爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息
爬取源代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
import re
import pandas as pd
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') lilist=[] r=requests.get('https://www.parenting.com/baby-names/boys/earl')
soup=BeautifulSoup(r.text,"lxml")
soup= soup.find_all('a',href=True)
for i in soup:
if 'https://www.parenting.com/pregnancy/baby-names/baby-boy-names/' in str(i)or'https://www.parenting.com/pregnancy/baby-names/girl-baby-names/' in str(i):
lilist.append(i.get("href"))
lilist1=[]
results1=[]
results=[]
results2=[] for i in list(set(lilist)):
r=requests.get(i)
soup=BeautifulSoup(r.text,"lxml") Source=soup.find_all('p')
Source=soup.find_all(attrs={'class': 'description'}) results0 = re.findall('<h4>(.*?)</h4>', r.text)
for c in results0:
if c!='':
lilist1.append(c)
#print(lilist1)
#lilist1=[]
pattern = re.compile('<p><strong>Origin:</strong>\s(.*?)</p>', re.S)
results += re.findall(pattern, str(Source)) pattern1 = re.compile('<p><strong>Meaning:</strong>\s(.*?)</p>', re.S)
results1 += re.findall(pattern1, str(Source))
pattern2 = re.compile("<p><strong>Why it’s big:</strong>\s(.*?)</p>", re.S)
results2 += re.findall(pattern2, str(Source)) print(lilist1)
print(results1)
print(results)
print(results2)
data = {
'EnName':lilist1,
'Meaning':results1,
'Origin':results,
'Description':results2
}
frame = pd.DataFrame(data)
frame.to_csv('wt10.csv',encoding="gb18030")
#print(results2)
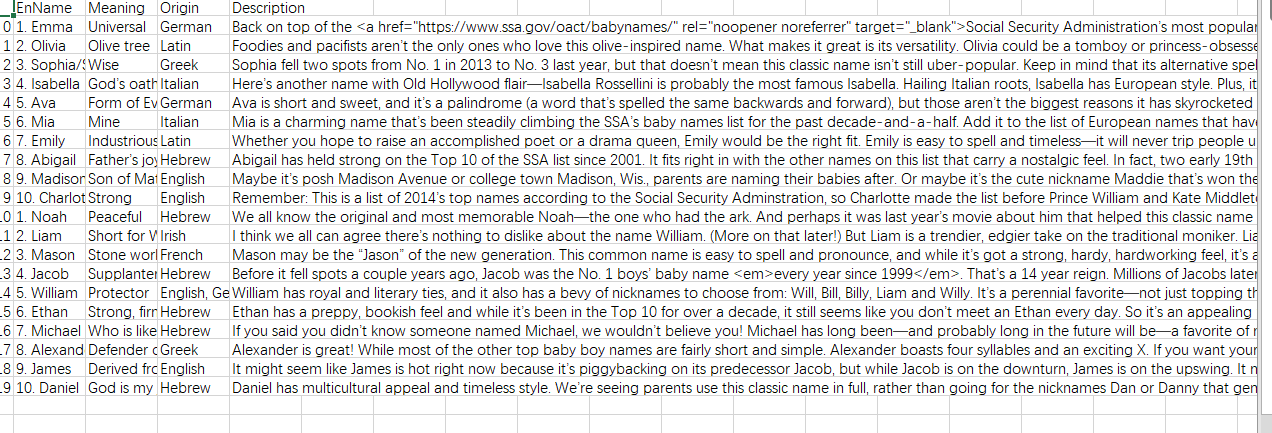
爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息的更多相关文章
- 一个爬取https和http通用的工具类(JDK自带的URL的用法)
今天在java爬取天猫的时候因为ssl报错,所以从网上找了一个可以爬取https和http通用的工具类.但是有的时候此工具类爬到的数据不全,此处不得不说python爬虫很厉害. package cn. ...
- 解决:Python爬取https站点时SNIMissingWarning和InsecurePlatformWarning
今天想利用Requests库爬取糗事百科站点,写了一个请求,却报错了: 后来参考kinsomy的博客,在cmd中pip install pyopenssl ndg-httpsclient pyasn1 ...
- 爬取https页面遇到“SSLError: hostname 'xxx' doesn't match either of”的解决方法
使用python requests 框架包访问https://itunes.apple.com 页面是遇到 SSLError: hostname 'itunes.apple.com' doesn't ...
- java爬虫爬取https协议的网站时,SSL报错, java.lang.IllegalArgumentException TSLv1.2 报错
目前在广州一家小公司实习,这里的学习环境还是挺好的,今天公司从业十几年的大佬让我检查一下几年前的爬虫程序是否还能使用…… 我从myeclipse上check out了大佬的程序,放到workspace ...
- pyspider爬取tourism management 所有文章的标题 作者 摘要 关键词等等所有你想要的信息
#!/usr/bin/env python # -*- encoding: utf-8 -*- # vim: set et sw=4 ts=4 sts=4 ff=unix fenc=utf8: # C ...
- python爬取酒店信息练习
爬取酒店信息,首先知道要用到那些库.本次使用request库区获取网页,使用bs4来解析网页,使用selenium来进行模拟浏览. 本次要爬取的美团网的蚌埠酒店信息及其评价.爬取的网址为“http:/ ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
随机推荐
- Kylin的安装及遇到的问题
************************************************************************************************ 首先, ...
- Android View 的添加绘制流程 (二)
概述 上一篇 Android DecorView 与 Activity 绑定原理分析 分析了在调用 setContentView 之后,DecorView 是如何与 activity 关联在一起的,最 ...
- .NET Core开发的iNeuOS工业互联网平台,发布 iNeuDA 数据分析展示组件,快捷开发图形报表和数据大屏
目 录 1. 概述... 2 2. 演示信息... 2 3. 简单介绍... 3 4. 产品特点... 4 5. 价值体现... 5 1. ...
- 实战webpack系列说明
01.概念股 本质上,webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler). 当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(d ...
- windows下python IDE安装注意事项&Python安装及编辑器UliPad安装
python下载地址: http://www.python.org/download/releases/2.7.6/ 我自己用的是ulipad ,但是注意 ulipad和python的版本一定要配 ...
- 修改json源码支持datetime序列化
修改json源码支持datetime序列化 import json import datetime now = datetime.datetime.today() json.dumps(now) 抛出 ...
- Python Kite 使用教程 轻量级代码提示
1: 概述 今天升级annacoda 插件 spyder (4.0.0 )的时候 提示安装kite ,这是什么玩意? 下载下来试一试? 原来:就是一个代码提示插件.. 说白了" 就是让开发 ...
- 用.NET解索尼相机ARW格式照片
用.NET解索尼相机ARW格式照片 目前常用的照片格式是.jpg,它只能提供8bit的色彩深度,而目前主流的相机都能提供高达12bit-14bit的色彩深度,动态范围和后期处理能力也大大增加,这也是为 ...
- css练习——两列左窄右kuan型
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 在华为云ECS上手工通过Docker部署tomcat
本文介绍了如何在华为云上ECS上手工通过Docker部署tomcat,并提供了Docker常用操作 一.环境准备 ECS:操作系统版本: CentOS Linux release 7.6.181 ...