xpath 的使用
如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10520271.html
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
一、xpath 浅谈
1.1 xpath 是什么?
给某些规律信息找通用表达式,我们首先想到的是正则,然而,对于大部分的我们正则用的是不好的,如果用来处理HTML文档是很累,那么有没有其他的方法?答案是肯定的,有!那就是XPath,我们可以先将网络获取的String类型数据转换成 HTML/XML文档,然后用 XPath 查找 HTML/XML 节点或元素。
即XPath (XML Path Language) 是一门在 XML 文档(如下图)中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历
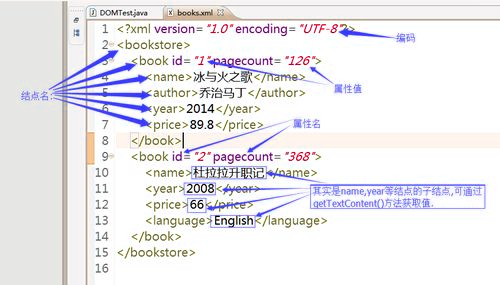
1.2 lxml 库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath语法,来快速的定位特定元素以及节点信息。
二、 xpath 路径表达式
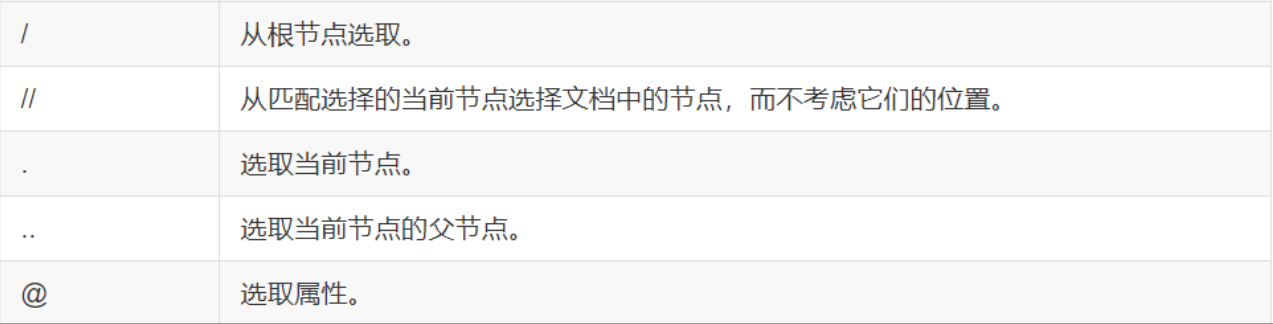
2.1 最常用的路径表达式
2.2 常用路径表达式以及表达式的结果

2.3 选取未知节点


2.4 选取若干路径,通过在路径表达式中使用“|”运算符,您可以选取若干个路径
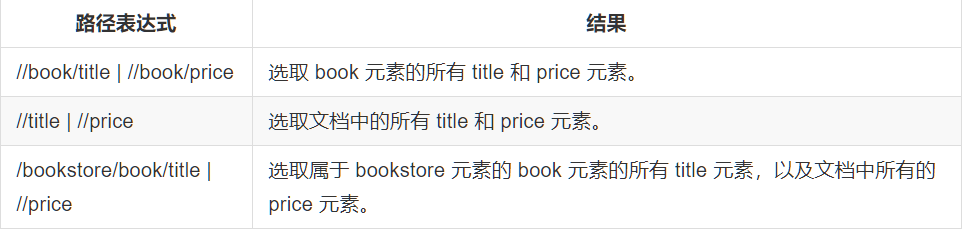
2.5 xpath的运算符

三、xpath 入门测试
3.1 lxml 读取数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试页面</title>
</head>
<body>
<ol>
<li class="haha">醉卧沙场君莫笑,古来征战几人回</li>
<li class="heihei">两岸猿声啼不住,轻舟已过万重山</li>
<li id="hehe" class="nene">一骑红尘妃子笑,无人知是荔枝来</li>
<li class="xixi">停车坐爱枫林晚,霜叶红于二月花</li>
<li class="lala">商女不知亡国恨,隔江犹唱后庭花</li>
</ol>
<div id="pp">
<div>
<a href="http://www.baidu.com">李白</a>
</div>
<ol>
<li class="huanghe">君不见黄河之水天上来,奔流到海不复回</li>
<li id="tata" class="hehe">李白乘舟将欲行,忽闻岸上踏歌声</li>
<li class="tanshui">桃花潭水深千尺,不及汪伦送我情</li>
</ol>
<div class="hh">
<a href="http://mi.com">雷军</a>
</div>
<div class="jj">
<b href="http://mi.com"><c>3</c></b>
<b href="http://mi.com"><c>5</c></b>
<b href="http://mi.com"><c>6</c></b>
<b href="http://mi.com"><c>8</c></b>
<b href="http://mi.com"><c>9</c></b>
<b href="http://mi.com"><c>3</c></b>
</div>
<ol>
<li class="dudu">are you ok</li>
<li class="meme">会飞的猪</li>
</ol>
</div>
</body>
</html>
3.2 xpath 入门实验
- lxml 、element 、etree
import requests # lxml
# element 标签
# etree 标签树
from lxml import etree url = 'https://www.qiushibaike.com/text/' x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left']/div[@id='qiushi_tag_120441381']/div[@class='author clearfix']/a[1]/img/@src''' x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left']/div[@id='qiushi_tag_112124634']/div[@class='author clearfix']/a[1]/img/@src''' x = '//img/@src' x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left']
/div[@id='qiushi_tag_112124634']/a[@class='contentHerf']/div[@class='content']/span''' x = '//div[@class="content"]/span/text()'
response = requests.get(url=url,verify = False)
response.encoding = 'utf-8' # String 串
html = response.text # 使用etree,转换成标签树
# json.loads() 类似 html_tree = etree.HTML(html) # print(html_tree)
# print(etree.tostring(html_tree).decode('utf-8')) # 对etree对象使用xpath方法,根据xpath语句进行数据的查找
src = html_tree.xpath(x) print(src)
- 获取所有的 <li> 标签
from lxml import etree html = etree.parse('hello.html')
li_list = html.xpath('//li') print(li_list) # 打印<li>标签的元素集合
print(len(li_list))
- 继续获取<li> 标签的所有 class属性
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result)
- 继续获取<li>标签下hre 为 link1.html 的 <a> 标签
from lxml import etree
html = etree.parse('./hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print(result)
- 获取<li> 标签下的所有 <span> 标签
from lxml import etree
data = '''
<div>
<ul>
<li class="item-0">你好,老段<a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''
html = etree.HTML(data)
result = html.xpath('//li//span')
print(result[0].text)
- 获取 <li> 标签下的<a>标签里的所有 class
# 获取 <li> 标签下的<a>标签里的所有 class
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class') print(result)
- 获取最后一个 <li> 的 <a> 的 href
from lxml import etree xml = etree.parse('./hello.html') result = xml.xpath('//li[last()]/a/@href') print(result)
- 获取倒数第二个元素的内容
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')
print(result[0].text)
print(result)
- 获取 class 值为 bold 的标签名
# 获取 class 值为 bold 的标签名
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# tag方法可以获取标签名
print(result[0].tag)
print(result[0].text)
- 练习使用xpath获取books该xml文件中的内容
from lxml import etree books = '''
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2008</year>
<price>30.00</price>
</book>
<book category="children" lang="zh">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
''' books_tree = etree.HTML(books) books = books_tree.xpath('//book[price<=30][year + 3 = 2008]') print(books) # 将查询到的book中的所有属性选出来
ret = books[0].xpath('.//@*')
print(ret)
- 数据转换成标签树
from lxml import etree html = '''<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html" class="linkjfdlsfjls">third item</a></li>
<li class="shfs-inactive"><a href="link4.html">third item</a></li>
<li class="isjfls-inactive"><a href="link5.html">third item</a></li>
<li class="qwert-inactive"><a href="link6.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>''' # 数据转换成标签树
#方式一
html_tree = etree.HTML(html) # 方式二,可以将文件中的直接进行转换
html_tree2 = etree.parse('./data.html') # print(html_tree,html_tree2) # print(etree.tostring(html_tree).decode('utf-8'))
# 获取文件中所有的标签li
# xpath返回的数据是列表,标签<Element 内存地址>
li = html_tree.xpath('//li')
# print(li) li = html_tree.xpath('//li[@class="item-1"]')
# print(li[0].xpath('..//a/text()')) # 查询class属性不等于“item-1” 标签
li = html_tree.xpath('//li[@class!="item-1"]')
# print(li) # 查询li标签,class 包含inactive 字符串
li = html_tree.xpath('//li[contains(@class,"inactive")]')
# print(li)
# print(li[0].xpath('./a/@*')) # 查询li标签,class 不包含inactive字符串
li = html_tree.xpath('//li[not(contains(@class,"inactive"))]')
# print(li)
# print(etree.tostring(li[0]).decode('utf-8')) # 查询li标签,class 不包含inactive字符串 同时包含class =item-1
li = html_tree.xpath('//li[not(contains(@class,"inactive"))][@class="item-1"]')
# print(li)
# print(etree.tostring(li[-1]).decode('utf-8')) # 查询li标签,最后一个
# print(etree.tostring(html_tree).decode('utf-8'))
li = html_tree.xpath('/html/body/div/ul/li')
li = html_tree.xpath('//li[last()-1]')
# print(li,etree.tostring(li[0])) # 查询位置小于4的标签
li = html_tree.xpath('//li[position()<4]')
print(li)
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事多做几遍。。。。。。

xpath 的使用的更多相关文章
- xpath提取多个标签下的text
title: xpath提取多个标签下的text author: 青南 date: 2015-01-17 16:01:07 categories: [Python] tags: [xpath,Pyth ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- 在Java中使用xpath对xml解析
xpath是一门在xml文档中查找信息的语言.xpath用于在XML文档中通过元素和属性进行导航.它的返回值可能是节点,节点集合,文本,以及节点和文本的混合等.在学习本文档之前应该对XML的节点,元素 ...
- XPath 学习二: 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. 下面列出了最有用的路径表达式: 表达式 描述 nodename 选 ...
- xpath 学习一: 节点
xpath 中,有七种类型的节点: 元素.属性.文本.命名空间.处理指令.注释.以及根节点 树的根成为文档节点或者根节点. 节点关系: Parent, Children, sibling(同胞), A ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
- 使用python+xpath 获取https://pypi.python.org/pypi/lxml/2.3/的下载链接
使用python+xpath 获取https://pypi.python.org/pypi/lxml/2.3/的下载链接: 使用requests获取html后,分析html中的标签发现所需要的链接在& ...
- 关于robotframework,app,appium的xpath定位问题及常用方法
关于类似的帖子好像很多,但是没有找到具体能帮我解决问题的办法.还是自己深究了好久才基本知道app上面的xpath定位和web上的不同点: 先放一个图: A,先说说不用xpath的场景,一般是用于存在i ...
- Selenium Xpath Tutorials - Identifying xpath for element with examples to use in selenium
Xpath in selenium is close to must required. XPath is element locator and you need to provide xpath ...
- xpath定位中starts-with、contains和text()的用法
starts-with 顾名思义,匹配一个属性开始位置的关键字 contains 匹配一个属性值中包含的字符串 text() 匹配的是显示文本信息,此处也可以用来做定位用 eg //input[sta ...
随机推荐
- Java开发中json使用,各对象与json相互转换
Json:一种网络通信使用的数据格式,因为便于解析,比较流行,对象可以转为json,同样json也可以转对象. 下面介绍下Json工具的简单使用(fastjson && jackson ...
- Python全栈学习_day011作业
1,写函数,传入n个数,返回字典{‘max’:最大值,’min’:最小值}例如:min_max(2,5,7,8,4) 返回:{‘max’:8,’min’:2}(此题用到max(),min()内置函数) ...
- 功率因数cosφ仪表盘
一.截图 二.说明 本篇博客主要是有三个亮点: ① 刻度标注在仪表盘标线外 ② 仪表盘存在两个刻度值,分别是(正)0.5~1 和(负)-1~-0.5 ③ 仪表盘内标注,分别是“超前”和“滞后” 三.代 ...
- python中集合-set
集合-set 集合是高中数学中的一个概念 一堆确定的无序的唯一的数据,集合中每一个数据成为一个元素 # 集合的定义 s = set() print(type(s)) print(s) print(&q ...
- npm 走 privoxy 代理经常出现 shasum check failed 的解决办法
今天在下载一个比较大的项目,经常 shasum check failed ,太烦了,于是想切淘宝源,分别尝试 nrm 切换和传递 --registry ,结果都出现 Unexpected end of ...
- 【读书笔记】iOS-应用内购买
Store Kit框架是一个应用内支付引擎.通过这个框架,付费应用可以实现用户付费购买内容的功能(比如为了获取额外的内容) 如果你发现Store Kit框架很难用,而且应用内付款不需要服务器端的支持, ...
- 最全最新的opencv版本下载
opencv和opencv_contrib版本都可以到这个github下载 包括编译好的vc14和vc15window版本 还有源码版,可以自行cmake
- Oracle 常用的查询操作
–1. 查询系统所有对象select owner, object_name, object_type, created, last_ddl_time, timestamp, statusfrom db ...
- CloudSim——云计算仿真软件概述
CloudSim是由澳大利亚墨尔本大学的网格实验室和Gridbus项目宣布推出的云计算仿真软件. CloudSim是做什么的呢?可以简单理解为一个帮助研究.开发.测试的工具,如虚拟机资源分配算法.节能 ...
- 【转】64位系统下无法使用libpam-mysql的md5
转自:http://superwf.dyndns.info/?p=331 Aug 23 09:05:57 wfoffice saslauthd[7235]: pam_mysql – non-crypt ...