Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)
一、如何学习大规模数据集?
在训练样本集很大的情况下,我们可以先取一小部分样本学习模型,比如m=1000,然后画出对应的学习曲线。如果根据学习曲线发现模型属于高偏差,则应在现有样本上继续调整模型,具体调整策略参见第六节的高偏差时模型如何调整;如果发现模型属于高方差,则可以增加训练样本集。
二、随机梯度下降法(Stochastic Gradient Descent)
之前在讲到优化代价函数的时候,采取的都是“批量梯度下降法”Batch Gradient,这种方法在每次迭代的时候,都需要计算所有的训练样本,对于数以亿计的大规模样本集而言,计算代价太大,再加上需要多次迭代,累加起来计算量更大,收敛速度会比较慢。
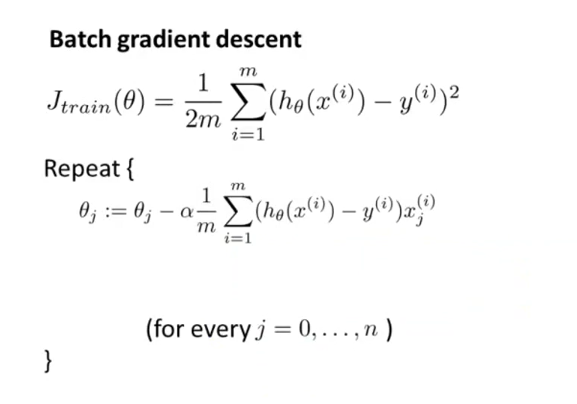
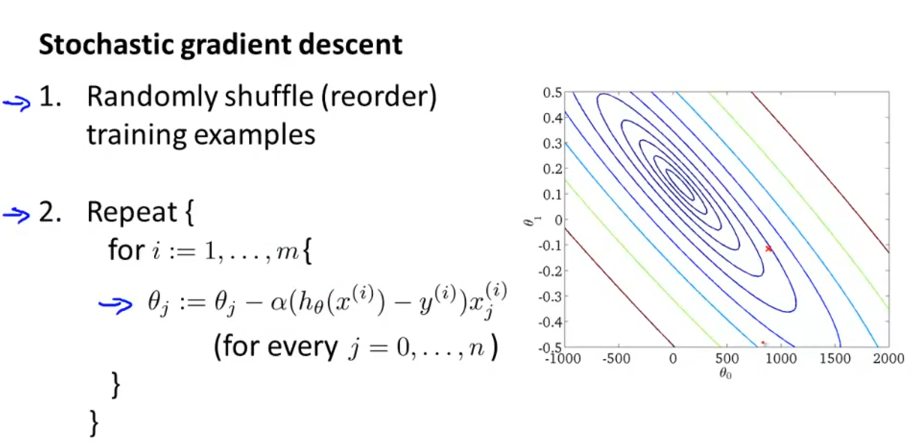
随机梯度下降法,首先打乱样本顺序,然后遍历样本集。对每一个样本就相当于迭代一次,调整一次参数,所以总体计算量小很大。对整个样本集的重复次数也就是1-10次足矣。所以,该算法要快很多。
三、小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法介于批量梯度下降法与随机梯度下降法之间,每次迭代用b个样本数据,b往往=10,或者2~100的数。但是在使用小批量梯度下降法时,如果你采用的是向量化计算时,能够同时并行处理b个样本,此时效率应该比随机梯度法更好,因为其并没有并行处理数据。


四、随机梯度下降法的收敛。
随机梯度下降法最后的收敛不一定是全局最小值,这点跟批量梯度下降法不大一样,而是在全局最小值周围振荡徘徊,只要很接近全局最小值,这也是可以接受的。其实可以动态调整学习速率α=常数1/(迭代次数+常数2),这样随着迭代进行,α逐渐减小,有利于最后收敛到全局最小值。但是由于"常数1"与“常数2”不好确定,所以往往设定α是固定不变的。
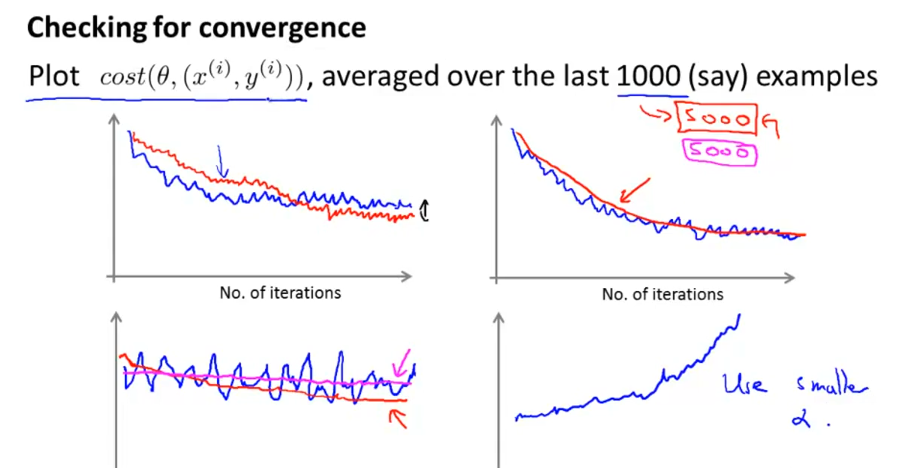
如何判断随着迭代进行,模型在收敛呢?每隔1000或5000个样本,计算这些样本的J值一个总体平均值,然后画出来,如下图所示。从图形走势看模型迭代过程中是不是在下降收敛。如第四张图,走势是上升的,则应调小学习速率α。
五、在线机器学习
以物流运输为例,当用户登陆网站,选择包裹起始地与目的地后,网站据此提供一个服务价格,用户可能接受,也可能拒绝。一个用户完成后,我们就得到了一个样本(x,y),这样我们就可以用随机梯度下降法来学习了。当有用户源源不断进来时,模型就不断地学习调整参数Θ。即便随着经济发展,用户可以接受更高价格了,模型也能根据用户选择,动态调整参数Θ。在线机器学习的前提是,网站能源源不断地获取大量样本数据。

另一个应用例子就是用户搜索商品时,根据用户的点击情况来动态调整参数,尽量将点击率高的产品推荐给用户。
Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)的更多相关文章
- [C12] 大规模机器学习(Large Scale Machine Learning)
大规模机器学习(Large Scale Machine Learning) 大型数据集的学习(Learning With Large Datasets) 如果你回顾一下最近5年或10年的机器学习历史. ...
- 斯坦福第十七课:大规模机器学习(Large Scale Machine Learning)
17.1 大型数据集的学习 17.2 随机梯度下降法 17.3 微型批量梯度下降 17.4 随机梯度下降收敛 17.5 在线学习 17.6 映射化简和数据并行 17.1 大型数据集的学习
- Ng第十七课:大规模机器学习(Large Scale Machine Learning)
17.1 大型数据集的学习 17.2 随机梯度下降法 17.3 微型批量梯度下降 17.4 随机梯度下降收敛 17.5 在线学习 17.6 映射化简和数据并行 17.1 大型数据集的学习 ...
- Coursera在线学习---第六节.构建机器学习系统
备: High bias(高偏差) 模型会欠拟合 High variance(高方差) 模型会过拟合 正则化参数λ过大造成高偏差,λ过小造成高方差 一.利用训练好的模型做数据预测时,如果效果不好 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 大规模机器学习(Large Scale Machine Learning)
本博客是针对Andrew Ng在Coursera上的machine learning课程的学习笔记. 目录 在大数据集上进行学习(Learning with Large Data Sets) 随机梯度 ...
- 吴恩达机器学习笔记(十一) —— Large Scale Machine Learning
主要内容: 一.Batch gradient descent 二.Stochastic gradient descent 三.Mini-batch gradient descent 四.Online ...
- Coursera在线学习---第五节.Logistic Regression
一.假设函数与决策边界 二.求解代价函数 这样推导后最后发现,逻辑回归参数更新公式跟线性回归参数更新方式一摸一样. 为什么线性回归采用最小二乘法作为求解代价函数,而逻辑回归却用极大似然估计求解? 解答 ...
- Coursera在线学习---第四节.过拟合问题
一.解决过拟合问题方法 1)减少特征数量 --人为筛选 --靠模型筛选 2)正则化(Regularization) 原理:可以降低参数Θ的数量级,使一些Θ值变得非常之小.这样的目的既能保证足够的特征变 ...
随机推荐
- (转)NEST.net Client For Elasticsearch简单应用
由于最近的一个项目中的搜索部分要用到 Elasticsearch 来实现搜索功能,苦于英文差及该方面的系统性资料不好找,在实现时碰到了不少问题,现把整个处理过程的代码分享下,给同样摸索的人一些借鉴,同 ...
- WebKit 源码分析 -- loader
原文地址: http://peirenlei.iteye.com/blog/1718569 摘要:本文介绍 WebCore 中 Loader 模块是如何加载资源的,分主资源和派生资源分析 loader ...
- 关于c中的一些新函数
localtime 和 localtime_s: localtime:localtime(const time_t * _Time) time_t t;struct tm *local;time(&a ...
- chrome extension demos
chrome extension demos demo https://github.com/hartleybrody/buzzkill/blob/master/bootstrap.js https: ...
- [国家集训队]最长双回文串 manacher
---题面--- 题解: 首先有一个直观的想法,如果我们可以求出对于位置i的最长后缀回文串和最长前缀回文串,那么我们枚举分界点然后合并前缀和后缀不就可以得到答案了么? 所以我们的目标就是求出这两个数列 ...
- BZOJ3329:Xorequ——题解
http://www.lydsy.com/JudgeOnline/problem.php?id=3329 原式化为x^2x=3x,而且实际上异或就是不进位的加法. 那么我们又有x+2x=3x,所以在做 ...
- [bzoj] 2002 弹飞绵羊 || LCT
原题 简单的LCT练习题. 我们发现对于一个位置x,他只能跳到位置x+k,也就是唯一的父亲去.加入我们将弹飞的绵羊定义为跳到了n+1,那么这就形成了一棵树.而因为要修改k,所以这颗树是动态连边的,那么 ...
- BZOJ4103 [Thu Summer Camp 2015]异或运算 【可持久化trie树】
题目链接 BZOJ4103 题解 一眼看过去是二维结构,实则未然需要树套树之类的数据结构 区域异或和,就一定是可持久化\(trie\)树 观察数据,\(m\)非常大,而\(n\)和\(p\)比较小,甚 ...
- missing ) after argument list
../node_modules/.bin/webpack-dev-server --progress --color --hot --inline -d --host 192.168.1.101 -- ...
- [BJOI2018]求和
link 其实可以用$sum(i,j)$表示从$i$到$1$的$k$次方的值,然后就是$lca$的基本操作 注意,能一起干的事情就一起搞,要不会超时 #include<iostream> ...