Java并发机制的底层实现原理之volatile应用,初学者误看!
Java并发机制的底层实现原理之volatile应用,初学者误看!的更多相关文章
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- 【java并发编程艺术学习】(三)第二章 java并发机制的底层实现原理 学习记录(一) volatile
章节介绍 这一章节主要学习java并发机制的底层实现原理.主要学习volatile.synchronized和原子操作的实现原理.Java中的大部分容器和框架都依赖于此. Java代码 ==经过编译= ...
- Java 并发系列之二:java 并发机制的底层实现原理
1. 处理器实现原子操作 2. volatile /** 补充: 主要作用:内存可见性,是变量在多个线程中可见,修饰变量,解决一写多读的问题. 轻量级的synchronized,不会造成阻塞.性能比s ...
- 《Java并发编程的艺术》读书笔记:二、Java并发机制的底层实现原理
二.Java并发机制底层实现原理 这里是我的<Java并发编程的艺术>读书笔记的第二篇,对前文有兴趣的朋友可以去这里看第一篇:一.并发编程的目的与挑战 有兴趣讨论的朋友可以给我留言! 1. ...
- (第二章)Java并发机制的底层实现原理
一.概述 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. ...
- Java并发机制和底层实现原理
Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码转化为汇编指令在CPU上执行.Java中的并发机制依赖于JVM的实现和CPU的指令. Java语言规范第三版中 ...
- 并发艺术--java并发机制的底层实现原理
前言 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. 一 ...
- java并发机制的底层实现原理
volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的"可见性".可见性是说当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值. vola ...
- 【java并发编程艺术学习】(五)第二章 java并发机制的底层实现原理 学习记录(三) 原子操作的实现原理学习
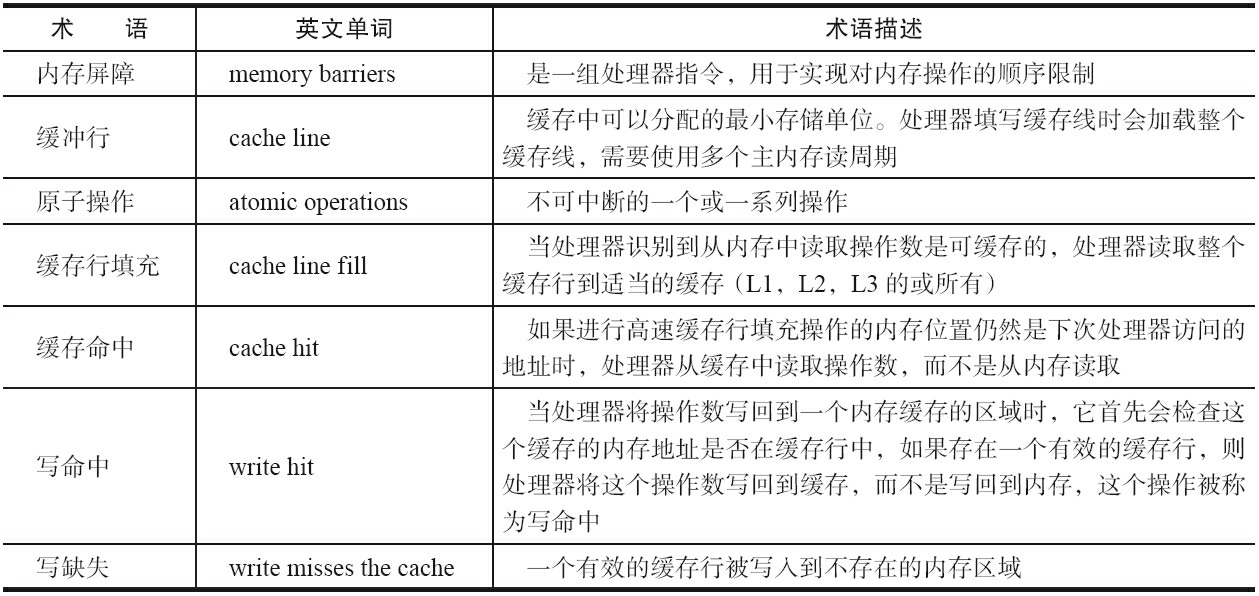
章节介绍 主要包括 术语定义.处理器如何实现原子操作.Java如何实现原子操作: 原子(atomic)本意是 不能再进一步分割的最小粒子,“原子操作” 意为 不可被中断的一个或一系列操作. 术语定义 ...
随机推荐
- 寻找第K大数的方法总结
http://www.cnblogs.com/zhjp11/archive/2010/02/26/1674227.html
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十一章:模板测试
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十一章:模板测试 代码工程地址: https://github.co ...
- python 语法错误
- css技巧:清除浮动
1.常用方法——overflow 给浮动元素的容器添加overflow:hidden;或overflow:auto;可以清除浮动,另外在 IE6 中还需要触发 hasLayout ,例如为父元素设置容 ...
- ArcGIS 发布高程服务。10.4
ArcGIS 发布高程必须是10.21以上,我用10.4. 前端用ArcGIS For API 4.x. ARCGIS很早之前有CS版本的ArcScene,可查看高程TIF文件,但机制和BS的完全不同 ...
- 远程控制工具&&驱动安装仍然没有声音
1. 2.下面是一个远程控制工具 TeamViewer
- 如何用django框架完整的写一个项目
实现目标及功能,增删改,并且实现搜索,分页,日期插件,删除提示,以及批量导入等功能 软件版本: python3.5 django1.11 一 用pycharm创建一个项目,名字自定义 二 编辑url ...
- 在Linux/Unix上运行SuperSocket
SuperSocket通过(Mono 2.10或更新版本)来实现跨平台的特性 由于Unix/Linux不同于Windows上的文件路径格式,SuperSocket提供了专用于Unix/Linux系统上 ...
- xml path 列转行实例
SQL Server2005提供了一个新查询语法——For XML PATH(''),这个语法有什么用呢?想象一下这样一个查询需求:有两个表,班级表A.学生表B,要查询一个班级里有哪些学生?针对这个需 ...
- java el表达式报空指针异常(nullpointexception)
最近在使用el表达式的时候,用到了int型变量,因为,很多时候,变量不会被赋初值,后面考虑了下,应该将声明由int 改为integer,改了之后就一直报空指针异常,后面仔细查看,我的getter和se ...