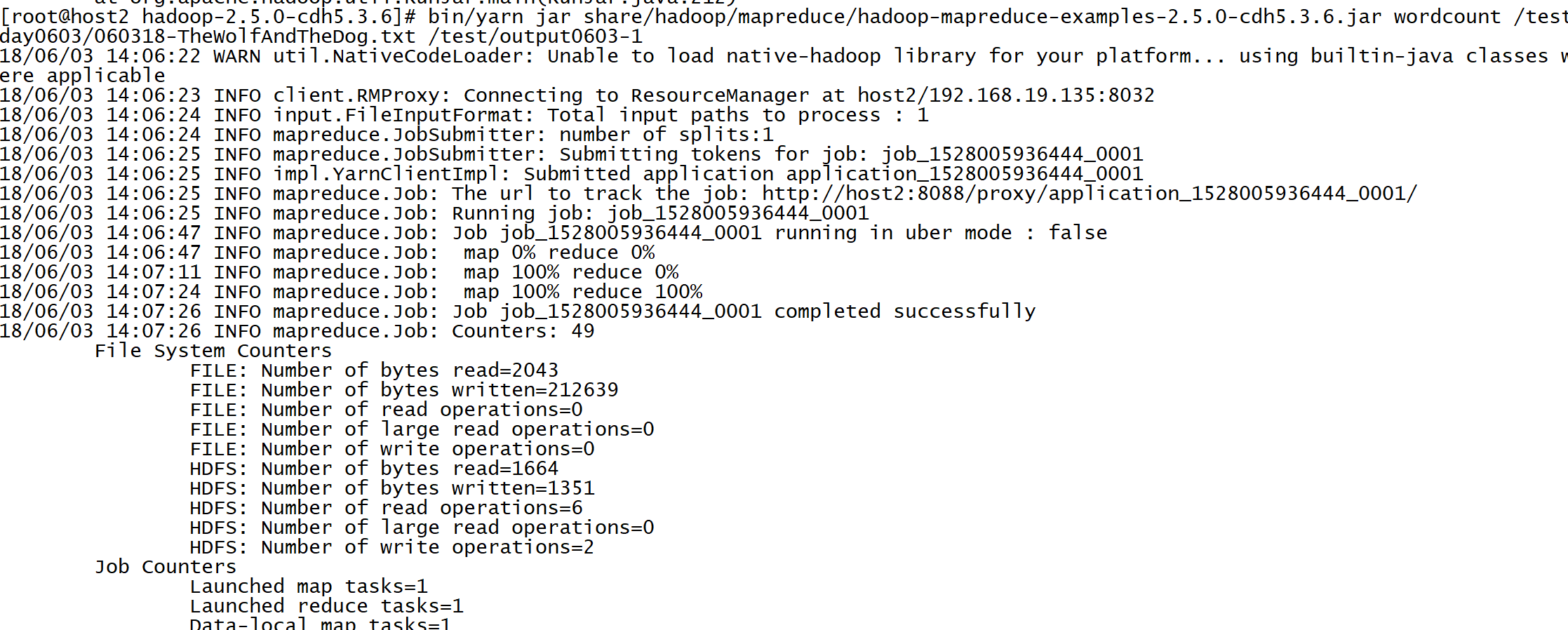
6.3 查看结果
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -text /test/output0603-1/part*
18/06/03 14:10:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
After 1
Are 1
As 2
Asks 1
Come 1
He 2
I 12
If 1
In 2
It’s 1
I’m 3
My 1
MapReduce 会针对key进行排序
Hadoop2.X伪分布式搭建并且测试完成
大数据基础-2-Hadoop-1环境搭建测试的更多相关文章
- 学习大数据基础框架hadoop需要什么基础
什么是大数据?进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB(1 ...
- 【原创】大数据基础之Hadoop(2)hdfs和yarn最简绿色部署
环境:3结点集群 192.168.0.1192.168.0.2192.168.0.3 1 配置root用户服务期间免密登录 参考:https://www.cnblogs.com/barneywill/ ...
- 【原创】大数据基础之Hadoop(1)HA实现原理
有些工作只能在一台server上进行,比如master,这时HA(High Availability)首先要求部署多个server,其次要求多个server自动选举出一个active状态server, ...
- 【原创】大数据基础之Hadoop(3)yarn数据收集与监控
yarn常用rest api 1 metrics # curl http://localhost:8088/ws/v1/cluster/metrics The cluster metrics reso ...
- 大数据学习——java操作hdfs环境搭建以及环境测试
1 新建一个maven项目 打印根目录下的文件的名字 添加pom依赖 pom.xml <?xml version="1.0" encoding="UTF-8&quo ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据技术之Hadoop入门
第1章 大数据概论 1.1 大数据概念 大数据概念如图2-1 所示. 图2-1 大数据概念 1.2 大数据特点(4V) 大数据特点如图2-2,2-3,2-4,2-5所示 图2-2 大数据特点之大量 ...
随机推荐
- php使用root用户启动
一般情况下,肯定是不推荐使用root用户启动php的 但是在某些服务器管理想使用WEB的方式来控制操作的话,那么就必须要使用root用户才有权限操作 1.修改配置文件php-fpm.conf的启动用户 ...
- Linux运维基础
一.服务器硬件 二.Linux的发展史 三.Linux的系统安装和配置 四.Xshell的安装和优化 五.远程连接排错 六.Linux命令初识 七.Linux系统初识与优化 八.Linux目录结构 九 ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- yidiandian
hzwer libreoj (需要拿新版的打开)
- Spring boot整合Mybatis
时隔两个月的再来写博客的感觉怎么样呢,只能用“棒”来形容了.闲话少说,直接入正题,之前的博客中有说过,将spring与mybatis整个后开发会更爽,基于现在springboot已经成为整个业界开发主 ...
- Nginx(三)------nginx 反向代理
Nginx 服务器的反向代理服务是其最常用的重要功能,由反向代理服务也可以衍生出很多与此相关的 Nginx 服务器重要功能,比如后面会介绍的负载均衡.本篇博客我们会先介绍 Nginx 的反向代理,当然 ...
- 为奋战在HIS创新路上的医院信息科赋能
为奋战在HIS创新路上的医院信息科赋能 南京都昌信息科技有限公司 袁永福 2017-7 ◆◆前言 近日,上海瑞金医院向我司表示:“我院从2000年开始自主开发医院信息系统,走出了一条可持续的信息化发展 ...
- 646. Maximum Length of Pair Chain(medium)
You are given n pairs of numbers. In every pair, the first number is always smaller than the second ...
- 小程序蓝牙BLE——自动连接设备(手环)
了解小程序蓝牙API: /** *蓝牙API: * 1.初始化蓝牙(判断蓝牙是否可用):openBluetoothAdapter * 2.获取蓝牙设备状态(蓝牙是否打开):getBluetoothAd ...
- [Alpha阶段]第二次Scrum Meeting
Scrum Meeting博客目录 [Alpha阶段]第二次Scrum Meeting 基本信息 名称 时间 地点 时长 第二次Scrum Meeting 19/04/04 大运村寝室6楼 90min ...