MySQL学习(七) 索引选择(半原创)
概述
该篇文章主要阐述一个例子(例子来自参考资料,侵删),然后总结今天相关的知识点。
例子 (例子来自参考文章,非原创)
创建表并插入数据,并执行查询
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB; delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata(); mysql> select * from t where a between 10000 and 20000;

可以看到该语句查询使用到了索引,然后进行如下操作

下面的三条SQL语句,就是这个实验过程。
set long_query_time=0;
select * from t where a between 10000 and 20000; /*Q1*/
select * from t force index(a) where a between 10000 and 20000;/*Q2*/
- 第一句,是将慢查询日志的阈值设置为0,表示这个线程接下来的语句都会被记录入慢查询日志中;
- 第二句,Q1是session B原来的查询;
- 第三句,Q2是加了force index(a)来和session B原来的查询语句执行情况对比。
我们在第三条语句指定了强制使用a 索引,假如第三天语句执行的时间快过第二条的,那么我们可以认为数据库选错了索引,相反没有选错, 如图3所示是这三条SQL语句执行完成后的慢查询日志。
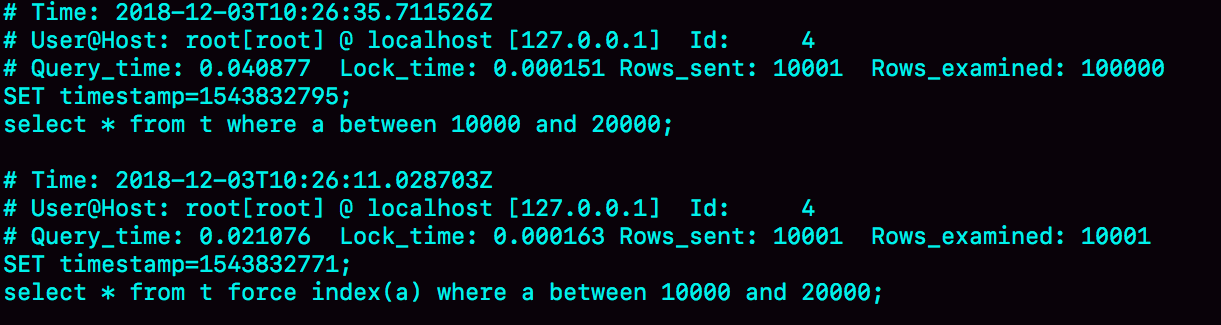
可以看到数据库确实选错了索引,我们要知道为什么选错了索引就要知道数据库是如何选择索引的。
优化器
我们从开始MySQL 架构图可以知道执行语句要经过一个优化器的组件,这个组件就相当于决策大脑,为语句选择合适的索引。
分析
一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。 而选择索引肯定看区分度高的索引,区分度高的索引能够准确找到符合条件的记录。思路如下 :
选择索引 -> 选择区分度高的索引 --> 如何找到区分度高的索引 --> 抽样统计算法
我们可以使用show index方法,看到一个索引的基数。如图4所示,就是表t的show index 的结果 。虽然这个表的每一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且其实都不准确。

假如数据库一行行去统计,对于大的表肯定是不行的,于是数据库就使用抽样统计。
采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:
- 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。
- 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16。
由于是采样统计,所以不管N是20还是8,这个基数都是很容易不准的。扫描的行数是一方面,还有一方面,例如使用非聚集索引的话还需要回表也是需要时间成本,优化器会从各个方面综合考虑最终得出最优解。
矫正统计错误
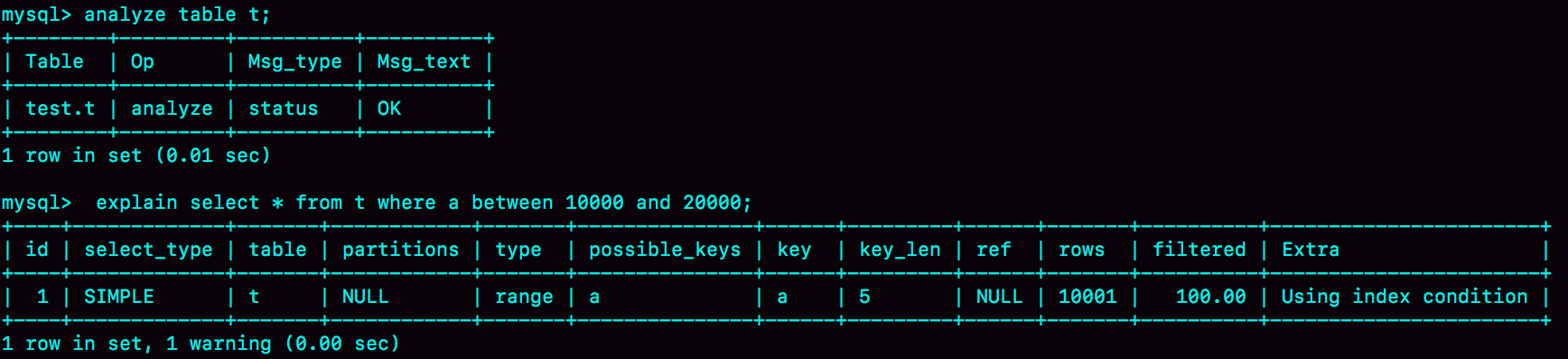
可以看到我们上面的统计是存在误差的,那么纠正这个偏差的方法肯定是让优化器再次统计一下。
补充题外话
count(*)、count(主键id)、count(字段)和count(1) 的区别?
count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;
而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
对于count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
注意哦,sever 自己判断
对于count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
对于count(字段)来说:
如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
#### 但是count()是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count()肯定不是null,按行累加。
按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(),所以我建议你,尽量使用count()
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
参考资料
- 《MySQL 45讲》
MySQL学习(七) 索引选择(半原创)的更多相关文章
- 【笔记】MySQL学习之索引
[笔记]MySQL学习之索引 一 索引简单介绍 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可. 普通 ...
- MySql学习(七) —— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- MySQL学习13 - 索引
一.索引的介绍 二 .索引的作用 三.常见的几种索引: 3.1 普通索引 3.2 唯一索引 3.3 主键索引 3.4 组合索引 四.索引名词 五.正确使用索引的情况 什么是最左前缀呢? 六.索引的注意 ...
- Mysql学习笔记—索引
一.什么是索引 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 在数据 ...
- MYSQL学习(三) --索引详解
创建高性能索引 (一)索引简介 索引的定义 索引,在数据结构的查找那部分知识中有专门的定义.就是把关键字和它对应的记录关联起来的过程.索引由若干个索引项组成.每个索引项至少包含两部分内容.关键字和关键 ...
- MySQL学习(七)
学习子查询 1 查出本网站最新的good_id最大的一条商品(要求取出商品名) mysql> select goos_id,goods_name from goods -> order b ...
- MySQL学习笔记——索引和视图
索引(index)和管理索引 模式中的一个数据库对象 作用:在数据库中用来加速对表的查询 创建:自动在主键和唯一键上面创建索引 通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O 与表独立存放, ...
- mysql学习之索引
首先,看一个例子,有一张大表,记录数超过1000,SELECT * FROM student WHERE name='xinan'; 如果没有索引,查找程序就得从头查找,很费时间,表越大越费时间.建立 ...
- mysql系列七、mysql索引优化、搜索引擎选择
一.建立适当的索引 说起提高数据库性能,索引是最物美价廉的东西了.不用加内存,不用改程序,不用调sql,只要执行个正确的'create index',查询速度就可能提高百倍千倍,这可真有诱惑力.可是天 ...
随机推荐
- cf1266D
注意到每一个的点出入流是不会变的,因此本质是让构造一张图满足这个出入流并且边上的流量之和最少,显然流量是平衡的,也就是所有节点的出入流之和为0 因此我们可以直接暴力的选择让负数点向正数点连边,连之后就 ...
- php文件操作(最后进行文件常用函数封装)
文件信息相关API $filename="./1-file.php"; //filetype($filename):获取文件的类型,返回的是文件的类型 echo '文件类型为:', ...
- bfs(队列模板)
[题目描述] 当你站在一个迷宫里的时候,往往会被错综复杂的道路弄得失去方向感,如果你能得到迷宫地图,事情就会变得非常简单. 假设你已经得到了一个n*m的迷宫的图纸,请你找出从起点到出口的最短路. [输 ...
- 海康 - 终端服务器 - TS-5012-F
简介 型号描述 主要特点 典型应用 技术参数 型号 参数 TS-5012-F (1T) TS-5012-F (2T) TS-5012-F (4T) TS-5012-F (8T) 系统参数 ...
- Eclipse设置代码模板
个人博客 地址:http://www.wenhaofan.com/article/20180904173808 根据下列路径打开配置窗口 Window->Preferences->Java ...
- 关于List比较好玩的操作
作为Java大家庭中的集合类框架,List应该是平时开发中最常用的,可能有这种需求,当集合中的某些元素符合一定条件时,想要删除这个元素.如: public class ListTest { publi ...
- 白面系列 mongoDB
mongoDB和redis一样,都是noSQL技术之一. redis是Key-Value存储,mongoDB是文档存储. 文档存储一般用类似json的格式存储,存储的内容是文档型的.文档是一组键值(k ...
- 腾讯云OCR图片文字识别
一. OCR OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别 ...
- C语言--“.”与“->”有什么区别?
这虽然是个小问题,但有时候很容易让人迷惑,因为有的时候用混淆了,程序编译不通过. 下面说说我对它们的理解. 一般情况下用“.”,只需要声明一个结构体.格式是,结构体类型名+结构体名.然后用结构 ...
- 批量启动关闭MS SQL 2005服务BAT
当装上了MSSQL2005后,内存的占用会变得很大.所以如果用一个批量处理来开启或关闭MSSQL2005所有的服务,那将会让我们的电脑更好使用.根据自己的经验,做出了下面两个批处理: 1.开启服务:( ...