C++标准库(体系结构与内核分析)(侯捷第一讲)
一、C++标准库介绍
C++标准库:C++ Standard Library
C++标准库与STL有什么关系:
STL:Standard Template Library
STL包含6大部件,基本占标准库的80%左右内容,而另外20%是一些好用的零碎的东西,所以说C++标准库包含STL。
- 编译器一定带着一个C++标准库,是以头文件(header files)的形式提供的,并不是编译好的文件,而是源代码。
- C++标准库的头文件不带扩展名(.h),例如#include <vector>。
- 对于C语言的标准库,新式的C语言标准库头文件也去除了扩展名(.h),例如#include <cstdio>。
- 对于某些编译器,旧式的头文件也可以使用,例如#include <stdio.h>。
- 新式头文件内的组件都封装在命名空间(namespace)std中,例如using namespace std;
常用写法:
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <functional>
//打开std命名空间
using namespace std;
二、STL六大部件(video2)
STL的六大部件分别是:
- 容器:Containers
- 分配器:Allocator
- 算法:Algorithms
- 迭代器:Iterator
- 适配器:Adapters
- 仿函数:Functors
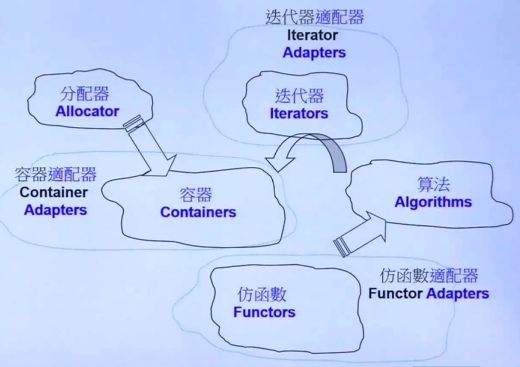
其中容器和算法是最重要的两大部件。以前有句老话叫做“数据结构加算法就等于程序”,在这句话中,容器就是数据结构,是一个优秀的团队将常用的数据结构都在STL中实现了。同样的,常用算法也在STL算法部件中实现。所以掌握了C++标准库的时候,可以避免重复造轮子的问题,而且库中提供的功能都经过无数次的优化,性能有很好的保证。
六大部件简要介绍:
容器:容器是一堆常用数据结构的实现,主要用户存放和读取数据,屏蔽了底层的内存分配和释放的问题,所以能够让用户更方便和高效的使用。
分配器:容器对数据结构的封装,要处理内存分配和释放的问题,就用到了分配器。
算法:既然容器用来存取数据,相当于一个数据的仓库,那么算法就是用来处理这些数据的工具。在STL中,算法和容器是分开设计的,这和面向对象(OO)有点不符,在面向对象中,我们一般将数据和方法封装在一个类中,而在STL中,使用的是模板式编程,是另外一条路线。
迭代器:我们的算法要操作容器中的数据。如何将两者结合起来,就需要一个桥梁,这个桥梁就是迭代器。迭代器可以看成是一种泛化的指针。
仿函数:比较抽象,后面解释。
适配器:用于做一些转换,例如容器适配器、仿函数适配器、迭代器适配器。
三、六大部件示例(video2)

上图中程序解释:(其中将六大部件综合在一起展示)
1.在第11行,定义一个容器vector,模板参数为<int, allocator<int>>,其中第一个int代表vector要装的数据类型,后面的allocator<int>是一个内存分配器,用于vector的内存分配。这个分配器是一个可选项,如果不写,标准库源码中有一个默认的分配器给vector,分配器也是一个模板,模板参数必须和容器的第一模板参数匹配,这里是int。
2.定义vector变量vi,构造函数选用的是将数组ia的第一个位置和最后一个位置作为参数。
3.在第13行,选用了一个叫做count_if()的算法来处理容器vi。这个算法的作用是对vi中满足一定条件的元素进行计数。
4.count_if()的参数分别是指向容器开头的迭代器(泛化指针)、指向容器结尾的迭代器以及对元素的过滤条件。vi.begin()返回的是指向开头的迭代器,vi.end()返回的是指向结尾的迭代器。
5.less<int>()是一个仿函数,用于比较大小。
6.bind2nd(less<int>(), 40)是一个适配器,意思是将第二个参数也就是整数40,绑定到less<int>()。意思就是小于40的整数。
7.not1()函数也是一个适配器,意思是取反义,也就是将小于40,变为大于等于40。
8.最后的输出就是vi中大于等于40的元素的个数,结果为4。
四、算法效率介绍(video2)
每个人都想用效率最高的东西和方法,那位什么标准库还要提供十个八个容器和一大堆算法呢?
因为每个人的需求不同,例如数据分布、数据排列方式、数据处理需求都不一样。没有一个特定的容器或算法能够适应所有的需求。所以我们必须根据不同的需求来选择不同的容器和算法。
如何评价容器或算法的效率,我们经常会使用复杂度(Complexity)或O()(big-oh)来衡量。
主要的复杂度有以下一些:
1.O(1)或O(c):常数时间(constant time)
2.O(n):线性时间(linear time)
3.O(log2n):以2为底n的对数,次线性时间(sub-linear time)
4.O(n2):n的平方,平方时间(quadratic time)
5.O(n3):n的立方,立方时间(cubic time)
6.O(2n):2的n次方,指数时间(exponential time)
7.O(nlog2n):介于线性与平方的中间模式。
这里面的n必须是一个很大的数(几十万甚至更大)才有实际的意义,因为当n很大时,各个复杂度之间的效率千差万别。而如果n很小,例如一些玩具程序,那对于计算机的计算速度,效率之间差距就没什么意义了。
五、区间表示法(video2)
我们对一个范围的表示一般有三种方式:
1.[ ]:闭区间,即包含最前和最后的元素。
2.( ):开区间,即最前最后元素都不包含。
3.[ ):前闭后开区间,即包含最前面的元素,不包含最后面的元素。
在C++标准库中,选择第3种作为区间表示,也就是前闭后开。

如上图所示,c是一个容器对象,c.begin()返回一个迭代器(泛化指针,兼容指针几乎所有操作),这个迭代器指向容器的第一个元素的地址。c.end()也返回一个迭代器,这个迭代器指向容器最后一个元素的下一个地址,但是那个地址所保存的东西,根本不是这个容器所拥有的。所以,使用*(c.end())所取到的数据是没有意义的(并且可能导致程序崩溃)。
上图中展示了如何使用迭代器和for循环来遍历容器中的元素。代码如下:
int arr[] = { ,,,,,,,,, };
//定义容器,将数组arr的数据放入容器中
vector<int> vi(arr, arr + );
//获取容器开头的迭代器
vector<int>::iterator bg = vi.begin(); //可以使用auto bg = vi.begin()
//当bg不等于vi.end()时,也就是说还有滑到容器的最后,打印bg指向的数据,并滑向下一个位置
for (; bg != vi.end(); bg++) {
cout << *bg << endl;
}
另一种遍历的做法(C++11新特性):(参照笔记:C++程序设计2里的第十四节 基于range的for循环)
int arr[] = { ,,,,,,,,, };
//定义容器,将数组arr的数据放入容器中
vector<int> vi(arr, arr + );
//使用auto可以让编译器自己推导类型,当然也可以写for(int i : vi){}
for (auto i : vi) {
cout << i << endl;
}
六、容器结构与分类(video3)
容器分为两类:
1.序列式容器:Sequence Container
2.关联式容器:Associative Container,其中又可以分为有序的和无序的(Unordered Container)。
序列式容器,Sequence Containers:

Array:C++2.0才加入的容器,是对语言自带原始数组的类封装,大小不能扩展。一般初始化时有大小限制(根据机器和内存大小的不同),注意异常。
Vector:大小可以扩展的数组,当容量不够时,Vector里的分配器会自动进行内存的扩展,可以放心使用。
Deque:双向队列,念做/dek/。前后都可以扩展容量,可以从两段放入数据,也可从两段取数据。Queue是单向队列,由Deque封装出来的,所有有些人也不把queue看做容器,而是看成容器适配器。
List:标准库中的List是双向环状链表。
Forward-List:C++2.0加入的容器,单向链表。(占用空间肯定比List小,应为每个node都少一个指向前面node的指针)
关系式容器,Assiociative Containers:
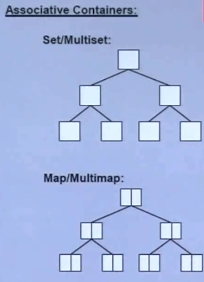
包含set和map。虽然标准库没有规定用什么样的数据结构来实现,但各家的编译器都默认采用了红黑树(RB-Tree)来实现,因为红黑树是一种特殊的二叉树,这种二叉树又叫做高度平衡二叉树,意思是会自动调整左右臂的元素数量,使得不会出现最坏查找(即刚好遇到需要查找的元素处于最深的那条臂)。
set:set中的元素没有key,查找元素的时候直接用value进行查找,因为在set中,key就是value,value就是key。
map:map中元素的key和value是一一对应的,查找元素时用key作为查找的条件。
Multiset:set中元素可以重复。
Multimap:map中元素可以重复。
无序容器,Unordered Containers:
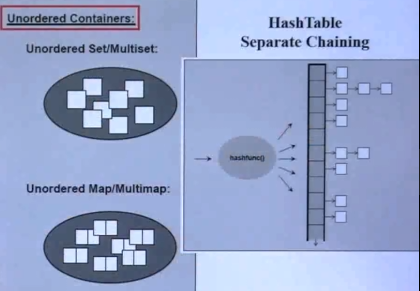
Unordered set和map的底层是通过哈希表(HashTable)来实现的。对于各家编译器来说,都默认采用了公认最好的Separate Chaining哈希表,即图中右侧的结构。
U set:通过Hash算法将value映射到某个单元格对应的链表,并存放在其中。
U map:通过Hash算法将key映射到某个单元格对应的链表,并存放其中。
注意:hash表中的每一个格子对应的链表不能太长,因为链表查找元素的效率是比较低的,所以在设计set和map的时候应该使用一些规则来限制对应链表的长度。
七、Array容器示例(video4)
namespace zz1 {
//用于对比两个类型为Long的数,该函数提供给C标准库函数qsort用于快速排序
int compareLongs(const void* a, const void* b) {
return (*(long *)a - *(long*)b);
}
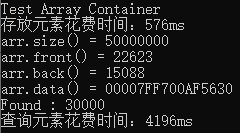
void use_array() {
cout << "Test Array Container" << endl;
//使用static是为了避免在局部内存区域分配大小过大,程序不运行
static array<long, MAX_NUM> arr;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入arr
for (auto& i : arr) {
i = rand();
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "arr.size() = "<<arr.size() << endl;
//打印第一个元素
cout << "arr.front() = " << arr.front() << endl;
//打印最后一个元素
cout << "arr.back() = " << arr.back() << endl;
//打印数据开头的指针,可以用来使用指针遍历数据
cout << "arr.data() = " << arr.data() << endl;
//从数组中找一个元素
start_time = clock();
qsort(arr.data(), MAX_NUM, sizeof(long), compareLongs);
//查找的目标数为30000
long target = ;
//使用二分查找
long* pItem = (long *)bsearch(&target, arr.data(), MAX_NUM, sizeof(long), compareLongs);
if (pItem != NULL) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
注意:当Array定义时长度总大小超过0x7fffffff时,报错:

运行输出:
八、Vector容器示例(video4)
namespace zz2 {
void use_vector() {
cout << "Test Vector Container" << endl;
//使用static是为了避免在局部内存区域分配大小过大,程序不运行
static vector<long> vec;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入vec
for (size_t i = ; i < MAX_NUM; i++) {
try {
vec.push_back(rand());
}
catch (exception& p) {
//看最大能存放多少数据,内存不足以分配,异常为std::bad_alloc
cout << "when i = " << i << ",error : " << p.what() << endl;
//出错,使用abort终止程序
abort();
}
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "arr.size() = " << vec.size() << endl;
//打印第一个元素
cout << "arr.front() = " << vec.front() << endl;
//打印最后一个元素
cout << "arr.back() = " << vec.back() << endl;
//打印数据开头的指针,可以用来使用指针遍历数据
cout << "arr.data() = " << vec.data() << endl;
//返回分配器分配的空间大小,一定大于目前数据占用的空间
cout << "arr.capacity() = " << vec.capacity() << endl;
//查找一个元素(使用find算法,循序查找,看运气)
long target = ;
start_time = clock();
auto pItem = ::find(vec.begin(), vec.end(), target);
if (pItem != vec.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "find查询元素花费时间:" << clock() - start_time << "ms" << endl;
//查找一个元素(使用排序+二分查找)
start_time = clock();
//先排序
sort(vec.begin(), vec.end());
cout << "排序花费时间:" << clock() - start_time << "ms" << endl;
//使用二分查找
long target2 = ;
start_time = clock();
long* pItem2 = (long *)bsearch(&target2, vec.data(), vec.size(), sizeof(long) ,compareLongs);
if (pItem2 != NULL) {
cout << "Found : " << *pItem2 << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "bsearch查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
在上述代码中,往vector中放入数据,使用push_back()方法。每次数据都从最后加入容器,为什么不能从前面push呢,因为vector是一个只能从尾巴扩张空间的容器,如果要从前面push,那就势必每次都将已存在的时候全部往后面挪动,这是相当花时间的事情。
运行结果:
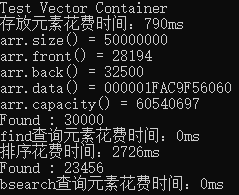
从结果中可以看出,使用顺序查找(O(n)),当运气不错时,可以很快找到需要的数据。但是使用二分查找必须先进行排序,排序消耗了2726ms,相当耗时,而二分查找(O(log2n))确实是很快的。
当MAX_NUM很大时,运行到中途抛出异常(内存不足):

在vector中,空间分配是以2倍进行的,例如初始状态空间为0,存入第一个数据,空间分配为1,存入第二个数据,空间分配为2,存入第三个数据,空间分配为4,存入第5个数据,空间分配为8,存入第9个数据,空间分配为16,以此类推。所以vec.capacity(总容量)始终大于vec.size()。
如何扩张的:
当空间不足时,分配器要进行多一倍空间的扩展,但是不可能在原本的空间后面扩展一倍。那么,只能找一个是原来空间2倍的新的空间,然后将原本的数据全部复制过去。所以,空间的扩展也是比较消耗性能的。
九、List容器示例(video5)
namespace zz3 {
void use_list() {
cout << "Test List Container" << endl;
list<long> lst;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入lst
for (long i = ; i < MAX_NUM; i++) {
lst.push_back(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "arr.size() = "<<lst.size() << endl;
//打印第一个元素
cout << "arr.front() = " << lst.front() << endl;
//打印最后一个元素
cout << "arr.back() = " << lst.back() << endl;
//双向链表竟然有一个max_size,按理说应该根据内存大小可以无限扩展(后面研究)
cout << "arr.max_size() = " << lst.max_size() << endl;
//从链表中找一个元素
start_time = clock();
long target = ;
auto pItem = ::find(lst.begin(), lst.end(), target);
if (pItem != lst.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
//对链表进行排序
start_time = clock();
lst.sort();
cout << "排序花费时间:" << clock() - start_time << "ms" << endl;
}
}
运行结果:
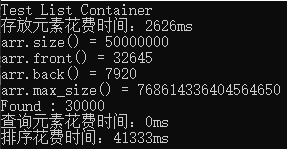
从结果中可以看出,链表存放数据以及排序是很慢的,而且排序还使用了链表自己提供的sort,而不是全局的sort。如果一个容器自己提供了sort,那么说明这个sort效率高于全局的sort,尽量选择自己提供的算法。
十、Forward-List容器示例(video5)
namespace zz4 {
void use_flist() {
cout << "Test Forward-List Container" << endl;
forward_list<long> flst;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入arr
for (long i = ; i < MAX_NUM; i++) {
flst.push_front(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小(单向链表没有这个方法)
//cout << "flst.size() = " << flst.size() << endl;
//打印第一个元素
cout << "flst.front() = " << flst.front() << endl;
//打印最后一个元素(单向链表没有这个方法)
//cout << "flst.back() = " << flst.back() << endl;
//单向链表竟然有一个max_size,按理说应该根据内存大小可以无限扩展(后面研究)
cout << "flst.max_size() = " << flst.max_size() << endl;
//从链表中找一个元素
start_time = clock();
long target = ;
auto pItem = ::find(flst.begin(), flst.end(), target);
if (pItem != flst.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
//对链表进行排序
start_time = clock();
flst.sort();
cout << "排序花费时间:" << clock() - start_time << "ms" << endl;
}
}
单向链表和双向链表相似,但单向链表没有size()和back()方法,并且插入数据只有使用push_front(),也就是只能从一端插入。
运行结果:
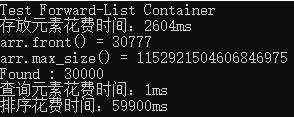
十一、deque容器示例(video5)
deque是双向队列,前后都可以扩充。我们知道一个内存要扩充,是没办法在原地扩充的,像vector在尾巴上扩充,也是另外找一个2倍大的空间,整体移动过去。而deque是怎么做到双向扩充的呢?如下图所示:
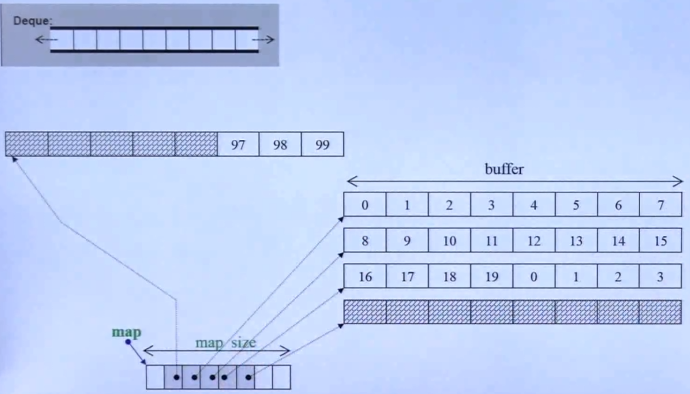
deque由一个map和若干个buffer组成,map中保存的是每个buffer的指针,一个buffer可以存放多个元素。当从最后插入元素,刚好遇到最后那个buffer的空间用完,则会在后面另外申请一个buffer,新的buffer的头指针存放在map的最后一格中。从前面插入也是同样的道理。
namespace zz5 {
void use_deque() {
cout << "Test Deque Container" << endl;
deque<long> dq;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入dq
for (long i = ; i < MAX_NUM; i++) {
dq.push_back(rand());
//dq.push_front(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "dq.size() = " << dq.size() << endl;
//打印第一个元素
cout << "dq.front() = " << dq.front() << endl;
//打印最后一个元素(单向链表没有这个方法)
cout << "dq.back() = " << dq.back() << endl;
//双向队列竟然有一个max_size,按理说应该根据内存大小可以无限扩展(后面研究)
cout << "dq.max_size() = " << dq.max_size() << endl;
//从双向队列中找一个元素
start_time = clock();
long target = ;
auto pItem = ::find(dq.begin(), dq.end(), target);
if (pItem != dq.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
//对双向队列进行排序
start_time = clock();
::sort(dq.begin(),dq.end());
cout << "排序花费时间:" << clock() - start_time << "ms" << endl;
}
}
双向队列没有自己的sort()方法,只能调用全局的sort方法。
运行结果:
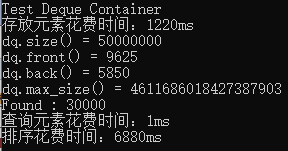
从结果可以看出,双向队列的max_size非常大,排序比较慢。
十二、stack容器示例(video5)
stack是一个先进后出的容器,和下一节要说到的queue(单向队列)相反。但是和queue都是deque的一种特殊形态。如图:
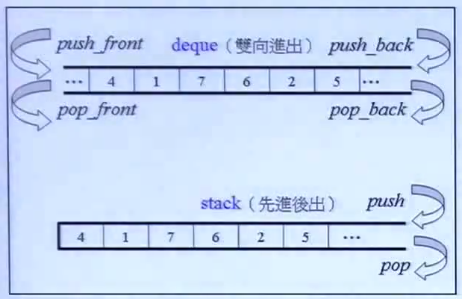
当一个deque永远都只从其中一端放数据和取数据,他就变成了一个stack。所以stack只提供了一个放元素的函数,叫push()。
namespace zz6 {
void use_stack() {
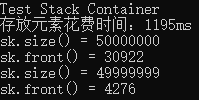
cout << "Test Stack Container" << endl;
stack<long> sk;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入sk
for (long i = ; i < MAX_NUM; i++) {
sk.push(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "sk.size() = " << sk.size() << endl;
//打印最顶上的元素
cout << "sk.top() = " << sk.top() << endl;
//取出一个元素
sk.pop();
//再次打印总大小
cout << "sk.size() = " << sk.size() << endl;
//再次打印最顶上的元素
cout << "sk.top() = " << sk.top() << endl;
}
}
运行结果:
十三、queue容器示例(video5)
queue和stack类似,但是取数据的方向和stack不一样,queue是先进先出,是单向队列。deque的特殊情况。
namespace zz7 {
void use_queue() {
cout << "Test Queue Container" << endl;
queue<long> qu;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入qu
for (long i = ; i < MAX_NUM; i++) {
qu.push(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "qu.size() = " << qu.size() << endl;
//打印最前面的元素
cout << "qu.front() = " << qu.front() << endl;
//打印最后面的元素
cout << "qu.back() = " << qu.back() << endl;
//取出一个元素
qu.pop();
//再次打印总大小
cout << "qu.size() = " << qu.size() << endl;
//打印最前面的元素
cout << "qu.front() = " << qu.front() << endl;
//打印最后面的元素
cout << "qu.back() = " << qu.back() << endl;
}
}
运行结果:
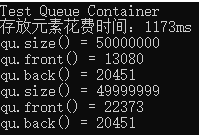
从结果中可以看出,当pop出一个元素后,queue的front数据变了,但back的没变。
十四、stack和queue说明(video5)
说明:stack和queue是以deque双向队列为底层来实现的,所以很多人不把stack和queue当成真正的容器,而是将其看做一种容器的适配器。
他们一个是先进先出,一个先进后出,所以并没有提供iterator,所以也不会使用find算法去查找数据。
十五、multiset容器示例(video6)
set和multiset是一种关系式容器,底层是红黑树(RB-Tree)。所以他的元素天生就是有序的,并且每个元素插入的位置都是有规律可循的,所以这个容器放入数据是比较慢的,但因为其底层是平衡二叉树结果,他的查询数据是非常快的。set和multiset的区别在于能够放入相同的元素。这里采用multiset来示范放入100W个元素(肯定有重复)。
namespace zz8 {
void use_multiset() {
cout << "Test Multiset Container" << endl;
multiset<long> mset;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个数,放入mset
for (long i = ; i < MAX_NUM; i++) {
mset.insert(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "mset.size() = " << mset.size() << endl;
//Multiset竟然有一个max_size,按理说应该根据内存大小可以无限扩展(后面研究)
cout << "mset.max_size() = " << mset.max_size() << endl;
//从链表中找一个元素(用全局find)
start_time = clock();
long target = ;
auto pItem = ::find(mset.begin(), mset.end(), target);
if (pItem != mset.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
//从链表中找另一个元素(用自身提供的find)
start_time = clock();
long target2 = ;
auto pItem2 = mset.find(target2);
if (pItem2 != mset.end()) {
cout << "Found : " << *pItem2 << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
运行结果:
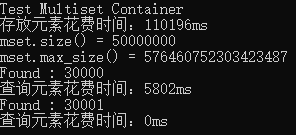
从结果可看出,multiset的插入速度相当慢,因为每次插入都要通过排序找准数据放置在树中的位置。使用全局::find()查找数据也比较慢,所以他自己提供了一个find()算法,结果可以看出,速度相当快。
十六、multimap容器示例(video6)
multimap和multiset的区别在于,里面存的数据是key-value对,key作为索引用于查找。在multiset中,只有value,所以查找时将value当成key来用。但在multimap中就将其分开了。
namespace zz9 {
void use_multimap() {
cout << "Test Multimap Container" << endl;
multimap<long,long> mmap;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个键值对,放入mmap
for (long i = ; i < MAX_NUM; i++) {
//将i作为key,不会重复
mmap.insert(pair<long,long>(i,rand()));
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "mmap.size() = " << mmap.size() << endl;
//Multiset竟然有一个max_size,按理说应该根据内存大小可以无限扩展(后面研究)
cout << "mmap.max_size() = " << mmap.max_size() << endl;
//从链表中找一个元素(用自身提供的find)
start_time = clock();
long target = ;
auto pItem = mmap.find(target);
if (pItem != mmap.end()) {
cout << "Found : key = " << (*pItem).first<<" value = "<<(*pItem).second << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
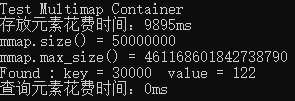
在multimap中,查找元素是通过key来查找的。
运行结果:
十七、Unordered multiset容器示例(video6)
namespace zz10 {
void use_unorder_multiset() {
cout << "Test Unorder Multiset Container" << endl;
//头文件#include <unordered_set>
unordered_multiset<long> umset;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个键值对,放入umset
for (long i = ; i < MAX_NUM; i++) {
umset.insert(rand());
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "umset.size() = " << umset.size() << endl;
cout << "umset.max_size() = " << umset.max_size() << endl;
cout << "umset.bucket_count() = " << umset.bucket_count() << endl;
cout << "umset.load_factor() = " << umset.load_factor() << endl;
cout << "umset.max_load_factor() = " << umset.max_load_factor() << endl;
cout << "umset.max_bucket_count() = " << umset.max_bucket_count() << endl;
//从链表中找一个元素(用自身全局find)
start_time = clock();
long target = ;
auto pItem = ::find(umset.begin(),umset.end(),target);
if (pItem != umset.end()) {
cout << "Found : " << *pItem << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
//从链表中再找一个元素(用自身提供的find)
start_time = clock();
long target2 = ;
auto pItem2 = umset.find(target2);
if (pItem2 != umset.end()) {
cout << "Found : " << *pItem2 << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
运行结果:
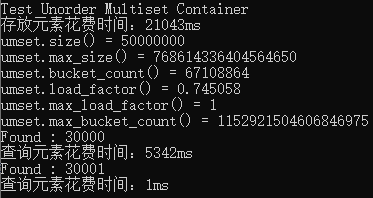
从结果可以看出,bucket_count 大于size,原因如下述。负荷系数 load_factor = size / bucket_count。
Unordered Multiset是使用hash映射+链表作为底层数据结构的。hash算法先将数据映射到不同的bucket,每个bucket保存的是一个链表的头指针。当一个bucket中有多个元素时(即链表有多个node,每个node保存一个元素),那么会使用顺序查找的方式来遍历链表,所以链表一定不能太长,否者会影响查询效率。
如何让每个bucket下挂的链表不至于太长呢,可以使用大于数据量的bucket数量来解决,当数据增加到等于bucket数量时,Unordered multiset会自动扩展bucket数量(两倍数量),并将数据打散重新hash到不同的bucket下挂链表中。这样,就以空间换取了时间复杂度的提升。
十八、Unordered multimap容器示例(video6)
namespace zz11 {
void use_unorder_multimap() {
cout << "Test Unorder Multiset Container" << endl;
//头文件#include <unordered_map>
unordered_multimap<long,long> ummap;
//产生随机种子seed
srand(time());
//记录开始时间戳
clock_t start_time = clock();
//随机产生MAX_NUM个键值对,放入ummap
for ( long i = ; i < MAX_NUM; i++) {
ummap.insert(pair<long,long>(i,rand()));
}
//打印消耗时间
cout << "存放元素花费时间:" << clock() - start_time << "ms" << endl;
//打印总大小
cout << "ummap.size() = " << ummap.size() << endl;
cout << "ummap.max_size() = " << ummap.max_size() << endl;
//从链表中找一个元素(用自身提供的find)
start_time = clock();
long target = ;
auto pItem = ummap.find(target);
if (pItem != ummap.end()) {
cout << "Found : key = " << (*pItem).first << " value = " << (*pItem).second << endl;
}
else {
cout << "Not found." << endl;
}
//打印花费时间
cout << "查询元素花费时间:" << clock() - start_time << "ms" << endl;
}
}
运行结果:
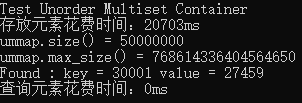
Unordered multimap和前面一节的Unordered multiset差不多,只是存的数据使用key-value对。
十九、Set、Map、Unordered set、Unordered map(video6)
这四个容器和前面4节所描述的multiset、multimap、unordered multiset和unordered multimap差不多,唯一的差别就是这四个容器存放的数据的key不能重复。
对于set和map来说,key就是value,value就是key,那么key不能重复的意思就是value不能重复。
而对于unordered set和unordered map来说,就是存放数据的key不能重复,而value是可以重复的。
在四种map中(map、multimap、unordered map、unordered multimap),map和unordered map是可以使用“[]”的方式取值的,例如:
map<long,long> m;
m[] = ;
m[] = ;
unordered_map<long, long> um;
um[] = ;
um[] = ; cout << m[] << endl;
cout << m[] << endl;
cout << um[] << endl;
cout << um[] << endl;
因为在map和unordered map中,key不能重复。所以,一个key一定能够唯一表示一个value。那么这个key可以作为index来取值。
而在multimap和unordered multimap中,key可以重复。所以,可能存在多个key一致的问题,那么使用key作为index就存在问题。
二十、一些非标容器(video6)
存在一些在C++1.0中未纳入标准库的容器:
slist
hash_set
hash_map
hash_multiset
hash_multimap
这些在C++1.0未纳入标准库,可能是因为时间的问题,但是由于他们很重要,各家编译器都将他们实现了。
在C++2.0中这些都已经被纳入标准库,只是名字做了修改。
二十一、分配器(video7)
在GNU C++编译器下测试多个allocator效率:
导入头文件:
#include <list>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <algorithm> //find()
#include <iostream>
#include <ctime> #include <cstddef>
#include <memory> //內含 std::allocator
//欲使用 std::allocator 以外的 allocator, 得自行 #include <ext\...>
//以下allocator只能在GNUC g++中使用
#ifdef __GNUC__
#include <ext\array_allocator.h>
#include <ext\mt_allocator.h>
#include <ext\debug_allocator.h>
#include <ext\pool_allocator.h>
#include <ext\bitmap_allocator.h>
#include <ext\malloc_allocator.h>
#include <ext\new_allocator.h>
#endif
namespace zz12 {
void use_allocator() {
cout << "Test Allocators" << endl;
list<long, allocator<long>> c1;
list<long, __gnu_cxx::malloc_allocator<long>> c2;
list<long, __gnu_cxx::new_allocator<long>> c3;
list<long, __gnu_cxx::__pool_alloc<long>> c4;
list<long, __gnu_cxx::__mt_alloc<long>> c5;
list<long, __gnu_cxx::bitmap_allocator<long>> c6;
srand(time());
clock_t timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i){
c1.push_back(rand());
}
cout << "allocator花费时间:" << clock() - timeStart << "ms" << endl;
timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i) {
c2.push_back(rand());
}
cout << "malloc_allocator花费时间:" << clock() - timeStart << "ms" << endl;
timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i) {
c3.push_back(rand());
}
cout << "new_allocator花费时间:" << clock() - timeStart << "ms" << endl;
timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i) {
c4.push_back(rand());
}
cout << "__pool_alloc花费时间:" << clock() - timeStart << "ms" << endl;
timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i) {
c5.push_back(rand());
}
cout << "__mt_alloc花费时间:" << clock() - timeStart << "ms" << endl;
timeStart = clock();
for (long i = ; i < MAX_LOOP; ++i) {
c6.push_back(rand());
}
cout << "bitmap_allocator花费时间:" << clock() - timeStart << "ms" << endl;
}
}
二十二、直接使用分配器(video7)
在GNU C++编译器下测试直接使用不同的allocator分配空间以及deallocator归还空间:
namespace zz13 {
void use_allocator_directly(){
//test all allocators' allocate() & deallocate();
int* p;
allocator<int> alloc1;
p = alloc1.allocate();
alloc1.deallocate(p, );
__gnu_cxx::malloc_allocator<int> alloc2;
p = alloc2.allocate();
alloc2.deallocate(p, );
__gnu_cxx::new_allocator<int> alloc3;
p = alloc3.allocate();
alloc3.deallocate(p, );
__gnu_cxx::__pool_alloc<int> alloc4;
p = alloc4.allocate(); //分配2个int变量的空间
alloc4.deallocate(p, ); //归还2个int变量的空间
__gnu_cxx::__mt_alloc<int> alloc5;
p = alloc5.allocate();
alloc5.deallocate(p, );
__gnu_cxx::bitmap_allocator<int> alloc6;
p = alloc6.allocate(); //分配3个int变量的空间
alloc6.deallocate(p, ); //归还3个
}
}
不建议直接使用allocator,建议直接使用标准容器。如果需要分配小空间内存,那么建议使用熟悉的new、delete和malloc、free,因为这几个函数只需要关心分配的大小,而不用关心归还的大小,更方便,不容易出错。
C++标准库(体系结构与内核分析)(侯捷第一讲)的更多相关文章
- C++标准库(体系结构与内核分析)(侯捷第二讲)
一.OOP和GP的区别(video7) OOP:面向对象编程(Object-Oriented programming) GP:泛化编程(Generic programming) 对于OOP来说,我们要 ...
- 《Linux内核分析》课程第一周学习总结
姓名:何伟钦 学号:20135223 ( *原创作品转载请注明出处*) ( 学习课程:<Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- 侯捷STL学习(四)--OOP-GP/操作符重载-泛化特化
C++标准库第二讲 体系结构与内核分析 第1-7节为第一讲 读源代码前的准备 第八节:源代码分布 C++基本语法 模板的使用 数据结构和算法 本课程主要使用:Gnu C 2.9.1与Gun C 4.9 ...
- UNIX环境高级编程——标准I/O库缓冲区和内核缓冲区的区别
1.C标准库的I/O缓冲区 UNIX的传统 是Everything is a file,键盘.显示器.串口.磁盘等设备在/dev 目录下都有一个特殊的设备文件与之对应,这些设备文件也可 ...
- C 标准库IO缓冲区和内核缓冲区的区别
1.C标准库的I/O缓冲区 UNIX的传统 是Everything is a file,键盘.显示器.串口.磁盘等设备在/dev 目录下都有一个特殊的设备文件与之对应,这些设备文件也 ...
- C++ 异常机制分析(C++标准库定义了12种异常,很多大公司的C++编码规范也是明确禁止使用异常的,如google、Qt)
阅读目录 C++异常机制概述 throw 关键字 异常对象 catch 关键字 栈展开.RAII 异常机制与构造函数 异常机制与析构函数 noexcept修饰符与noexcept操作符 异常处理的性能 ...
- C++标准库分析总结(三)——<迭代器设计原则>
本节主要总结迭代器的设计原则,以及iterstor traits的设计作用 1.迭代器遵循的原则 迭代器是算法和容器的桥梁,它是类模板的设计,迭代器必须有能力回答算法提出的问题才能去搭配该算法的使用 ...
- STM32 标准库V3.5启动文件startup_stm32f10xxx.s分析
layout: post tags: [STM32] comments: true 文章目录 layout: post tags: [STM32] comments: true 前言 分析startu ...
- golang标准库分析之net/rpc
net/rpc是golang提供的一个实现rpc的标准库.
随机推荐
- B 维背包+完全背包 Hdu2159
<span style="color:#3333ff;">/* ---------------------------------------------------- ...
- 熵、交叉熵、相对熵(KL 散度)意义及其关系
熵:H(p)=−∑xp(x)logp(x) 交叉熵:H(p,q)=−∑xp(x)logq(x) 相对熵:KL(p∥q)=−∑xp(x)logq(x)p(x) 相对熵(relative entropy) ...
- wpf 实现实时毛玻璃(live blur)效果
原文:wpf 实现实时毛玻璃(live blur)效果 I2OS7发布后,就被它的时实模糊吸引了,就想着能不能将这个效果引入到我们的产品上.拿来当mask肯定会很爽,其实在之前也做过类似的,但是不是实 ...
- MFC中获取App,MainFrame,Doc和View类等指针的方法
From: http://hi.baidu.com/wxnxs/item/156a68f5b3b4ed18e3e3bd03 MFC中获取App,MainFrame,Doc和View类等指针的方法 ...
- Expression Blend学习5控件
原文:Expression Blend学习5控件 Expression Blend ButtonStyle- TextButton 本章以TextButton为例,讲解如何最简单,最快速的制作一个专业 ...
- Win8 Metro(C#)数字图像处理--2.59 P分位法图像二值化
原文:Win8 Metro(C#)数字图像处理--2.59 P分位法图像二值化 [函数名称] P分位法图像二值化 [算法说明] 所谓P分位法图像分割,就是在知道图像中目标所占的比率Rat ...
- C# 设置IP地址及设置自动获取IP
原文:C# 设置IP地址及设置自动获取IP </pre><pre name="code" class="csharp">1.添加引用&q ...
- eclipse 插件编写(四)
前言 前面几篇文章讲了下如果编写简单的eclipse插件,如创建插件项目.编写右键弹出菜单等功能,接下来主要写一下如何生成代码的功能,这一片的功能跟插件本身的编写关联不太大,主要处理插件之后的业务内容 ...
- Windows 10预装应用太多?一个命令删除!
Windows 10预装了很多应用软件,虽然有些其实也不难用,但是使用率可能比较低,很多人也不喜欢预装的东西,而且还占空间,那么这些预装的如何彻底清除呢? 其实微软是自带了命令可以执行这样的操作,用它 ...
- 毕设(五)ListView
ListView 控件可使用四种不同视图显示项目.通过此控件,可将项目组成带有或不带有列标头的列,并显示伴随的图标和文本. 可使用 ListView 控件将称作 ListItem 对象的列表条目组织成 ...