使用modelarts部署bert命名实体识别模型
模型部署介绍
当我们通过深度学习完成模型训练后,有时希望能将模型落地于生产,能开发API接口被终端调用,这就涉及了模型的部署工作。Modelarts支持对tensorflow,mxnet,pytorch等模型的部署和在线预测,这里老山介绍下tensorflow的模型部署。
模型部署的工作实际上是将模型预测函数搬到了线上,通常一个典型的模型预测流程如下图所示:

模型部署时,我们需要做的事情如下:
用户的输入输出使用config.json文件来定义;
预处理模块和后处理模块customize_service.py通过复写TfServingBaseService模块的相关函数来实现;
tensorflow模型需要改写成savedModel模型;
tensorflow模型本身作为一个黑盒子,不需关心也无法关心,也就是说你无法在服务启动后对计算图增加节点了。
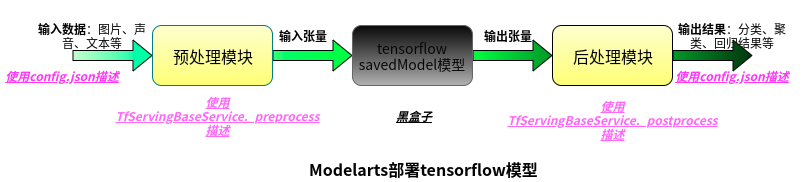
由于模型部署是在模型预测的基础上重新定义的,所以如果模型已经写好了预测的函数,我们就很方便的通过改写程序来进行模型部署工作。
下面便介绍下在modelarts部署bert模型的流程。
savedModel模型生成
本文部署的模型是在华为云 ModelArts-Lab AI实战营第七期的基础上的,请大家重走一遍案例,但务必记得,与案例不同的是,开发环境请选择Tensorflow 1.8,中间有段安装tensorflow 1.11的代码也请跳过。这是因为在本文成文时,modelarts暂时只支持tensorflow 1.8的模型。本章节的所有代码都在modelarts的notebook上完成。
执行完案例后,在./ner/output路径下有训练模型的结果,但这模型还不能直接用于Tensorflow Serving,我们必须先把他转成savedModel模型。
我们先找到./ner/src/terminal_predict.py文件,直接找到预测用的主函数(为了阅读方便,略去了不关注的代码)。
def predict_online():
global graph
with graph.as_default():
# ...bala bala nosense
# ------用户输入
sentence = str(input())
# nosence again
# ------------前处理
sentence = tokenizer.tokenize(sentence)
input_ids, input_mask, segment_ids, label_ids = convert(sentence)
feed_dict = {input_ids_p: input_ids,
input_mask_p: input_mask}
# run session get current feed_dict result
# -------------使用模型(黑盒子)
pred_ids_result = sess.run([pred_ids], feed_dict)
# -------------后处理
pred_label_result = convert_id_to_label(pred_ids_result, id2label)
result = strage_combined_link_org_loc(sentence, pred_label_result[0]) # 输出被这个函数封装了
# something useless在模型使用这块,程序使用了sess这个tf.Session的实例作为全局变量调用,在程序不多的执行代码中,可以看到主要是做了重构模型计算图。
graph = tf.get_default_graph()
with graph.as_default():
print("going to restore checkpoint")
#sess.run(tf.global_variables_initializer())
# -----定义了模型的两个输出张量
input_ids_p = tf.placeholder(tf.int32, [batch_size, max_seq_length], name="input_ids")
input_mask_p = tf.placeholder(tf.int32, [batch_size, max_seq_length], name="input_mask")
bert_config = modeling.BertConfig.from_json_file(os.path.join(bert_dir, 'bert_config.json'))
# ----定义了模型的输出张量,由于后处理只用到pred_ids,其他不管
(total_loss, logits, trans, pred_ids) = create_model(
bert_config=bert_config, is_training=False, input_ids=input_ids_p, input_mask=input_mask_p, segment_ids=None,
labels=None, num_labels=num_labels, use_one_hot_embeddings=False, dropout_rate=1.0)
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint(model_dir))既然sess在可执行代码中帮我们构建好了,我们源代码一行不动,直接引用就可以生成savedModel模型
from ner.src.terminal_predict import *
export_path = './model'
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# 将输入张量与名称挂钩
signature_inputs = {
'input_ids': tf.saved_model.utils.build_tensor_info(input_ids_p),
'input_mask': tf.saved_model.utils.build_tensor_info(input_mask_p),
}
# 将输出张量与名称挂钩
signature_outputs = {
'pred_ids':tf.saved_model.utils.build_tensor_info(pred_ids),
}
# 签名定义?不懂就往下看输出结果
classification_signature_def = tf.saved_model.signature_def_utils.build_signature_def(
inputs=signature_inputs,
outputs=signature_outputs,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
builder.add_meta_graph_and_variables(
sess,
[tf.saved_model.tag_constants.SERVING],
signature_def_map={
'root': classification_signature_def
},
)
builder.save()这样就在export_path路径下生成了savedModel模型,模型文件如下
model
├── saved_model.pb
├── variables
│ ├── variables.index
│ └── variables.data-00000-of-00001生成模型后我们可以进行预测,来判断模型是否正确
首先我们输出signature_def
sess = tf.Session()
meta_graph_def = tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.SERVING], export_dir)
signature = meta_graph_def.signature_def
signature['root']signature_def:
inputs {
key: "input_ids"
value {
name: "input_ids:0"
dtype: DT_INT32
tensor_shape {
dim {
size: 1
}
dim {
size: 128
}
}
}
}
inputs {
key: "input_mask"
value {
name: "input_mask:0"
dtype: DT_INT32
tensor_shape {
dim {
size: 1
}
dim {
size: 128
}
}
}
}
outputs {
key: "pred_ids"
value {
name: "ReverseSequence_1:0"
dtype: DT_INT32
tensor_shape {
dim {
size: 1
}
dim {
size: 128
}
}
}
}
method_name: "tensorflow/serving/predict"可见这个签名定义了模型的输入输出格式的信息。由于模型上线封装后,无法获取具体节点张量,所以输入输出就用节点的名称来替代,也就是里面的key值。
接下来,我们写个预测函数,来看看结果
# 直接照抄
def convert(line):
feature = convert_single_example(0, line, label_list, max_seq_length, tokenizer, 'p')
input_ids = np.reshape([feature.input_ids],(batch_size, max_seq_length))
input_mask = np.reshape([feature.input_mask],(batch_size, max_seq_length))
segment_ids = np.reshape([feature.segment_ids],(batch_size, max_seq_length))
label_ids =np.reshape([feature.label_ids],(batch_size, max_seq_length))
return input_ids, input_mask, segment_ids, label_ids
# 基本照抄,改变了输出,变成dict
def strage_combined_link_org_loc_2(tokens, tags):
def print_output(data, type):
line = []
for i in data:
line.append(i.word)
return [i.word for i in data]
params = None
eval = Result(params)
if len(tokens) > len(tags):
tokens = tokens[:len(tags)]
person, loc, org = eval.get_result(tokens, tags)
return {'LOC': print_output(loc, 'LOC'),
'PER': print_output(person, 'PER'),
'ORG': print_output(org, 'ORG'),}
# 线下调用模型的函数,得自己写,不过测试完就扔掉了
def predict(f1, f2):
x1_tensor_name = signature['root'].inputs['input_ids'].name
x2_tensor_name = signature['root'].inputs['input_mask'].name
y1_tensor_name = signature['root'].outputs['pred_ids'].name
x1 = sess.graph.get_tensor_by_name(x1_tensor_name)
x2 = sess.graph.get_tensor_by_name(x2_tensor_name)
y1 = sess.graph.get_tensor_by_name(y1_tensor_name)
y1 = sess.run(y1, feed_dict={x1:f1,x2:f2})
return y1
# 输入
sentence = '中国男篮与委内瑞拉队在北京五棵松体育馆展开小组赛最后一场比赛的争夺,赵继伟12分4助攻3抢断、易建联11分8篮板、周琦8分7篮板2盖帽。'
# 前处理
input_ids, input_mask, segment_ids, label_ids = convert(sentence)
# 调用模型
y1 = predict(input_ids, input_mask)
# 后处理
pred_label_result = convert_id_to_label([y1], id2label)
result = strage_combined_link_org_loc_2(sentence, pred_label_result[0])
# 输出
resultout:
{'LOC': ['北京五棵松体育馆'], 'ORG': ['中国男篮', '委内瑞拉队'], 'PER': ['赵继伟', '易建联', '周琦']}以上就线下预测的模块。线上预测大体类似,但仍还需要少量的代码更改,以及无用的代码块剔除。
config.json文件生成
config.json编写可查看规范,其中apis中以json scheme定义了用户输入输出方式,也是最头疼的地方。老山看来,apis部分描述的作用大于对程序的实际影响,如果你本身熟悉程序的输入方式,完全可以定义最外层即可,无须对内部仔细定义。dependencies模块除非需要特定版本或是真的用了些不常见的工程,否则可以不写。
config.json
{
"model_algorithm": "bert_ner",
"model_type": "TensorFlow",
"runtime": "python3.6",
"apis": [
{
"procotol": "http",
"url": "/",
"method": "post",
"request": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"sentence": {
"type": "string"
}
}
}
},
"response": {
"Content-type": "applicaton/json",
"data": {
"type": "object",
"properties": {
}
}
}
}
]
}这里规范了输入必须是{"sentence":"需要输入的句子"}这么个格式。
customize_service.py生成
这个模块定义了预处理和后处理,重要性不可谓不重要。同样可以找到规范,这个也是你会花费最多时间去反复修改的程序。这里老山讲一下几点经验,方便大家参考:
程序通过新建TfServingBaseService的子类来重写_preprocess和_postprocess函数;
如果是.py文件,正常引用便是;如果是其他文件,在类内通过self.model_path获得路径;
如果用后处理后需要用到前处理的变量,把该变量变成类的属性(现在因为都是同步的,如果以后加入异步功能,这样简单的处理方法有可能会引起线程安全问题);
引用其他.py文件时,命名请尽量刁钻,如(utils.py -> utils_.py, config.py -> config_.py),避免和服务本身的模块重名;
程序尽量剪枝,一些无关程序就删除把;
customize_service.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import os
import numpy as np
import json
from model_service.tfserving_model_service import TfServingBaseService
import tokenization
from utils_ import convert_, convert_id_to_label, strage_combined_link_org_loc
from config_ import do_lower_case, id2label
class BertPredictService(TfServingBaseService):
def _preprocess(self, data):
tokenizer = tokenization.FullTokenizer(
vocab_file=os.path.join(self.model_path, 'vocab.txt'), do_lower_case=do_lower_case)
sentence = data['sentence']
# 把sentence保存在类中,方便后处理时调用
self.sentence = sentence
input_ids, input_mask, *_ = convert_(sentence, tokenizer)
feed = {'input_ids': input_ids.astype(np.int32),
'input_mask': input_mask.astype(np.int32)}
print("feed:", feed)
return feed
def _postprocess(self, data):
pred_ids = data['pred_ids']
pred_label_result = convert_id_to_label([pred_ids], id2label)
result = strage_combined_link_org_loc(self.sentence, pred_label_result[0])
return result这里引用了bert自带的tokenization模块,config_模块里面都是些常量,utils_模块基本就是把terminal_predict.py里的模型相关的全删除掉,改吧改吧弄出来的,这里不再赘述了。
模型存储
在部署之前,必须安装规范存储在obs中,这次老山存储的目录如下。
obs-name
└── ocr
└── model
├── config.json
├── config_.py
├── customize_service.py
├── saved_model.pb
├── tokenization.py
├── utils_.py
├── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── vocab.txt导入模型
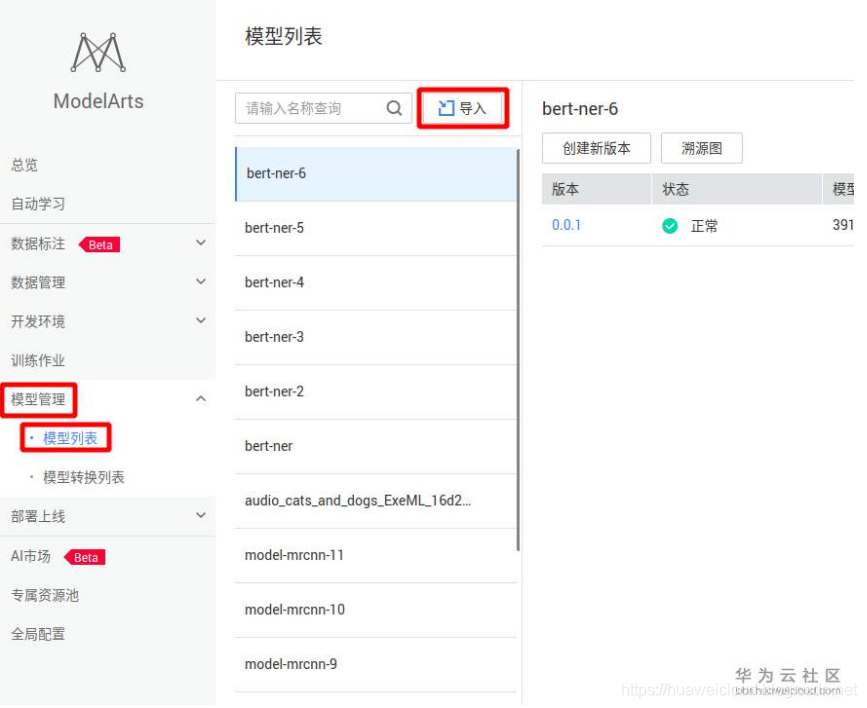
在modelarts控制台上左侧导航栏选择模型管理 -> 模型列表,在中间的模型列表中选择导入
在导入模型页面上,修改名称,在元模型来源选择从OBS中选择,选择元模型的路径后,点击立刻创建。
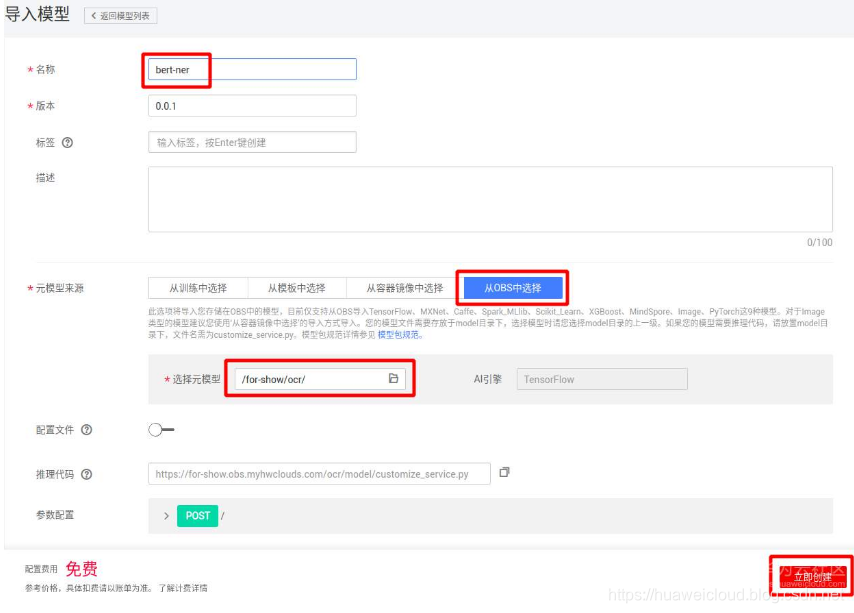
返回模型列表,等待模型状态变成正常
模型部署和预测
在模型列表中选择创建的模型,选择部署
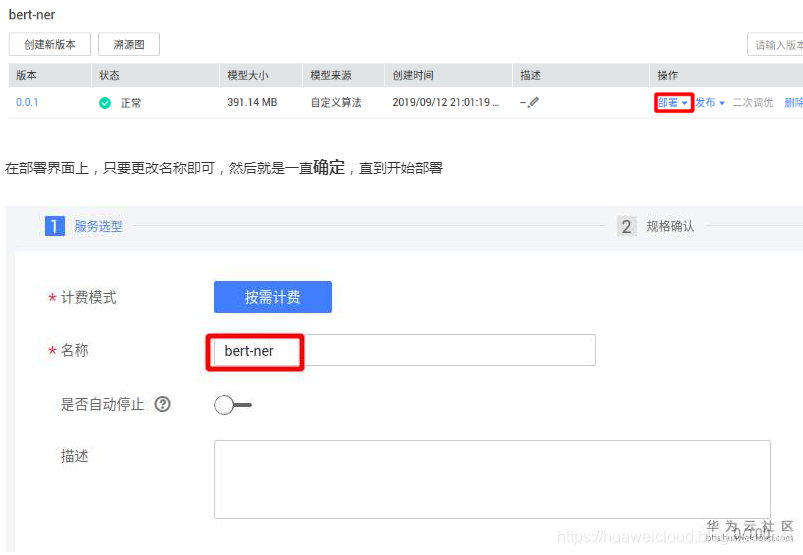
部署会需要2-3分钟不等的时间,等待部署成功后,点击服务的名称,进入在线服务的页面

在线服务页面选择预测标签栏,输入预测代码:{"sentence":"中国男篮与委内瑞拉队在北京五棵松体育馆展开小组赛最后一场比赛的争夺,赵继伟12分4助攻3抢断、易建联11分8篮板、周琦8分7篮板2盖帽。"},点击预测,在返回结果处可以看到结果与之前模型测试结果相同。

API调用
在调用指南标签页中给出了服务的API接口地址
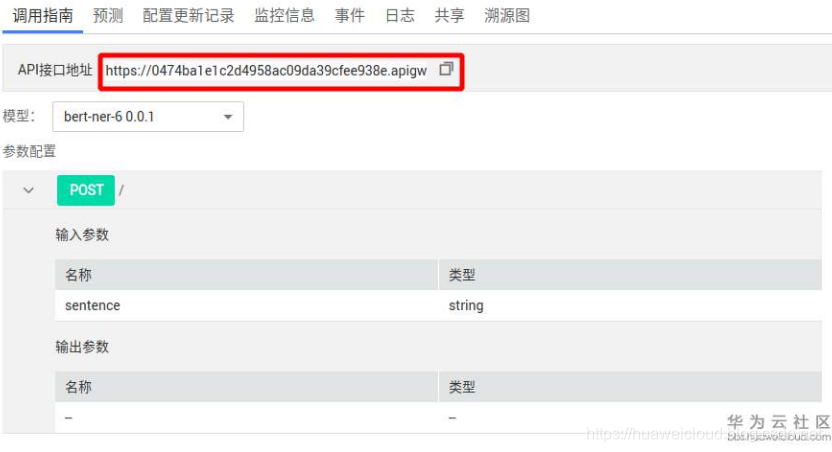
官方文档介绍了如何使用Postman和curl调用API接口,大家自行查阅,老山这个给出的是如何使用python来调用API。
首先是选择认证方式。一个是AK/SK认证,也就是每次调用都直接使用AK/SK来请求,无疑要对AK/SK进行加密,这意味着基本上不折腾的方式就是使用官方的模块。另外一种是X-Auth-Token认证,有时效,每次使用X-Auth-Token调用请求即可,但在获取X-Auth-Token时请求结构体中要明文方式输入账户和密码,安全性上还值得商榷。但这里自然是选用第二种方法,相对灵活些。
首先是请求X-Auth-Token
import requests
import json
url = "https://iam.cn-north-1.myhuaweicloud.com/v3/auth/tokens"
headers = {"Content-Type":"application/json"}
data = {
"auth": {
"identity": {
"methods": ["password"],
"password": {
"user": {
"name": "your-username", # 账户
"password": "your-password", # 密码
"domain": {
"name": "your-domainname:normally equal to your-username" #域账户,普通账户这里就还是填账户
}
}
}
},
"scope": {
"project": {
"name": "cn-north-1"
}
}
}
}
data = json.dumps(data)
r = requests.post(url, data = data, headers = headers)
print(r.headers['X-Subject-Token'])data具体参数基本上就是账号和密码,具体细节可参考官网。
程序最后获得的便是X-Auth-Token认证码。获得认证码后便可进行预测了。
config.py
X_Auth_Token = "MIIZpAYJKoZIhvcNAQcCoIIZlTCC..." # 前面获取的X-Auth-Token值
url = "https://39ae62200d7f439eaae44c7cabccf5de.apig..." #在调用指南页面获取的url值predict.py
import requests
from config import url, X_Auth_Token
import json
def bertService(sentence):
data = {"sentence":sentence}
data = json.dumps(data)
headers = {"content-type": "application/json", 'X-Auth-Token': X_Auth_Token}
response = requests.request("POST", url, data = data, headers=headers)
return response.text
if __name__ == "__main__":
print(bertService('中国男篮与委内瑞拉队在北京五棵松体育馆展开小组赛最后一场比赛的争夺,赵继伟12分4助攻3抢断、易建联11分8篮板、周琦8分7篮板2盖帽。'))输出结果:
{"LOC": ["北京五棵松体育馆"], "PER": ["赵继伟", "易建联", "周琦"], "ORG": ["中国男篮", "委内瑞拉队"]}关闭服务
当不需要使用服务时,请点击在线服务页面右上角的停止,以避免产生不必要的费用。
作者:山找海味
使用modelarts部署bert命名实体识别模型的更多相关文章
- 通俗理解BiLSTM-CRF命名实体识别模型中的CRF层
虽然网上的文章对BiLSTM-CRF模型介绍的文章有很多,但是一般对CRF层的解读比较少. 于是决定,写一系列专门用来解读BiLSTM-CRF模型中的CRF层的文章. 我是用英文写的,发表在了gith ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- 抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔 论文名称: Template-free Prompt Tuning for Few-shot NER 文献链接: https://arxiv.org/abs/2109.13532 ...
- 命名实体识别,使用pyltp提取文本中的地址
首先安装pyltp pytlp项目首页 单例类(第一次调用时加载模型) class Singleton(object): def __new__(cls, *args, **kwargs): if n ...
- 『深度应用』NLP命名实体识别(NER)开源实战教程
近几年来,基于神经网络的深度学习方法在计算机视觉.语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展.在NLP的关键性基础任务—命名实体识别(Named Entity Recogni ...
- 使用哈工大LTP进行文本命名实体识别并保存到txt
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/broccoli2/article/det ...
- 用深度学习做命名实体识别(六)-BERT介绍
什么是BERT? BERT,全称是Bidirectional Encoder Representations from Transformers.可以理解为一种以Transformers为主要框架的双 ...
- 基于bert的命名实体识别,pytorch实现,支持中文/英文【源学计划】
声明:为了帮助初学者快速入门和上手,开始源学计划,即通过源代码进行学习.该计划收取少量费用,提供有质量保证的源码,以及详细的使用说明. 第一个项目是基于bert的命名实体识别(name entity ...
- HMM(隐马尔科夫模型)与分词、词性标注、命名实体识别
转载自 http://www.cnblogs.com/skyme/p/4651331.html HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型,举一个经典的例子:一个东京的朋友每天根据天气{ ...
随机推荐
- EffectiveJava-2
一.使用类库 使用类库的好处: 无须关心方法是如何实现的,由算法专家花了大量时间设计.实现和测试这个方法,不仅保证了正确性,而且一旦有缺陷,下一个版本就会修复. 不必浪费时间为哪些与工作不太相关的问题 ...
- vue ui九宫格、底部导航、新闻列表、跨域访问
一. 九宫格 九宫格:在mint-ui组件库基于vue框架 mui不是基于vue框架 只是css/js文件 (1)官方网站下载安装包 (2)copy css js fonts[字体图标] src/l ...
- Docker(二) Dockerfile 使用介绍
前言 图解Docker 镜像.容器和 Dockerfile 的关系: 一.Dockerfile的概念 Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序.库.资源.配置等文件外,还包 ...
- 在控制器中如何对frxml的控件初始化
如果在控制器中实现Initializable这个接口,并重iInitializable这个方法 对于一个fxml文件来说它首先执行控制器的构造函数,这个时候它是无法对@FXML修饰的方法进行访问的,然 ...
- Mybatis 关联对象不能输出的解决办法
Mybatis 关联对象不能输出的解决办法 1.如图所示,现在进行查询的时候并没有得到来自另一张表address项 2.我们进行如下配置: (1).在mybatis-config.xml 文件中配置, ...
- 2019CSP day1t2 括号树
题目背景 本题中合法括号串的定义如下: () 是合法括号串. 如果 A 是合法括号串,则 (A) 是合法括号串. 如果 A,B 是合法括号串,则 AB 是合法括号串. 本题中子串与不同的子串的定义如下 ...
- Ubuntu 16.04 安装Docker
1 更改apt源,更改前先对sources.list文件进行备分 ccskun@test:~$ sudo cp /etc/apt/sources.list /etc/apt/sources.list. ...
- git、git-lab学习记录
git: 定义:分布式版本控制工具,类似SVN,区别在于SVN如果网络断了,无法进行版本控制,而git是本地进行版本控制,不多bb了,来个图吧 git常用命令: git add 文件 ...
- 接口测试之-postman
在使用postman进行接口测试的时候,对于有些接口字段需要时间戳加密,这个时候我们就遇到2个问题,其一是接口中的时间戳如何得到?其二就是对于现在常用的md5加密操作如何在postman中使用代码实现 ...
- Python 函数知识点整理