论文翻译:Ternary Weight Networks
论文地址:https://arxiv.org/pdf/1605.04711.pdf
Abstract
我们引入三值化权值网络(TWNs) - 权值约束为+1,0和-1的神经网络。 全(浮点或双精度)精度权值与三值化权值之间的欧几里德距离随比例因子被最小化。 此外,优化基于阈值的三元函数以获得可以快速且容易地计算的近似解。 TWN比最近提出的二值化同类网络具有更强的表达能力,并且比后者更有效。 同时,与全精度权值模型对手相比,TWN可实现高达16倍或32倍的模型压缩率并且需要更少的乘法。 在MNIST,CIFAR-10和大规模ImageNet数据集的基准测试表明,TWN的性能仅略高于全精度对应网络,但大大超过了类似的二值化神经网络。
1 Introduction
深度神经网络(DNN)在许多计算机视觉任务中取得了显著的进步,例如物体识别[4,10,17,18]和物体检测[14,16]。 这激发了将最先进的DNN模型部署到智能手机或嵌入式设备等现实应用的兴趣。 但是,这些模型通常需要相当大的存储和计算能力[15],并且很容易使小型嵌入式设备的有限存储,电池电量和计算机功能负担过重。 因此,它的应用仍然是挑战。
1.1 Binary weight networks and model compression
为了解决存储和计算问题[2,3],已经提出了寻求在DNN模型中对权重或激活值进行二值化的方法。 BinaryConnect [1]使用单一符号函数对权重进行二值化。二值化权值网络[15]采用相同的二值化函数,但增加了额外的缩放因子。是对以前方法BinaryNet [5]和XNOR-Net [15]的扩展,其中权值和激活值都是二值化的。这些模型消除了前向和反向传播中的大多数乘法,因此通过简单累加替换许多乘法运算,可以通过专门的深度学习(DL)硬件获得显着优势[13]。此外,二进制权重网络可实现高达32倍或64倍的模型压缩率。
尽管采用了二值化技术,但其他一些压缩方法侧重于识别具有少量参数的模型,同时通过以有损方式压缩现有的最先进DNN模型来保持准确性。 SqueezeNet [7]就是这样一个模型,其参数比AlexNet [10]少50倍,但在ImageNet上保持了AlexNet级别的准确性。 Deep Compression [3]是另一种最近提出的方法,它使用修剪,训练量化和哈夫曼编码来压缩神经网络。它将AlexNet和VGG-16 [17]的存储需求分别降低了35倍和49倍,而且不会降低精度。
2 Ternary weight networks
我们通过引入三值化神经网络(TWN)来解决有限的存储和有限的计算资源的问题,这网络将权值约束为三元值:+1,0和-1。 TWNs寻求在全精度权值网络(FPWN)对应物和二值化网络(BPWN)之间取得平衡。详细功能如下:
表达能力 在最近的网络架构中,如VGG [17],GoogLeNet [18]和残差网络[4],最常用的卷积核的大小为3×3。在二值化精度下,只有23×3 = 512个模板。然而,具有相同大小的三元滤波器拥有33×3 = 19683个模板,其表现能力比二值化网络强38倍。
模型压缩 在TWNs中,单位权值需要2位存储需求。因此,与浮点(32位)或双(64位)精度相比,TWNs可实现高达16倍或32倍的模型压缩率。以VGG-19 [17]为例,该模型的浮点数版需要约500M的存储要求,可以通过三值化减少到约32M。因此,虽然TWN的压缩率比BPWN的压缩率低2倍,但是压缩大多数现有的最先进的DNN模型是足够的了。
计算要求 与BPWN相比,TWN拥有额外的0状态。但是,对于任何多个操作,不需要累积0项。因此,与二值化精度网络对应物相比,TWN中的乘法累加运算保持不变。因此,它对于使用专用DL硬件训练大规模网络也是硬件友好的。
在下面部分中,我们将详细介绍三元权值网络问题以及近似但有效的解决方案。之后,引入了一个带有误差反向传播的简单训练算法,最后描述了运行时的用法。
2.1 Problem formulation
为了使三元权重网络表现良好,我们寻求最小化全精度权重W与三值化权值Wt之间的欧几里德距离以及非负比例因子α[15]。 优化问题的表述如下,

这里n是卷积核的大小。 利用近似值W≈αWt,三值化权值网络中的前向传播的基本块如下,

这里X是块的输入; *是卷积操作或内部产品; g是非线性激活函数; +表示没有任何乘法的内积或卷积运算;Xnext是块的输出,可以作为下一个块的输入。
2.2 Approximated solution with threshold-based ternary function
解决优化问题(1)的一种方法是扩展损失函数J(α; Wt)并分别取导数为w.r.t. α和Wtis。 然而,这将获得相互依赖的α和Wt i 。 因此,这种方式没有确定性解决方案[6]。 为了克服这个问题,我们尝试使用基于阈值的三元函数找到近似的最优解:
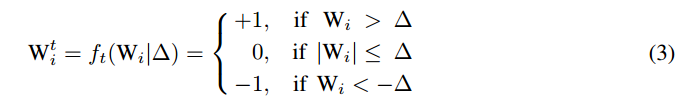
这里Δ是正阈值参数。 用(3),原始问题可以转化为

其中IΔ= {i |Wi|>Δ}和IIΔ|表示IΔ中的元素数量;
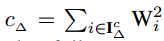
通过将αΔ*代入(4),我们得到一个Δ独立方程,可简化如下,

问题(6)没有直接的解决方案。 虽然可以进行离散优化来解决问题(由于Wis的状态是有限的),但这可能很耗时。 相反,我们做一个简单的假设Wis是由均匀或正态分布产生的。 如果Wis均匀分布在[-a; a]和Δ位于(0,a],近似的Δ*****1/3a,等于2/3E(|W|)。当从正态分布N(0, σ2)生成Wis时,Δ*****近似为0.6σ,等于0.75·E(|W|)。 因此,我们可以使用经验法则Δ*≈0.7·E(|W|)≈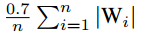 ,以便快速简便地计算。
,以便快速简便地计算。
2.3 Training with stochastic gradient descent method
我们使用随机梯度下降(SGD)方法来训练TWN。 如在Courbariaux等人 [1]和Rastegari等人 [15]一样,在前向和后向传播期间使用三值权重,但在参数更新期间没有。 此外,还采用了两种有用的技巧:批量标准化(BN)[8]和学习率缩放。 我们也使用动量加速训练过程。
2.4 Model compression and run time usage
在前向传播中,缩放因子α可以根据(2)转换为输入。因此,我们只需要保持三值化权重和缩放因子进行部署。 与浮点或双精度对应网络相比,这将让运行时使用的模型压缩率达到16倍或32倍。
3 Experiments
在本节中,我们在MNIST,CIFAR-10和ImageNet(2012)数据集1上对TWN与BPWN和FPWN进行基准测试。为了公平比较,我们将以下参数设置为相同:网络架构,正则化方法(L2权重衰减),学习速率缩放程序(多步)和优化方法(具有动量的SGD)。 BPWNs使用符号函数来对权重进行二值化和FPWN使用浮点权重。 见表 1详细设置:

MNIST 我们使用的LeNet-5 [11]架构是“32-C5 + MP2 + 64-C5 + MP2 + 512 FC + SVM”。 它以卷积块开始,拥有32个大小为5×5的卷积核。 最大池层步幅为2。“FC”是具有512个节点的全连接层。 顶层是SVM分类器有10个标签。 最后,用SGD 最小化hinge loss。
CIFAR-10 我们用“2×(128-C3)+MP2+2×(256-C3)+MP2+2×(512-C3)+MP2+1024- FC+Softmax定义了一个VGG简化架构,表示为VGG-7。与Courbariaux等人采用的架构相比 [1],我们忽略了最后一个全连接层。我们遵循He[4]和李等人的数据增强 步骤。 [12]用于训练:每侧填充4个像素,并从填充图像或其水平翻转中随机采样32×32裁剪。在测试时,我们只评估原始32×32图像的单个视图。
ImageNet 我们采用最近提出的ResNet-18架构[4]。此外,为了解决模型大小的问题,我们还对另一个放大的对应网络进行基准测试,其中每个块中的卷积核数量是原始网络的1.5倍。这个放大的模型被命名为ResNet-18B。在每次训练迭代中,图像随机裁剪为224×224大小。我们还没有使用任何调整大小的技巧[15]或任何颜色增强。

表 2 总结了先前全部的基准测试结果。在小规模数据集(MNIST和CIFAR-10)上,TWN实现了与FPWN相同的最先进表现性能,同时击败了BPWN。在大规模ImageNet数据集中,BPWN和TWN的性能都比FPWN差。然而,TWN和FPWN之间的精度差距小于BPWN和TWN之间的差距。因此,TWN再次击败BPWN。此外,随着模型尺寸的扩大,TWN(或BPWN)和FPWN之间的性能差距已经缩小。这表明低精度网络从大型模型获得的优点比全精度网络更多。
图1 显示了这些数据集的验证准确度曲线。如图所示,BPWN收敛缓慢,振动比TWN和FPWN更严重。然而,TWN收敛几乎与FPWN一样快速和稳定。
4 Conclusion
我们已经提出了三值化权重重网络优化问题,并给出了具有简单但准确的三元函数的近似解。所提出的TWN在高精度和高模型压缩率以及BPWN的潜在低计算要求找到了平衡点。 基准测试证明了所提方法的优越性能。
参考资料
本人根据谷歌翻译组织整理语句,英语水平有限,翻译错误望指正
论文翻译:Ternary Weight Networks的更多相关文章
- Ternary weight networks
Introduction 这两天看了一下这篇文章,我就这里分享一下,不过我还是只记录一下跟别人blog上没有,或者自己的想法(ps: 因为有时候翻blog时候发现每篇都一样还是挺烦的= =) .为了不 ...
- 论文翻译:Neural Networks With Few Multiplications
目录 Abstract 1. Introduction 2.Related Work 3.Binary And Ternary Connect 3.1 BINARY CONNECT REVISITED ...
- 论文翻译——Character-level Convolutional Networks for Text Classification
论文地址 Abstract Open-text semantic parsers are designed to interpret any statement in natural language ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
- 深度学习论文翻译解析(六):MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
论文标题:MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications 论文作者:Andrew ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 深度学习论文翻译解析(十):Visualizing and Understanding Convolutional Networks
论文标题:Visualizing and Understanding Convolutional Networks 标题翻译:可视化和理解卷积网络 论文作者:Matthew D. Zeiler Ro ...
- 深度学习论文翻译解析(十一):OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
论文标题:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 标题翻译: ...
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
随机推荐
- C语言报错:error: expected ‘while’ at end of input } ^
在建线程池过程当中遇见上图所示错误: 解决方法: Linux中定义: SYNOPSIS #include <pthread.h> void pthread_cleanup_push(voi ...
- Oracle完全卸载详解
Oracle数据库的安装这里就不说了,网上应该有很多,但是oracle数据库的卸载却找不到一个比较详细的完整卸载的说明.很多卸载不完全,会有遗留数据,影响后续的安装.所以自己整理一份以前上学的时候学习 ...
- 【学习总结】GirlsInAI ML-diary day-19-面向对象编程
[学习总结]GirlsInAI ML-diary 总 原博github链接-day19 认识面向对象 Python使用类(class)和对象(object),进行面向对象(object-oriente ...
- django rest framework renderer
渲染器 REST framework 包含许多内置的渲染器类,允许您使用各种 media type 返回响应.同时也支持自定义渲染器. 视图的渲染器集合始终被定义为类列表.当调用视图时,REST fr ...
- MATLAB-离散系统的数字PID控制仿真
%PID Controller clear all; close all; ts=0.001; %采样时间=0.001s sys=tf(,]); %建立被控对象传递函数 dsys=c2d(sys,t ...
- Day042---浮动 背景图设置 相对定位绝对定位
1.练习浮动 2.文本属性和字体属性 文本对齐 text-align left 左对齐 right 右对齐 center 中心对齐 justify 两边对齐 只适应于英文 text-indent ...
- Grains 与 Pillars
Grains 与 Pillars Grains介绍 Grains接口是salt用来采集底层系统信息的,包含了操作系统信息.域名.IP地址.内核.内存等一些底层信息.就是因为grains采集了这些信息, ...
- eclipse Tomcat 容器已经启动 但右下角 progress 一直显示100%
今天在家里 遇到一个问题 先上图 我的默认超时时间 eclipse 默认的 45s 果然 到了时间 依旧是 显示超时 解决方法其实 很简单 我看到网上有人说是tomcat 或者 eclip ...
- (十) 编写UVC程序
目录 编写UVC程序 流程简述 11个ioctl函数 查询属性 VIDIOC_QUERYCAP 枚举格式 VIDIOC_ENUM_FMT 查询当前格式 VIDIOC_G_FMT 尝试某种格式 VIDI ...
- 【JS】前端文件下载(无刷新)方法总结
#传统方法 利用iframe 或 form.submit 或 windows.open直接向后端发请求,后端返回文件流,后端处理成功后会直接返回到页面,浏览器会整理并打开自己的保存下载文件机制 . 1 ...