fcn+caffe+voc2012实验记录
参考博客:
http://blog.csdn.net/haoji007/article/details/77148374
http://blog.csdn.net/jacke121/article/details/78160398
voc数据集下载地址:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/
我习惯于将所有训练、预测有关的.py .prototxt .caffemodel文件放在一起
将score.py surgery.py voc_layers.py拷贝到voc-fcn32s这个文件夹中。
修改solve.py:
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
weights = 'train_iter_100000.caffemodel' #caffe的预训练模型
deploy_proto = 'deploy_voc_32s.prototxt' #deploy文件
# init
caffe.set_device(int(0))
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
vgg_net=caffe.Net(deploy_proto,weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
#加载训练过程中的测试文件
val = np.loadtxt('../data/voc2012/VOCtrainval_11-May-2012/ImageSets/Segmentation/val.txt', dtype=str)
for _ in range(50):
solver.step(2000)
score.seg_tests(solver, False, val, layer='score')
# N.B. metrics on the semantic labels are off b.c. of missing classes;
# score manually from the histogram instead for proper evaluation
#score.seg_tests(solver, False, test, layer='score_sem', gt='sem')
#score.seg_tests(solver, False, test, layer='score_geo', gt='geo')
在../data/voc2012/VOCtrainval_11-May-2012/ImageSets/Segmentation有train.txt val.txt trainval.txt三个文件,num(trainval)=num(train)+num(val)。
预训练的模型可以去官网下载。
编辑solver.prototxt文件:
train_net: "train.prototxt"
test_net: "val.prototxt"
test_iter: 736
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-10
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 20000
snapshot_prefix: "./train"
test_initialization: false
生成deploy.prototxt文件
data层不变,保留
网络层照常理不变
去掉loss层
修改train.prototxt和val.prototxt文件
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "VOCSegDataLayer"
param_str: "{\'voc_dir\': \'../data/voc2012/VOCtrainval_11-May-2012\', \'seed\': 1337, \'split\': \'val\', \'mean\': (104.00699, 116.66877, 122.67892)}"
}
}
module指的是该文件夹下名为voc_layers.py的python文件,layer是该python文件名称为VOCSegDataLayer的类,该python文件中有两个类,另一个类不管。设置voc_dir为对应的路径。Train.prototxt和val.prototxt文件中作相同的修改。
其中的seed=1337,我也不知道是什么意思。这个mean的参数和siftflow中的值倒是一样的。
修改voc_layers.py:
该文件中主要是修改VOCSegDataLayer类中的一些路径和名称,下面的那个SBDDSegDataLayer不管。
设置voc2012数据集的路径
self.voc_dir = params['voc_dir']
加载txt文件
split_f = '{}/ImageSets/Segmentation/{}.txt'.format(self.voc_dir,self.split)
加载图片
im = Image.open('{}/JPEGImages/{}.jpg'.format(self.voc_dir, idx))
加载标签图片
im = Image.open('{}/SegmentationClass/{}.png'.format(self.voc_dir, idx))
voc数据集中的图片尺寸不固定,图片的长宽也不相等。
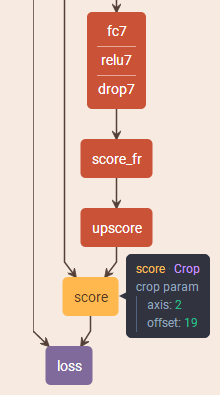
如上图的网络结构可以看到,经过上采样之后,得到一个比原图大的图像,然后做crop操作,生成和原图像一样的尺寸,这就实现了不管输入的图片尺寸是多少,经过全卷积神经网络的结果图片和原图的尺寸都是相同的。
fcn+caffe+voc2012实验记录的更多相关文章
- fcn+caffe+siftflow实验记录
环境搭建: vs2013,编译caffe工程,cuda8.0,cudnn5.1,python2.7. 还需要安装python的一些包.Numpy+mkl scipy matplotlib sci ...
- case7 淋巴瘤子类分类实验记录
case7 淋巴瘤子类分类实验记录 简介 分类问题:3分类 (identifying three sub-types of lymphoma: Chronic Lymphocytic Leukemia ...
- 实验记录:Oracle redo logfile的resize过程
实验记录:Oracle redo logfile的resize过程. 实验环境:RHEL 6.4 + Oracle 11.2.0.3 单实例 文件系统 实验目的:本实验是修改redo logfile的 ...
- 使用Scapy向Mininet交换机注入流量 实验记录
使用Scapy向Mininet交换机注入流量 实验记录 用Python脚本及Scapy库写了一个简单的流量生成脚本,并打算使用该脚本往Mininet中的OpenvSwitch交换机注入流量.拓扑图如下 ...
- 树莓派4B智能小车机器套件——入手组装实验记录
树莓派4B智能小车机器套件--入手组装实验记录 4WD智能小车(4WD SMART ROBOT KIT),支持Arduino.51.STM32.Raspberry Pi等4个版本.本套件采用的是树莓派 ...
- CSAPP:datalab实验记录
CSAPP:datalab实验记录 bitXor /* * bitXor - x^y using only ~ and & * Example: bitXor(4, 5) = 1 * Lega ...
- 实验记录三 通用输入输出(GPIO)
之前把全部程序都跑了一次后,得到了导师下一步的安排. 例如以下: 1.编写一个程序.实如今LCD上显示一个万年历,包含年月日 星期 还有室内的温度.2.编写一个程序,将原来的交通灯改为跑马灯. 期限是 ...
- RHCE实验记录总结-2-RHCE
RHCSA实验总结-点击跳转 RHCE实验 RHCE这边我简单分了下类: ## 网络与安全 1. IPv6 设置(推荐使用GUI程序 nm-connection-editor来完成) 2. team ...
- RHCE实验记录总结-1-RHCSA
不管是运维还是开发系统的了解下Linux或者系统的温习整理一下Linux知识点无疑是较好的,这篇文章是对RHCSA&RHCE实验进行一个汇总,是我为了做实验方便(并分享给朋友)的一篇文章. 前 ...
随机推荐
- 关于vue执行打包后,如何在本地浏览问题
最近一个人在捣鼓vue,写完项目后发现在npm run dev下可以正常访问,bulid之后却一片空白,查看console出现许多Failed to load resource: net::ERR_F ...
- InnoDB中锁的算法(3)
Ⅰ.隐式锁vs显示锁 session1: (root@localhost) [test]> show variables like 'tx_isolation'; +-------------- ...
- asp.net NPOI导出xlsx格式文件,打开文件报“Excel 已完成文件级验证和修复。此工作簿的某些部分可能已被修复或丢弃”
NPOI导出xlsx格式文件,会出现如下情况: 点击“是”: 导出代码如下: /// <summary> /// 将datatable数据写入excel并下载 /// </summa ...
- 20190422 T-SQL 触发器
-- 1 数据库服务 -- 2 触发器 CREATE TRIGGER no_inserton xsAFTER INSERT ASBEGIN RAISERROR('XS不让插入数据',1,1); ROL ...
- ORACLE——count() 统计函数的使用
SQL中用于统计的函数时:COUNT(). 针对count函数的使用做一个记录,很简单. 首先我数据库中建个表TEST,数据如下: 表中ID和NAME都是不重复的数据,HOME.TEL.PATH中存在 ...
- hibernate重要知识点总结
一.使用注解方式-----实体和表之间的映射 配置spring的applicationContext.xml文件: <bean id="sessionFactory" cla ...
- 函数作用域之闭包与this!
函数基础友情链接:http://speakingjs.com/es5/ch01.html#_functions 作用域链图解 var x = 1; function foo(){ var ...
- Windows下安装MySql5.7(解压版本)
Windows下安装MySql5.7(解压版本) 1. 官方地址下载MySql Server 5.7 2. 解压文件到目录d:\Soft\mysql57下 3. 在上面目录下创建文件my.ini,内容 ...
- 擦他丫的,今天在Django项目中引用静态文件jQuery.js 就是引入报错,终于找到原因了!
擦 ,今天在Django项目中引用静态文件jQuery.js 就是引入报错,终于找到原因了! 问题在于我使用的谷歌浏览器,默认使用了缓存,导致每次访问同一个url时,都返回的是缓存里面的东西.通过谷歌 ...
- 2.0JAVA基础复习——JAVA语言的基础组成关键字和标识符
JAVA语言的基础组成有: 1.关键字:被赋予特殊含义的单词. 2.标识符:用来标识的符号. 3.注释:用来注释说明程序的文字. 4.常量和变量:内存存储区域的表示. 5.运算符:程序中用来运算的符号 ...