【Python3 爬虫】17_爬取天气信息
需求说明
到网站http://lishi.tianqi.com/kunming/201802.html可以看到昆明2018年2月份的天气信息,然后将数据存储到数据库。
实现代码
#-*-coding:utf-8 -*-
import urllib.request
import random
import pymysql
from bs4 import BeautifulSoup user_agent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',
] headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': user_agent[random.randint(0,5)]} print("连接到mysql服务器")
db = pymysql.connect("192.168.6.128","root","root","test_db",charset="utf8")
print("******连接成功********") cursor = db.cursor() cursor.execute("DROP TABLE IF EXISTS TB") sql = """CREATE TABLE TB(DT_DATE VARCHAR(10),
HIGH_TEMP int,LOW_TEMP int,WEATHER VARCHAR(40),WIND VARCHAR(40),WIND_TAIL VARCHAR(10))"""
cursor.execute(sql) url = "http://lishi.tianqi.com/kunming/201802.html" index = urllib.request.urlopen(url).read()
print(index)
#print(index)
index_soup = BeautifulSoup(index) i = 1
#此处的class_=""是为了过滤calss="t1"的标题栏
uls = index_soup.find("div",class_="tqtongji2").find_all("ul",class_="") #获取全部的ul作为一个列表 for ul in uls:
lis = ul.find_all('li') #将每个li下的标签获取为列表
li = [x for x in lis]
V_DT_DATE = li[0].text.strip() V_HIGH_TEMP = li[1].text.strip()
V_LOW_TEMP = li[2].text.strip()
V_WEATHER = li[3].text.strip()
V_WIND = li[4].text.strip()
print(V_WIND)
V_WIND_TAIL = li[5].text.strip()
inser_tb = ("INSERT INTO TB " "VALUES(%s,%s,%s,%s,%s,%s)")
data = (V_DT_DATE,V_HIGH_TEMP,V_LOW_TEMP,V_WEATHER,V_WIND,V_WIND_TAIL)
cursor.execute(inser_tb,data)
db.commit()
print("数据已经爬取并且存储到Mysql")
db.close()
运行上述程序后,在数据库查询结果如下:
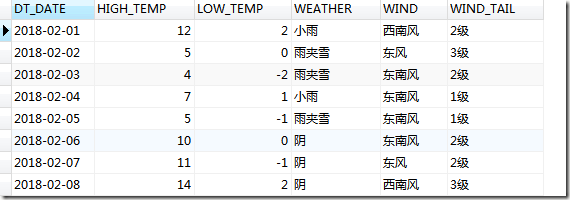
【Python3 爬虫】17_爬取天气信息的更多相关文章
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
- Python3爬虫之爬取某一路径的所有html文件
要离线下载易百教程网站中的所有关于Python的教程,需要将Python教程的首页作为种子url:http://www.yiibai.com/python/,然后按照广度优先(广度优先,使用队列:深度 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- 第7天-javascript内置对象
数组相关方法 concat 用来连接多个数组 <script> var a = [1,2,3]; var b = [3,4,5]; var c = a.concat(b); console ...
- python 定义二维数组
1. myList = [([0] * n) for i in range(m)],n是列,m是行 >>> array=[([0]*3) for i in range(4)] > ...
- EasyUI学习总结(六)——EasyUI布局(转载)
本文转载自:http://www.cnblogs.com/xdp-gacl/p/4088198.html 一.EasyUI布局介绍 easyUI布局容器包括东.西.南.北.中五个区域,其中中心面板是必 ...
- xUtils 中的 BitmapUtils
韩梦飞沙 韩亚飞 313134555@qq.com yue31313 han_meng_fei_sha xUtils框架,包括BitmapUtils.DbUtils.ViewUtils和Htt ...
- lightoj 1052 - String Growth & uva 12045 - Fun with Strings 矩阵
思路:很容易发现规律,数列和Fib数列一样的. 记开始的时候啊a的个数为Y,b的个数为X.建立矩阵. 代码如下: #include<iostream> #include<cstdio ...
- [转] FileSystemXmlApplicationContext、ClassPathXmlApplicationContext和XmlWebApplicationContext简介
今天在用Spring时遇到一个问题,提示找不到applicationContext.xml文件.原来是在加载这个文件时调用的方法不太合适,所以造成了程序找不到项目下的xml配置文件. 我们常用的加载c ...
- Active Snake (Level Set 模型)
前沿:最近由于大论文实验的原因,需要整理几种Snake方法,以比较道路提取效果.所以今天晚上就将电脑中的一些LBF Snake代码作一下分类定义.并给出效果.以便比较. 1. 原始的LBF Snake ...
- 2014 linux
[51CTO精选译文]每年大概12月前后,人们喜欢给出种种预测,预言他们认为未来一年技术界会出现什么样的变化.本文也不例外,只不过侧重介绍2014年值得关注的十大最受关注的Linux发行版(桌面版或移 ...
- 在ios中微信video和audio无法自动播放解决方案
WeixinJSBridgeReady页面初始化的时候会执行 document.addEventListener("WeixinJSBridgeReady", function ( ...
- ubuntu安装elasticSearch及插件
原文地址:http://www.niu12.com/article/18 前提 1.安装好Java1.8以上环境并配置好JAVA_HOME(elasticsearch运行环境) 2.node环境6.5 ...