推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐
一、离线推荐服务
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率。
离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前端业务相应提供数据支撑。
离线推荐服务主要分为统计性算法、基于ALS的协同过滤推荐算法以及基于ElasticSearch的内容推荐算法。
在recommender下新建子项目StatisticsRecommender,pom.xml文件中只需引入spark、scala和mongodb的相关依赖:
离线统计服务
1. 历史热门电影统计
根据所有历史评分数据,计算历史评分次数最多的电影。
实现思路:
通过Spark SQL读取评分数据集,统计所有评分中评分数最多的电影,然后按照从大到小排序,将最终结果写入MongoDB的RateMoreMovies数据集中。
2 最近热门电影统计
根据评分,按月为单位计算最近时间的月份里面评分数最多的电影集合。
实现思路:
通过Spark SQL读取评分数据集,通过UDF函数将评分的数据时间修改为月,然后统计每月电影的评分数。统计完成之后将数据写入到MongoDB的RateMoreRecentlyMovies数据集中。
3 电影平均得分统计
根据历史数据中所有用户对电影的评分,周期性的计算每个电影的平均得分。
实现思路:
通过Spark SQL读取保存在MongDB中的Rating数据集,通过执行以下SQL语句实现对于电影的平均分统计:
4 每个类别优质电影统计
根据提供的所有电影类别,分别计算每种类型的电影集合中评分最高的10个电影。
实现思路:
在计算完整个电影的平均得分之后,将影片集合与电影类型做笛卡尔积,然后过滤掉电影类型不符合的条目,将DataFrame输出到MongoDB的GenresTopMovies集合中。
二、基于隐语义模型的协同过滤推荐
项目采用ALS作为协同过滤算法,分别根据MongoDB中的用户评分表和电影数据集计算用户电影推荐矩阵以及电影相似度矩阵。
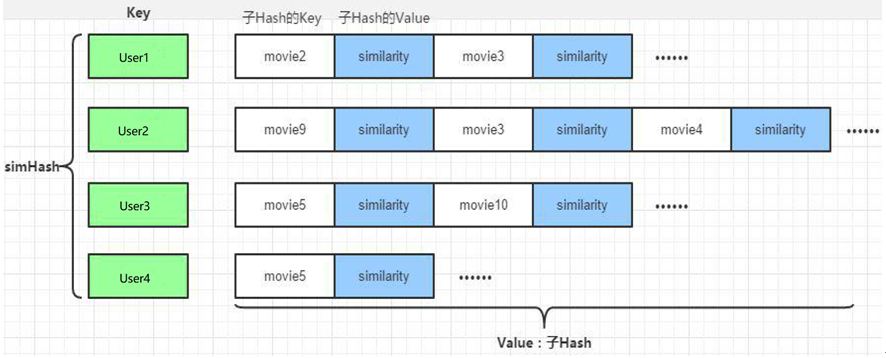
1 用户电影推荐矩阵
通过ALS训练出来的Model来计算所有当前用户电影的推荐矩阵,主要思路如下:
- UserId和MovieID做笛卡尔积,产生(uid,mid)的元组
- 通过模型预测(uid,mid)的元组。
- 将预测结果通过预测分值进行排序。
- 返回分值最大的K个电影,作为当前用户的推荐。
最后生成的数据结构如下:将数据保存到MongoDB的UserRecs表中
新建recommender的子项目OfflineRecommender,引入spark、scala、mongo和jblas的依赖:
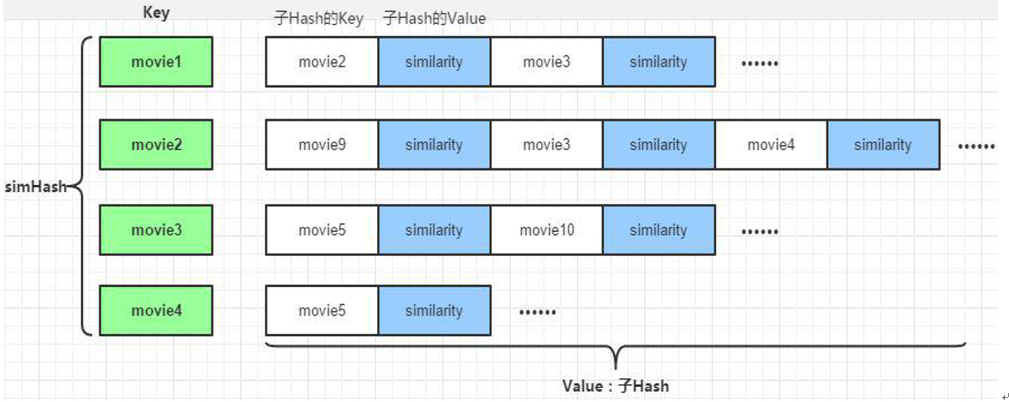
2 电影相似度矩阵
通过ALS计算电影见相似度矩阵,该矩阵用于查询当前电影的相似电影并为实时推荐系统服务。
离线计算的ALS 算法,算法最终会为用户、电影分别生成最终的特征矩阵,分别是表示用户特征矩阵的U(m x k)矩阵,每个用户由 k个特征描述;表示物品特征矩阵的V(n x k)矩阵,每个物品也由 k 个特征描述。
V(n x k)表示物品特征矩阵,每一行是一个 k 维向量,虽然我们并不知道每一个维度的特征意义是什么,但是k 个维度的数学向量表示了该行对应电影的特征。
所以,每个电影用V(n x k)每一行的向量表示其特征,于是任意两个电影 p:特征向量为,电影q:特征向量为之间的相似度sim(p,q)可以使用和的余弦值来表示:
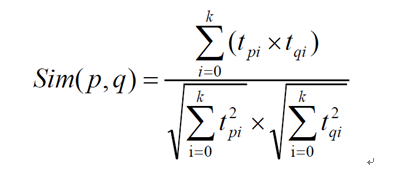
数据集中任意两个电影间相似度都可以由公式计算得到,电影与电影之间的相似度在一段时间内基本是固定值。最后生成的数据保存到MongoDB的MovieRecs表中。
3 模型评估和参数选取
在上述模型训练的过程中,我们直接给定了隐语义模型的rank,iterations,lambda三个参数。对于我们的模型,这并不一定是最优的参数选取,所以我们需要对模型进行评估。通常的做法是计算均方根误差(RMSE),考察预测评分与实际评分之间的误差。
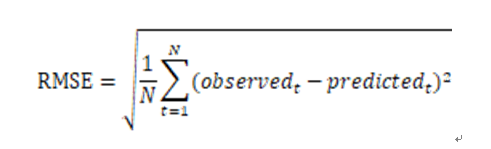
有了RMSE,我们可以就可以通过多次调整参数值,来选取RMSE最小的一组作为我们模型的优化选择。
新建单例对象ALSTrainer,
推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐的更多相关文章
- 推荐系统第5周--- 基于内容的推荐,隐语义模型LFM
基于内容的推荐
- 海量数据挖掘MMDS week4: 推荐系统之隐语义模型latent semantic analysis
http://blog.csdn.net/pipisorry/article/details/49256457 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- Mahout之(二)协同过滤推荐
协同过滤 —— Collaborative Filtering 协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投.拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容 ...
- 【转载】使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 推荐系统之隐语义模型(LFM)
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统之隐语义模型LFM
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统--隐语义模型LFM
主要介绍 隐语义模型 LFM(latent factor model). 隐语义模型最早在文本挖掘领域被提出,用于找到文本的隐含语义,相关名词有 LSI.pLSA.LDA 等.在推荐领域,隐语义模型也 ...
- RS:关于协同过滤,矩阵分解,LFM隐语义模型三者的区别
项亮老师在其所著的<推荐系统实战>中写道: 第2章 利用用户行为数据 2.2.2 用户活跃度和物品流行度的关系 [仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法.学术界对协同过滤算 ...
随机推荐
- 利用Bootstrap搭建网站页面
先来看下页面效果 <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- C# MD5加密字符串
/// <summary> /// 用MD5加密字符串,可选择生成16位或者32位的加密字符串 /// </summary> /// <param name=" ...
- 利用 DFA 算法实现文字过滤
一.DEA 算法简介 在实现文字过滤的算法中,DFA是唯一比较好的实现算法. DFA 全称为:Deterministic Finite Automaton,即确定有穷自动机.其特征为:有一个有限状态集 ...
- HttpRunner学习4--使用正则表达式提取数据
前言 在HttpRunner中,我们可通过extract提取数据,当响应结果为 JSON 结构,可使用 content 结合 . 运算符的方式,如 content.code,用起来十分方便,但如果响应 ...
- UWP 从创建到发布流程一栏
# UWP的产品新建到发布流程一览 1,UWP开发特性 U: Universal(通用) W: Windows P: Plantform(平台) 运行在Windows10设备 比WPF更加多样化和完善 ...
- Android App内文档展示方案整理
一.Word.Excel.PPT 展示 1. 微软Office公开Api接口 如果文档内容不是很机密或者只是需要实现预览文档的话,可以考虑使用微软的公共Api接口实现. 微软Office公开Api地址 ...
- 二维码生成插件qrious
1.qrious是基于canvas的纯JS二维码生成插件 1.1什么是二维码 二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的B ...
- ElasticSearch 安装, 带视频
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 疯狂创客圈 高并 ...
- Newifi-mini OpenWrt 下 EAP-PEAP,EAP-TLS 企业级无线认证及 FreeRadius3
Newifi-mini OpenWrt 下 EAP-PEAP,EAP-TLS 企业级无线认证及 FreeRadius3 转载注明来源: 本文链接 来自osnosn的博客,写于 2019-07-15. ...
- JS reduce()方法详解,使用reduce数组去重
壹 ❀ 引 稍微有了解JavaScript数组API的同学,对于reduce方法至少有过一面之缘,也许是for与forEach太强大,或者filter,find很实用,在实际开发中我至始至终没使用过 ...