存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言
随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择。相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此同时,对象存储对海量文件的写性能也会差很多。
腾讯云弹性 MapReduce(EMR) 是腾讯云的一个云端托管的弹性开源泛 Hadoop 服务,支持 Spark、Hbase、Presto、Flink、Druid 等大数据框架。
近期,在支持一位 EMR 客户时,遇到典型的存储计算分离应用场景。客户使用了 EMR 中的 Spark 组件作为计算引擎,数据存储在对象存储上。在帮助客户技术调优过程中,发现了 Spark 在海量文件场景下写入性能比较低,影响了架构的整体性能表现。
在深入分析和优化后,我们最终将写入性能大幅提升,特别是将写入对象存储的性能提升了 10 倍以上,加速了业务处理,获得了客户好评。
本篇文章将介绍在存储计算分离架构中,腾讯云 EMR Spark 计算引擎如何提升在海量文件场景下的写性能,希望与大家一同交流。文章作者:钟德艮,腾讯后台开发工程师。
一、问题背景
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,可用来构建大型的、低延迟的数据分析应用程序。Spark 是 UC Berkeley AMP lab (加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行框架,Spark 拥有 Hadoop MapReduce 所具有的优点。
与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行,也可以运行在云存储之上。
在这次技术调优过程中,我们研究的计算引擎是 EMR 产品中的 Spark 组件,由于其优异的性能等优点,也成为越来越多的客户在大数据计算引擎的选择。
存储上,客户选择的是对象存储。在数据存储方面,对象存储拥有可靠,可扩展和更低成本等特性,相比 Hadoop 文件系统 HDFS,是更优的低成本存储方式。海量的温冷数据更适合放到对象存储上,以降低成本。
在 Hadoop 的生态中,原生的 HDFS 存储也是很多场景下必不可少的存储选择,所以我们也在下文加入了与 HDFS 的存储性能对比。
回到我们想解决的问题中来,先来看一组测试数据,基于 Spark-2.x 引擎,使用 SparkSQL 分别对 HDFS、对象存储写入 5000 文件,分别统计执行时长:
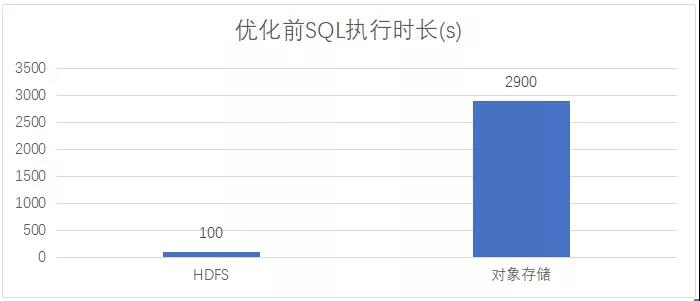
从测试结果可以看出,写入对象存储耗时是写入 HDFS 的 29 倍,写入对象存储的性能要比写入 HDFS 要差很多。而我们观察数据写入过程,发现网络 IO 并不是瓶颈,所以需要深入剖析一下计算引擎数据输出的具体过程。
二、Spark数据输出过程剖析
1. Spark数据流
先通过下图理解一下 Spark 作业执行过程中数据流转的主要过程:
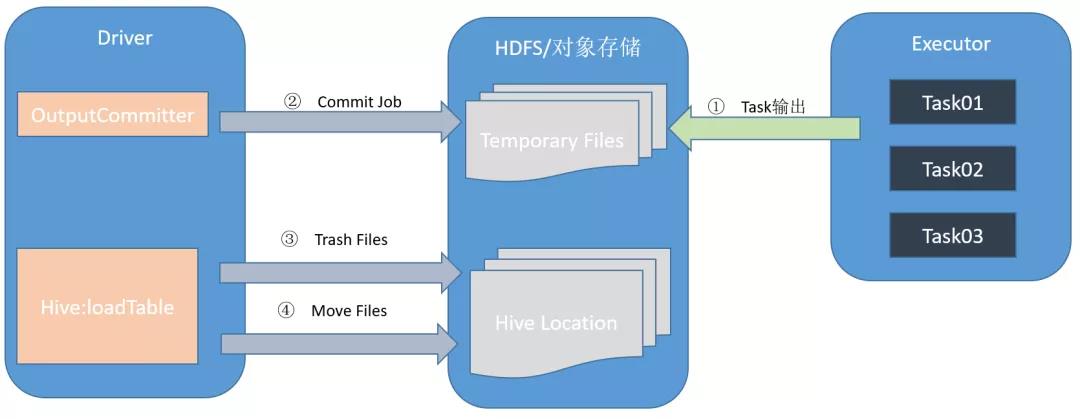
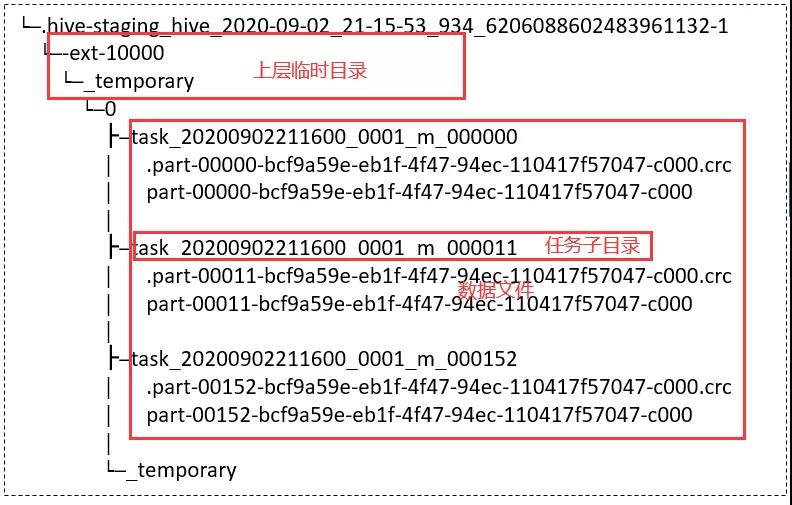
首先,每个 task 会将结果数据写入底层文件系统的临时目录 _temporary/task_[id],目录结果示意图如下所示:
到此为止,executor 上的 task 工作其实已经结束,接下来将交由 driver,将这些结果数据文件 move 到 hive 表最终所在的 location 目录下,共分三步操作:
第一步,调用 OutputCommiter 的 commitJob 方法做临时文件的转存和合并:

通过上面示意图可以看到,commitJob 会将 task_[id] 子目录下的所有数据文件 merge 到了上层目录 ext-10000。
接下来如果是 overwrite 覆盖写数据模式,会先将表或分区中已有的数据移动到 trash 回收站。
在完成上述操作后,会将第一步中合并好的数据文件,move 到 hive 表的 location,到此为止,所有数据操作完成。
2. 定位分析根因
有了上面对 Spark 数据流的分析,现在需要定位性能瓶颈在 driver 端还是 executor 端?观察作业在 executor 上的耗时:


发现作业在 executor 端执行时长差异不大,而总耗时却差异却非常大, 这说明作业主要耗时在 driver 端。
在 driver 端有 commitJob、trashFiles、moveFiles 三个操作阶段,具体是在 driver 的哪些阶段耗时比较长呢?
我们通过 spark-ui 观察 Thread dump (这里通过手动刷新 spark-ui 或者登录 driver 节点使用 jstack 命令查看线程堆栈信息),发现这三个阶段都比较慢, 下面我们来分析这三部分的源码。
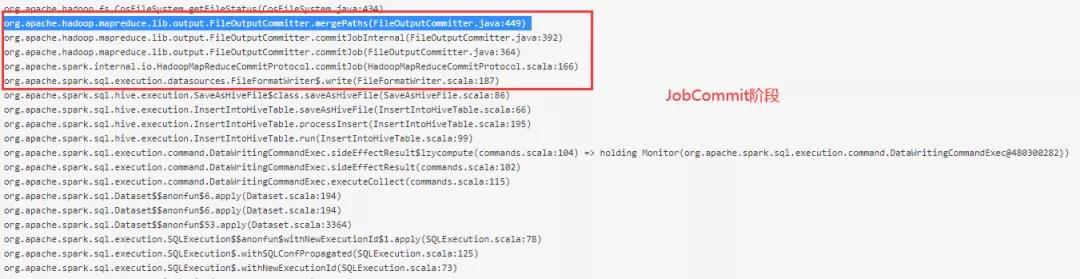
3. 源码分析
(1)JobCommit阶段
Spark 使用的是 Hadoop 的 FileOutputCommitter 来处理文件合并操作, Hadoop 2.x 默认使用 mapreduce.fileoutputcommitter.algorithm.version=1,使用单线程 for 循环去遍历所有 task 子目录,然后做 merge path 操作,显然在输出文件很多情况下,这部分操作会非常耗时。
特别是对对象存储来说,rename 操作并不仅仅是修改元数据,还需要去 copy 数据到新文件。
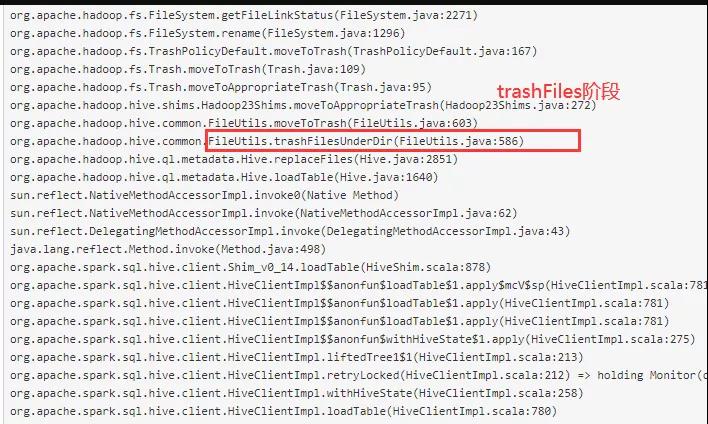
(2)TrashFiles阶段
trashFiles 操作是单线程 for 循环来将文件 move 到文件回收站,如果需要被覆盖写的数据比较多,这步操作会非常慢。
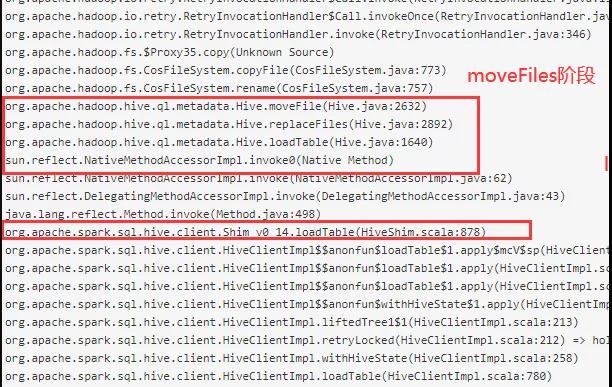
(3)MoveFiles阶段
与前面问题类似,在 moveFiles 阶段也是采用了单线程 for 循环方式来 move 文件。
4. 问题小结
Spark 引擎写海量文件性能瓶颈在Driver端;
在 Driver 的 CommitJob、TrashFiles、MoveFiles 三个阶段执行耗时都比较长;
三个阶段耗时长的原因都是因为单线程循环挨个处理文件;
对象存储的 rename 性能需要拷贝数据,性能较差,导致写海量文件时耗时特别长。
三、优化结果
可以看到社区版本大数据计算引擎在处理对象存储的访问上还在一定的性能问题,主要原因是大多数数据平台都是基于 HDFS 存储,而 HDFS 对文件的 rename 只需要在 namenode 上修改元数据,这个操作是非常快的,不容易碰到性能瓶颈。
而目前数据上云、存算分离是企业降低成本的重要考量,所以我们分别尝试将 commitJob、trashFiles、moveFile 代码修改成多线程并行处理文件,提升对文件写操作性能。
基于同样的基准测试,使用 SparkSQL 分别对 HDFS、对象存储写入 5000 个文件,我们得到了优化后的结果如下图所示:
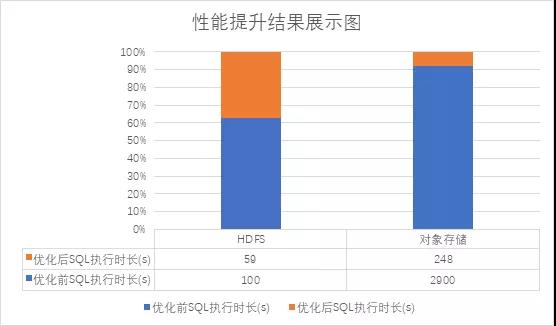
最终写 HDFS 性能提升 41%,写对象存储性能提升 1100% !
四、结语
从上述的分析过程看到,问题的关键是 Spark 引擎某些处理部分的单线程限制造成的。单线程限制其实是比较常见的技术瓶颈。虽然我们在一开始也有猜测这种可能性,但具体限制在哪一部分还需要理清思路,踏实的查看源代码和多次调试。
另外分析中也发现了对象存储自身的限制,其 rename 性能需要拷贝数据,导致写海量文件耗时长,我们也还在持续进行改进。
对存储计算分离应用场景深入优化,提升性能,更好的满足客户对存储计算分离场景下降本增效的需求,是我们腾讯云弹性 MapReduce(EMR) 产品研发团队近期的重要目标,欢迎大家一起交流探讨相关问题。
存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?的更多相关文章
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- Elasticsearch Reindex性能提升10倍+实战
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484134&idx=1&sn=750249a ...
- 一次 Spark SQL 性能提升10倍的经历(转载)
1. 遇到了啥问题 是酱紫的,简单来说:并发执行 spark job 的时候,并发的提速很不明显. 嗯,且听我慢慢道来,啰嗦点说,类似于我们内部有一个系统给分析师用,他们写一些 sql,在我们的 sp ...
- 如何把 MySQL 备份验证性能提升 10 倍
JuiceFS 非常适合用来做 MySQL 物理备份,具体使用参考我们的官方文档.最近有个客户在测试时反馈,备份验证的数据准备(xtrabackup --prepare)过程非常慢.我们借助 Juic ...
- Nacos 2.0 正式发布,性能提升 10 倍!!
3月20号,Nacos 2.0.0 正式发布了! Nacos 简介: 一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 通俗点讲,Nacos 就是一把微服务双刃剑:注册中心 + 配置中 ...
- 八年技术加持,性能提升10倍,阿里云HBase 2.0首发商用
摘要: 早在2010年开始,阿里巴巴集团开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储,HBase在几代阿里专家的不懈努力下,已经表现得运行更稳定.性能更高效 ...
- 如何把Go调用C的性能提升10倍?
目前,当Go需要和C/C++代码集成的时候,大家最先想到的肯定是CGO.毕竟是官方的解决方案,而且简单. 但是CGO是非常慢的.因为CGO其实一个桥接器,通过自动生成代码,CGO在保留了C/C++运行 ...
- Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)
我们兴奋的宣布Databricks缓存的通用可用性,作为统一分析平台一部分的 Databricks 运行时特性,它可以将Spark工作负载的扫描速度提升10倍,并且这种改变无需任何代码修改. 1.在本 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
随机推荐
- Centos-挂载和卸载分区-mount
mount 挂载和卸载指定的分区 相关选项 -a 加载文件 /etc/fstab中指定的所有设备 -n 不降加载信息记录在 /etc/mtab文件中 -r 只读方式加载设备 -w 可读可写价值设备 ...
- Effective C++ 读书笔记 名博客
https://www.cnblogs.com/harlanc/tag/effective%20c%2B%2B/default.html?page=3
- Java知识系统回顾整理01基础06数组02初始化数组
一.分配空间与赋值分步进行 分配空间与赋值分步进行 public class HelloWorld { public static void main(String[] args) { int[] a ...
- const放在函数前后的区别
转载:const放在函数前后的区别 一.const修饰指针 int b = 500; 1.const int * a = & b; 2.int const * a = & b; 3.i ...
- layui+tp5表单提交回调
layui 前段页面form表单提交数据如果监听表单提交 ,tp5后台操作完成后使用 $this->success('success'); 后前端的页面不会出现layui的layer弹窗提示su ...
- ubuntu 19.10 中防火墙iptables配置
$sudo which iptables /usr/sbin/iptables说明有安装 如果没有安装,那么使用sudo apt-get install iptables 安装. 刚装机,是这个样 ...
- 多测试_mysql数据库_09
什么是数据库? 是存放数据的电子仓库.以某种方式存储百万条,上亿条数据,供多个用户访问共享. 每个数据库都有一个或多个不同的api用于创建.访问,管理和复制所保存的数据. 数据库分关系型数据库和非关系 ...
- python程序整理(1)
''' 用户登录验证 要求: 1. 系统⾃动⽣成4位随机数. 作为登录验证码. 直接用就好. 这里不用纠结 提示. 生成随机数的办法. from random import randint num = ...
- ES6的7个实用技巧
Hack #1 交换元素 利用数组解构来实现值的互换 let a = 'world', b = 'hello' [a, b] = [b, a] console.log(a) // -> hell ...
- 【图论】USACO07NOV Cow Relays G
题目大意 洛谷链接 给定一张\(T\)条边的无向连通图,求从\(S\)到\(E\)经过\(N\)条边的最短路长度. 输入格式 第一行四个正整数\(N,T,S,E\),意义如题面所示. 接下来\(T\) ...