python机器学习——使用scikit-learn训练感知机模型
这一篇我们将开始使用scikit-learn的API来实现模型并进行训练,这个包大大方便了我们的学习过程,其中包含了对常用算法的实现,并进行高度优化,以及含有数据预处理、调参和模型评估的很多方法。
我们来看一个之前看过的实例,不过这次我们使用sklearn来训练一个感知器模型,数据集还是Iris,使用其中两维度的特征,样本数据使用三个类别的全部150个样本
%matplotlib inline
import numpy as np
from sklearn import datasetsiris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.targetnp.unique(y)array([0, 1, 2])为了评估训练好的模型对新数据的预测能力,我们这里将Iris数据集分为训练集和测试集,这里我们通过调用trian_test_split方法来将数据集分为两部分,其中测试集占30%,训练集占70%
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)我们再将特征进行缩放操作,这里调用StandardScaler来对特征进行标准化:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)新对象sc使用fit方法对数据集中每一维的特征计算出样本平均值和标准差,然后调用transform方法对数据集进行标准化,我们这里使用相同的标准化参数对待训练集和测试集。接下来我们训练一个感知器模型
from sklearn.linear_model import Perceptronppn = Perceptron(max_iter=40, eta0=0.1, random_state=0)ppn.fit(X_train_std, y_train)
Perceptron(alpha=0.0001, class_weight=None, early_stopping=False, eta0=0.1,
fit_intercept=True, max_iter=40, n_iter_no_change=5, n_jobs=None,
penalty=None, random_state=0, shuffle=True, tol=0.001,
validation_fraction=0.1, verbose=0, warm_start=False)y_pred = ppn.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_pred).sum())
Misclassified samples: 5可以看出测试集中有5个样本被分错类了,因此错误分类率是0.11,则分类准确率为1-0.11=0.89,我们也可以直接计算分类准确率:
from sklearn.metrics import accuracy_score
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
Accuracy: 0.89最后我们画出分界区域,这里我们将plot_decision_regions函数进行一些修改,使我们可以区分训练集和测试集的样本
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, slpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot all samples
X_test, y_test = X[test_idx, :], y[test_idx]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8,
c=cmap(idx), marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='',alpha=1.0,
linewidth=1, marker='o', s=55, label='test set')
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined, classifier=ppn,
test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
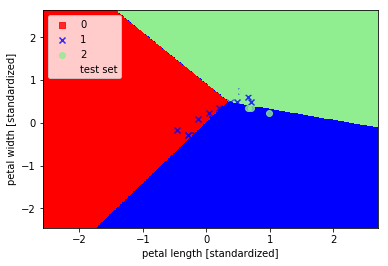
可以看出三个类别并没有被完美分类,这是由于这三类花并不是线性可分的数据。
python机器学习——使用scikit-learn训练感知机模型的更多相关文章
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 使用SKlearn(Sci-Kit Learn)进行SVR模型学习
今天了解到sklearn这个库,简直太酷炫,一行代码完成机器学习. 贴一个自动生成数据,SVR进行数据拟合的代码,附带网格搜索(GridSearch, 帮助你选择合适的参数)以及模型保存.读取以及结果 ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
随机推荐
- Linux学习资料网站汇总链接(持续更新ing)
排名不分先后. 学海无涯苦作舟. 博客: 1.slmba:LINUX博客原创大牛 2.edsionte's TechBlog:Linuxer (他的友情链接中还有一堆Linuxer,被公司屏蔽进不去. ...
- npm install bcrypt报错
gyp ERR! stack Error: Can't find Python executable "python", you can set the PYTHON env va ...
- PHP array_udiff_uassoc
1.函数的参数:返回数组的差集.用定义的函数比较键值和值. 2.函数的参数: @params array $array @params array $array1 ... @params callab ...
- DP题 总结 [更新中]
建设中 ... 预防针 : 本蒟蒻代码风格清奇(⊙﹏⊙)b 一.选学霸 题目描述 老师想从N名学生中选M人当学霸,但有K对人实力相当,如果实力相当的人中,一部分被选上,另一部分没有,同学们就会抗议.所 ...
- 基于canvas实现钟表
原理说明 1.通过arc方法实现钟表外环: 2.通过line实现钟表时针,分针,秒针和刻度标志的绘制,基于save和restore方法旋转画布绘制不同角度的指针: 3.通过font方法实现在画布上绘制 ...
- python类中的self
class User: def walk(self): print(self,"正在慢慢走") # User.walk() # 会报错 TypeError: walk() miss ...
- 罕见的coredump了
最近,项目在越南版删档测试的时候,发生了罕见的coredump,简单记一点排查日志 目前的敏感词过滤是在C层做判定的,先后经过几个项目考验,模块算是比较稳定了.越南版有个需求,需要将敏感词里的空格去掉 ...
- day10整理(面对对象,过程,类和对象)
目录 一 回顾 (一)定义函数 (二)定义函数的三种形式 1.空函数 2.有参函数 3.无参函数 (三)函数的返回值 (四)函数的参数 1.形参 2.实参 二 面向过程编程 三 面向对象过程 四 类和 ...
- Sqoop的安装和验证
Sqoop是一个用来完成Hadoop和关系型数据库中的数据相互转移的工具,它可以将关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中. Kafka是一个开源 ...
- python *args,**kwargs参数
实际上,关键的是*和** 我们以三个例子来解释: 普通的使用参数: def test1(arg): print(arg) test1("a") 输出: a *是将剩下的参数用元祖表 ...