UVALive - 6436(DFS)
题目链接:https://vjudge.net/contest/241341#problem/C
题目大意:给你从1到n总共n个数字,同时给你n-1个连接,同时保证任意两个点之间都可以连接。现在假设任意两个点简单连通路过某点则某点的繁荣度+1,求所有点的最大繁荣度。
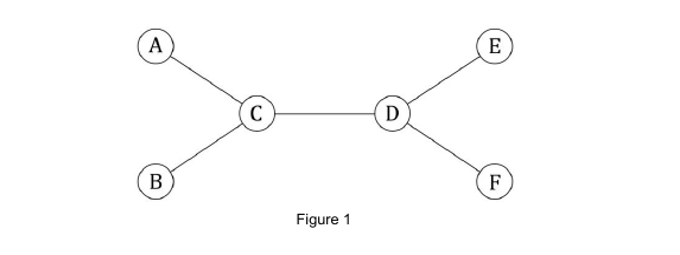
解题思路:以它为例,根据题意,对于C节点我们要计算它的繁荣度,一般大家都会的,肯定就是1*1+1*3+1*3=7;也就是说是以C为根节点的任意两颗子树节点个数的乘积的和,不过这样感觉好像很复杂啊,又要计算以每个节点为根节点的子树节点个数又还要把他们两个两个乘起来再相加,代码不好写不说,而且肯定会超时。
那该怎么做呢,这里需要转换思维了,任意一点的繁荣度应该等于:以它为根节点的每个子树节点个数乘以除这颗子树以及根节点外其它所有节点的和,即子树1*除去子树1和根节点个数+子树2*除去子树2和根节点的节点个数+……,依次类推,不过这样每个都乘了两次,所以算出的结果再除2就行了,这样就简单多了。
代码的实现:把整个图看成以1号节点为根的大树,用一个cnt数组来存储以当前节点个根节点形成的树的节点个数,然后写一个DFS,搜索树的各个子树的节点个数。
具体见代码:
#include<iostream>
#include<vector>
using namespace std;
typedef long long ll;
const int maxn=;
ll n,ans,cnt[maxn];
vector<int> tree[maxn]; //存储边的信息构成一颗树 void DFS(int now,int pre) //now为当前节点,pre为父亲节点
{
cnt[now]=;
ll sum=;
int len=tree[now].size(); //以当前节点为根的树的子树的个数
for(int i=;i<len;i++) //遍历所有子树
{
int x=tree[now][i];
if(x==pre) continue; //不包含父亲节点
DFS(x,now);
cnt[now]+=cnt[x]; //当前节点为根的树的节点总数等于其他所有子树节点的和
sum+=cnt[x]*(n-cnt[x]-); // 子树x与剩余节点数目的乘积
}
sum+=(cnt[now]-)*(n-cnt[now]); //父亲节点所在分支也为now的一个子树,也要加上
ans=max(ans,sum/);
return;
} int main()
{
int t;
cin>>t;
int kase=;
while(t--)
{
cin>>n;
ans=;
for(int i=;i<maxn;i++)
tree[i].clear(); //清空
for(int i=;i<n;i++)
{
int a,b;
cin>>a>>b;
tree[a].push_back(b); //无向图a到b即b到a
tree[b].push_back(a);
}
DFS(,);
printf("Case #%d: %lld\n",kase++,ans);
}
return ;
}
UVALive - 6436(DFS)的更多相关文章
- UVALive - 6436 —(DFS+思维)
题意:n个点连成的生成树(n个点,n-1条边,点与点之间都连通),如果某个点在两点之间的路径上,那这个点的繁荣度就+1,问你在所有点中,最大繁荣度是多少?就比如上面的图中的C点,在A-B,A-D,A- ...
- 训练指南 UVALive - 3713 (2-SAT)
layout: post title: 训练指南 UVALive - 3713 (2-SAT) author: "luowentaoaa" catalog: true mathja ...
- LeetCode Subsets II (DFS)
题意: 给一个集合,有n个可能相同的元素,求出所有的子集(包括空集,但是不能重复). 思路: 看这个就差不多了.LEETCODE SUBSETS (DFS) class Solution { publ ...
- LeetCode Subsets (DFS)
题意: 给一个集合,有n个互不相同的元素,求出所有的子集(包括空集,但是不能重复). 思路: DFS方法:由于集合中的元素是不可能出现相同的,所以不用解决相同的元素而导致重复统计. class Sol ...
- HDU 2553 N皇后问题(dfs)
N皇后问题 Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Description 在 ...
- 深搜(DFS)广搜(BFS)详解
图的深搜与广搜 一.介绍: p { margin-bottom: 0.25cm; direction: ltr; line-height: 120%; text-align: justify; orp ...
- 【算法导论】图的深度优先搜索遍历(DFS)
关于图的存储在上一篇文章中已经讲述,在这里不在赘述.下面我们介绍图的深度优先搜索遍历(DFS). 深度优先搜索遍历实在访问了顶点vi后,访问vi的一个邻接点vj:访问vj之后,又访问vj的一个邻接点, ...
- 深度优先搜索(DFS)与广度优先搜索(BFS)的Java实现
1.基础部分 在图中实现最基本的操作之一就是搜索从一个指定顶点可以到达哪些顶点,比如从武汉出发的高铁可以到达哪些城市,一些城市可以直达,一些城市不能直达.现在有一份全国高铁模拟图,要从某个城市(顶点) ...
- 深度优先搜索(DFS)和广度优先搜索(BFS)
深度优先搜索(DFS) 广度优先搜索(BFS) 1.介绍 广度优先搜索(BFS)是图的另一种遍历方式,与DFS相对,是以广度优先进行搜索.简言之就是先访问图的顶点,然后广度优先访问其邻接点,然后再依次 ...
随机推荐
- Flutter - Json序列化
这个问题,FlutterChina小组已经说明的非常清楚易懂了. 详见https://flutterchina.club/json/
- js类型----你所不知道的JavaScript系列(5)
ECMAScirpt 变量有两种不同的数据类型:基本类型,引用类型.也有其他的叫法,比如原始类型和对象类型等. 1.内置类型 JavaScript 有七种内置类型: • 空值(null) • 未定义( ...
- C#断点续传下载。
断点续传 最近在优化之前的下载流程,仅此篇幅留作笔记之用,日后其他研究此类问题的伙伴可以马上了解原理和开发,减少开发成本. 原理:断点续传目前比较通用的是使用HTTP续传方式,相关的资料可以通过访问: ...
- Centos7部署elasticsearch并且安装ik分词以及插件kibana
第一步 下载对应的安装包 elasticsearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch ik分词下载:https://gith ...
- Linux内核分析——字符集总结与分析
一. 设置修改系统.应用默认字符集 1. 查看虚拟机的字符集: 由此可见,该虚拟机的字符集为zh_CN.UTF-8. 2. 查看服务器支持的编码方式 3. 修改字符集类型 上图可见,LANG字符 ...
- linux第三次实践:ELF文件格式分析
linux第三次实践:ELF文件格式分析 标签(空格分隔): 20135328陈都 一.概述 1.ELF全称Executable and Linkable Format,可执行连接格式,ELF格式的文 ...
- 结构化分析(SA)
1.什么叫模型?我觉得它的关键字:抽象 重要特征 降低复杂度. 2.软件设计的方法 分类:面向功能~,面向对象的设计. 面向数据流的方法是在结构化分析中提到的. 哦~ 3.面向数据流的结构化分析 特点 ...
- 在XShell中使用sz和rz命令下载和上传文件
借助XShell,使用linux命令sz可以很方便的将服务器上的文件下载到本地,使用rz命令则是把本地文件上传到服务器 工具/原料 XShell CentOS 6.5 使用sz下载文件 1 输 ...
- jetty 之 form too large | form too many keys 异常
http://www.jsunw.com/?post=34&tdsourcetag=s_pctim_aiomsg https://wiki.eclipse.org/Jetty/Howto/Co ...
- linux学习之centos(三):mysql数据库的安装和配置
前言:mysql简介 说到数据库,我们大多想到的是关系型数据库,比如mysql.oracle.sqlserver等等,这些数据库软件在windows上安装都非常的方便,在Linux上如果要安装数据库, ...