http及浏览器相关知识点归纳
http是应用层协议,采用请求/响应模型
1、浏览器地址栏输入URL地址后发生了什么?
- 浏览器判断地址是否是合理的URL地址,是否是http协议请求,如果是则进入下一步
- 浏览器对此URL进行缓存检查:如果存在缓存则从本地提取文件(from memory cache,返回200),如果缓存过期或缓存不存在,则发起远程请求
- 向DNS服务器发送请求,解析URL对应的IP地址
- 客户端根据IP地址,连同cookie、userAgent等信息向web服务器发送请求,经过三次握手建立TCP连接
- 客户端向服务器端发送http请求,该请求作为TCP三次握手的第三个报文的数据发送给服务器
- ngnix根据URL做服务分发,分发到后端服务器或者是静态资源服务器,首屏请求一般是分发到静态服务器返回一个html
- 服务器端处理请求返回http响应报文,如果浏览器访问过该页面,缓存上有对应的资源,与服务器最后修改记录对比,一致返回304,否则返回200和对应资源
- 如果是200无缓存,则浏览器接收到信息并开始下载该html文件;如果是304有缓存,则浏览器从本地提取文件
- 释放TCP连接
- 浏览器解析该html文本并显示内容,同时使用和设置缓存
补充:
浏览器渲染引擎工作流程:
- 解析html构建DOM树时,渲染引擎会将html文件的标签元素解析成多个DOM元素对象节点,并且将这些节点根据父子关系组成一个树结构
- CSS文件被解析成CSS规则表,每一条CSS规则表按照从右到左的方式在DOM树上进行逆向匹配,DOM树具有了样式
- 将渲染树进行布局、绘制:先是对元素进行大小和位置的定位即position、margin、padding等,而后是color、background等
整个过程是逐步完成的。在浏览器渲染完首屏页面后,如果含有js文件对DOM进行操作会造成重排和重绘。
2. HTTP 请求报文与响应报文格式
请求报文:请求行request-line、请求头headers、空行、请求体request-body
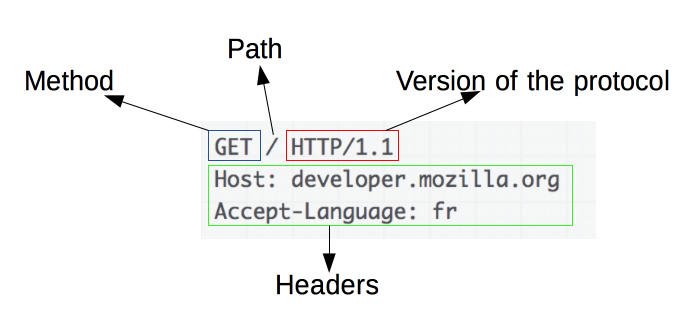
请求头部是由一个个键值对组成,每个一行。
请求正文:一般用于POST请求,GET请求不存在请求正文
响应报文:状态行status-line、响应头部headers、空行、响应体response-body
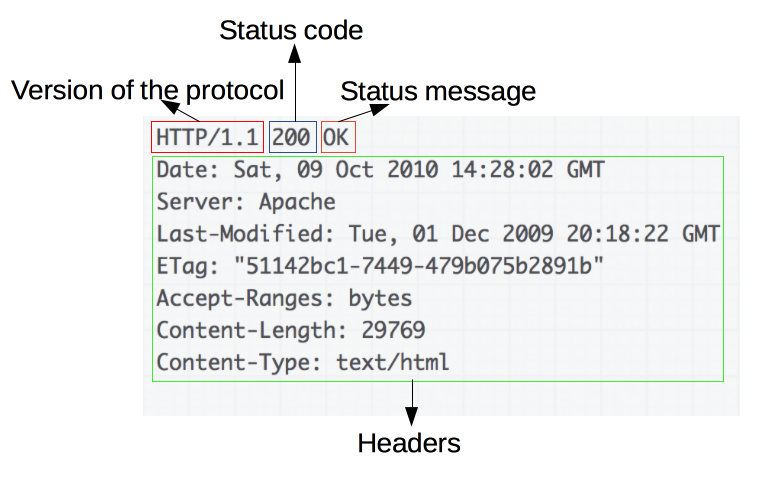
补充:
常见的 HTTP 状态码:
- 1XX:一些信息
- 2XX:成功信息
- 3XX:资源重定向信息
- 4XX:浏览器请求错误信息
- 5XX:服务器错误信息
常见的 HTTP 头部:
- 通用头部 General:同时适用于请求和响应
- 响应头部 Respose Headers
- 请求头部 Request Headers
常用的 HTTP 方法:GET、POST、DELETE、PUT、OPTIONS、HEAD
GET与POST请求在如下几个方面的差别:
- 后退/刷新操作的影响
- 是否可收藏为书签
- 是否能被缓存
- 参数是否保留在浏览器历史中
- 发送数据时对数据长度的限制(get因为数据是附在URL之后所以有限制,而POST无限制)
- 对数据类型的限制(GET只允许ASCII,POST无限制)
- 安全性
3. 分别介绍 Cookie 和 Session 的作用及它们之间的区别
cookie:用于保存用户操作的历史信息,由服务器生成,存储在浏览器端。
- cookie可以同时被前台与后台操作;
- cookie可以跨页面存取,不可以跨服务器访问;
- cookie是有生命周期的,默认与浏览器相同,如果进程退出,cookie会被销毁
- 一个cookie是一个小型的文本文件,以键值对的形式保存
- 作用是与服务器进行交互,作为http规范的一部分而存在,可以在http返回体里通过设置Set-cookie来告知浏览器所要存储的cookie
- 表示唯一的cookie:name、domain、path
cookie应用场景:
- 保存用户登录信息
- 跟踪统计用户访问该网站的习惯:比如访问时间、网页停留时间等
cookie的缺点:
- cookie有数量和长度限制:每个浏览器存储的个数不能超过300个,每个服务器不能超过20个,数据量不能超过4K;
- 安全性问题:如果cookie被拦截,对方就会获取到所有的session信息
session:服务器存储,把sessionID、用户信息、用户操作保存在服务器上
- session的安全性比较高,但是session过多会导致性能下降
- 每个会话会分配一个单独的sessionID,通过cookie存储一个sessionID,具体的数据存储在服务器上。如果用户登录会在cookie中保存一个session_id,下次再次请求的时候会把该session_id携带上,服务器会在session中查找对应的id的session数据。
补充:
本地存储除了cookie还有web Storage,即:localStorage和sessionStorage
localStorage:用于持久化的本地存储,除非是主动删除数据,否则数据会永久保存。
sessionStorage:会话级别的存储,一旦浏览器窗口关闭sessionStorage被销毁,只要这个浏览器窗口没有关闭,即使刷新页面或者是进入同源的另一个页面数据仍存在
web Storage具有自己的方法,而cookie需要自己封装方法
4. HTTP协议版本知识点
HTTP/1.1有什么优缺点:
优点:
- 新增持久连接:connection: keep-alive,多个请求和响应可利用同一个TCP连接,减少了很多建立和关闭连接的消耗和延迟
- 新增管道pipe机制:请求可以同时发出,响应会按顺序依次返回
- 新增分块传输:不必等数据全部处理完毕再返回,服务器处理完部分数据就将该部分数据发送回客户端
- 增加host字段
- 增加了错误及警告信息的描述:引入Warning头域和24个状态响应码
- 带宽优化:引入Range头域,允许只请求部分资源。在响应头部中Content-Range声明了返回这部分内容的长度,如果服务器返回该请求范围的内容则相应的返回206状态码,告诉Cache这是不是完整的一个对象。
缺点:
- 队头阻塞:虽然增加了持久连接和管道机制,但是如果前面的响应很耗时,后面的处理依然需要等待,同样消耗性能。
- http/1.1头部会携带很多冗余信息
HTTP/2.0的新特性:
- 二进制分帧:在应用层HTTP/2.0和传输层TCP之间增加一个二进制分帧层,实现低延迟和高吞吐量
- 多路复用
- headers数据压缩
- 服务器推送
5. HTTPS 工作原理
HTTPS实际是加了SSL(Secure Socket Layer)这层协议的HTTP而已,in other words,就是加上加密处理、认证和完整性保护的HTTP~此时数据传输的都是加密后的数据
HTTP之前是和TCP直接通信,现在需要先和SSL通信,然后再由SSL和TCP通信
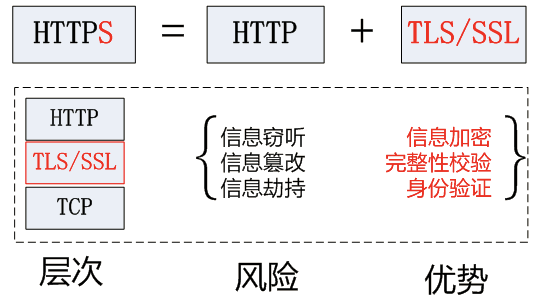
HTTP 和 HTTPS 的差别
- HTTP是明文传输,HTTPS是密文传输
- HTTPS需要到CA申请证书,需要费用
- 两者使用不同的连接方式和不同的端口号:HTTP用的端口是80,HTTPS是443
6. 跨域what & how
同源策略(Same Origin Policy,SOP):需要“协议+域名+端口号”均一致!
跨域:由于浏览器的同源策略影响,不能浏览其他网站的脚本
一些跨域的例子:
http://www.a.cn/index.html 调用 http://www.b.cn/server.php 跨域,主域不同 http://abc.a.cn/index.html 调用 http://def.b.cn/server.php 跨域,子域名不同 http://www.a.cn:8080/index.html 调用 http://www.a.cn/server.php 跨域,端口不同 https://www.a.cn/index.html 调用 http://www.a.cn/server.php 跨域,协议不同 localhost 调用 127.0.0.1 跨域
解决跨域:
- jsonP
- postMessage
- 跨域资源共享CORS
- webSocket协议
- node代理跨域
- ngnix代理跨域
7. 缓存 —— 详细见博文“缓存初探”
总结来说就是:
- 有Service Worker时优先使用Service Worker的缓存
- 浏览器刷新页面,使用memory Cache,当页面关闭,memory cache失效
- 使用disk cache:
- 如果有强制缓存且缓存未失效,则使用强制缓存,不请求服务器,此时状态码均是200
- 如果强制缓存失效(超过cache-control中max-age的值),则使用对比缓存,浏览器将待确认资源上次返回时response中的Last-Modified值和ETag值写入本次Request中的If-Modified-Since和If-None-Match传给服务器,服务器对比本次和之前的值是否有变化,有变化,则返回200和新资源;无变化则返回304
- 发送网络请求,等待响应
8. 浏览器性能优化
从三个大的方向入手:
A 资源缓存
B 资源的合并压缩
C 浏览器的加载、解析、渲染机制
A 资源缓存
- 将静态资源部署在CDN
- 利用HTTP缓存机制:利用Headers的Cache-control参数 —— 减少http请求次数
B 资源的合并压缩
- JS和CSS的处理:合并是减少JS文件数 —— 减少HTTP请求;压缩是极大减小文件的体积。一般而言会分类为:公共代码+页面响应代码+第三方代码,这样可以对JS或者CSS实现按需加载
- 图片的处理:
- 使用webP格式
- 使用iconfont替换img
- CSS Sprite合并图片
- 使用base64直接把图片编码写入css中
C 浏览器加载、解析、渲染机制
- 将CSS引入的link写在<head>中
- 引用外部的JS文件一般写在<script>底部,避免加载JS会阻塞HTML的解析。
- 代码层面尽量减少重绘,避免重排:
- 尽量通过class处理样式切换
- 需要多次重排的元素可以设置position为absolute或fixed,使元素尽量脱离文档流
当浏览器解析到<script>标签,有如下三种情况:
- 如果标签内是内嵌到HTML中的JS代码 —— 直接执行
- 如果是外链JS文件,且该文件未下载完 —— HTML解析过程被阻塞直到JS文件下载完毕 —— JS执行 —— HTML继续解析
- 如果是外链JS文件,且文件已下载完毕 —— 直接执行JS代码,且并不阻塞HTML解析
HTTP请求加载资源的瓶颈在于带宽而不是请求数量,其实减少HTTP请求数来提升网站性能主要是基于两点:
- HTTP建立比较耗时,并且每个HTTP请求还有一定的网络延时,因此需要的HTTP请求越多,产生的耗时就越多。HTTP/1.1的keep-alive的支持很大程度优化了该问题
- 每个HTTP请求需要附带额外的数据,比如Headers信息、cookie信息等,当请求资源很小时,附带的数据可能会比所需的资源还要大。
附赠http相关的15个相关知识点的链接:https://mp.weixin.qq.com/s/SolYPhZCzP87XlVWYdn1Cw
http及浏览器相关知识点归纳的更多相关文章
- Caffe学习系列(二)Caffe代码结构梳理,及相关知识点归纳
前言: 通过检索论文.书籍.博客,继续学习Caffe,千里之行始于足下,继续努力.将自己学到的一些东西记录下来,方便日后的整理. 正文: 1.代码结构梳理 在终端下运行如下命令,可以查看caffe代码 ...
- Android开发涉及有点概念&相关知识点(待写)
前言,承接之前的 IOS开发涉及有点概念&相关知识点,这次归纳的是Android开发相关,好废话不说了.. 先声明下,Android开发涉及概念比IOS杂很多,可能有很多都题不到的.. 首先由 ...
- IOS开发涉及有点概念&相关知识点
前言,IOS是基于UNIX的,用C/C+/OC直通系统底层,不想android有个jvm. 首先还是系统架构的分层架构 1.核心操作系统层 Core OS,就是内存管理.文件系统.电源管理等 2.核心 ...
- Django知识点归纳总结之HTTP协议与URL
Django复习知识点归纳总结 1.HTTP协议 超文本传输协议(Hyper Text Transfer Protocol),是用于万维网服务器与本地浏览器之间的传输超文本的传送协议. HTT ...
- rem和css3的相关知识点
☆☆☆rem和css3的相关知识点☆☆☆ 一. Web front-end development engineer rem是根据页面的根元素的font-size的一个相对的单位,即 html{ fo ...
- 给Java新手的一些建议----Java知识点归纳(J2EE and Web 部分)
J2EE(Java2 Enterprise Edition) 刚出现时一般会用于开发企业内部的应用系统,特别是web应用,所以渐渐,有些人就会把J2EE和web模式画上了等号.但是其实 J2EE 里面 ...
- React其它相关知识点
React其它相关知识点 一,解释一下React Fiber? 简单来说,核心就是在虚拟dom和浏览器的调用栈之间多了一个虚拟调用栈,和虚拟dom一样,这个虚拟调用栈也是在内存中的,这个虚拟调用栈就类 ...
- django学习-2.urls.py和view.py的相关知识点
1.URL函数简单解析 1.1.url() 函数可以接收四个参数,分别是两个必选参数:regex.view,和两个可选参数:kwargs.name. def url(regex, view, kwar ...
- UITableView相关知识点
//*****UITableView相关知识点*****// 1 #import "ViewController.h" // step1 要实现UITableViewDataSou ...
随机推荐
- TYVJ1061 Mobile Service
P1061 Mobile Service 时间: 1000ms / 空间: 131072KiB / Java类名: Main 描述 一个公司有三个移动服务员.如果某个地方有一个请求,某个员工必须赶到那 ...
- NSDateFormatter 今年日期格式化成字符串是明年日期问题?
在项目里我要是把NSDate格式化成字符串 我的format是@"YYYY年MM月dd日 HH:mm" 传入日期2013-12-30 15:00:00后,返回给我的字符串是 201 ...
- jsp-解决自写Servlet老是报错404
写好servlet进行测试老是报404解决方案. 1.确保web.xml配置好 2.Bulid Path项目,在Libraries界面Add External JARs,在tomcat的lib目录下面 ...
- 4.8 this关键字
/** * 测试this * @author Hank * */ /* 创建一个对象分为如下四步: 1.分配对象空间,并将对象成员变量初始化为0或空 2.执行属性值的显示初始化 3.执行构造方法 4. ...
- Day9 - 异步IO\数据库\队列\缓存
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko SS ...
- 8-MySQL高级-主从-2
详细配置主从同步的方法 主和从的身份可以自己指定,我们将虚拟机Ubuntu中MySQL作为主服务器,将Windows中的MySQL作为从服务器. 在主从设置前,要保证Ubuntu与Windows间的网 ...
- 我写的界面,在ARM上跑
这个...其实,我对ARM了解并不多,我顶多也就算是知道ARM怎么玩,EMMC干啥,MMU干啥,还有早期的叫法,比如那个NorFlash NandFlash ,然后也就没啥了. 然后写个裸机什么的,那 ...
- SPRING+JPA+Hibernate配置方法
1.applicationContext.xml <?xml version="1.0" encoding="UTF-8"?> <beans ...
- Linux系统搭建Red5服务器
Linux系统搭建Red5服务器 Red5 是 支持Windows,Linux等多平台的RTMP流媒体服务器,Windows下搭建相对容易,图形界面操作比较简单,Linux服务器的环境下没有图形界面, ...
- flutter setInitialRoute: 不生效
概述 需要实现native跳转到flutter 指定的路由页面. iOS 工程中发现 FlutterViewController setInitialRouter 无效,在我的需求里面是: 在iOS ...